Compare commits
91 Commits
v4.9.0-alp
...
v4.9.2-alp
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e6efd3318d | ||
|
|
95ffd710aa | ||
|
|
097bb97417 | ||
|
|
4faea8d2b8 | ||
|
|
7ecadb33d1 | ||
|
|
ce61bda223 | ||
|
|
8dba01da73 | ||
|
|
dcdad6fa39 | ||
|
|
11d080d521 | ||
|
|
2f954d2f3f | ||
|
|
a956fbca73 | ||
|
|
db7510c5eb | ||
|
|
b87cc353da | ||
|
|
ff85121546 | ||
|
|
79f9d83349 | ||
|
|
159bf17369 | ||
|
|
4512b23d4d | ||
|
|
5300ddf654 | ||
|
|
f1f0dfc691 | ||
|
|
e5acec8dc7 | ||
|
|
cb832b6305 | ||
|
|
ae9b8a2b8e | ||
|
|
d209255015 | ||
|
|
6eae841e4a | ||
|
|
75c1631670 | ||
|
|
97a182c7fd | ||
|
|
a0ad450032 | ||
|
|
74b36219e1 | ||
|
|
fc23db745c | ||
|
|
8a68de6471 | ||
|
|
1c4e0c66d5 | ||
|
|
6dcdd540b9 | ||
|
|
48233c7d55 | ||
|
|
f3ef56998d | ||
|
|
7e7269b2ba | ||
|
|
606e9505c0 | ||
|
|
1db39e8907 | ||
|
|
7f13eb4642 | ||
|
|
9a1fff74fd | ||
|
|
de87639fce | ||
|
|
f9cecfd49a | ||
|
|
70563d2bcb | ||
|
|
4ca99a6361 | ||
|
|
8f70e436cf | ||
|
|
e75d81d05a | ||
|
|
56793114d8 | ||
|
|
a7b09461be | ||
|
|
cd2cb3f6ea | ||
|
|
56f77b58c9 | ||
|
|
1d697f97d7 | ||
|
|
bb30ca4859 | ||
|
|
139e934345 | ||
|
|
bf69aa6e3d | ||
|
|
3a730a23cb | ||
|
|
75cb46796a | ||
|
|
effdb5884b | ||
|
|
9523ba92f3 | ||
|
|
2f522aff90 | ||
|
|
0dccfd176d | ||
|
|
867e8acf27 | ||
|
|
36da8c862f | ||
|
|
b50cf49cc7 | ||
|
|
2270e149eb | ||
|
|
4957bdcba1 | ||
|
|
bca5cf738a | ||
|
|
c35bb5841c | ||
|
|
6e045093b1 | ||
|
|
a1b114e426 | ||
|
|
54fde7630c | ||
|
|
467c408ad7 | ||
|
|
c005a94454 | ||
|
|
c8a35822d6 | ||
|
|
d05259dedd | ||
|
|
8980664b8a | ||
|
|
43f30b3790 | ||
|
|
3ddbb37612 | ||
|
|
7c419a26b3 | ||
|
|
e131465d25 | ||
|
|
a345e56508 | ||
|
|
32ce032995 | ||
|
|
0bc075aa4e | ||
|
|
3e3f2165db | ||
|
|
e1aa068858 | ||
|
|
e98d6f1d30 | ||
|
|
54eb5c0547 | ||
|
|
adf5377ebe | ||
|
|
08b6f594df | ||
|
|
90d13ee3df | ||
|
|
5c718abd50 | ||
|
|
2d351c3654 | ||
|
|
662a4a4671 |
2
.github/workflows/docs-deploy-kubeconfig.yml
vendored
@@ -6,8 +6,6 @@ on:
|
|||||||
- 'docSite/**'
|
- 'docSite/**'
|
||||||
branches:
|
branches:
|
||||||
- 'main'
|
- 'main'
|
||||||
tags:
|
|
||||||
- 'v*.*.*'
|
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
build-fastgpt-docs-images:
|
build-fastgpt-docs-images:
|
||||||
|
|||||||
2
.github/workflows/docs-deploy-vercel.yml
vendored
@@ -7,8 +7,6 @@ on:
|
|||||||
- 'docSite/**'
|
- 'docSite/**'
|
||||||
branches:
|
branches:
|
||||||
- 'main'
|
- 'main'
|
||||||
tags:
|
|
||||||
- 'v*.*.*'
|
|
||||||
|
|
||||||
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
|
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
|
||||||
jobs:
|
jobs:
|
||||||
|
|||||||
2
.github/workflows/docs-preview.yml
vendored
@@ -4,8 +4,6 @@ on:
|
|||||||
pull_request_target:
|
pull_request_target:
|
||||||
paths:
|
paths:
|
||||||
- 'docSite/**'
|
- 'docSite/**'
|
||||||
branches:
|
|
||||||
- 'main'
|
|
||||||
workflow_dispatch:
|
workflow_dispatch:
|
||||||
|
|
||||||
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
|
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
|
||||||
|
|||||||
3
.github/workflows/fastgpt-preview-image.yml
vendored
@@ -1,9 +1,6 @@
|
|||||||
name: Preview FastGPT images
|
name: Preview FastGPT images
|
||||||
on:
|
on:
|
||||||
pull_request_target:
|
pull_request_target:
|
||||||
paths:
|
|
||||||
- 'projects/app/**'
|
|
||||||
- 'packages/**'
|
|
||||||
workflow_dispatch:
|
workflow_dispatch:
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
|
|||||||
29
.github/workflows/fastgpt-test.yaml
vendored
Normal file
@@ -0,0 +1,29 @@
|
|||||||
|
name: 'FastGPT-Test'
|
||||||
|
on:
|
||||||
|
pull_request:
|
||||||
|
workflow_dispatch:
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
test:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
|
||||||
|
permissions:
|
||||||
|
# Required to checkout the code
|
||||||
|
contents: read
|
||||||
|
# Required to put a comment into the pull-request
|
||||||
|
pull-requests: write
|
||||||
|
|
||||||
|
steps:
|
||||||
|
- uses: actions/checkout@v4
|
||||||
|
- uses: pnpm/action-setup@v4
|
||||||
|
with:
|
||||||
|
version: 10
|
||||||
|
- name: 'Install Deps'
|
||||||
|
run: pnpm install
|
||||||
|
- name: 'Test'
|
||||||
|
run: pnpm run test
|
||||||
|
- name: 'Report Coverage'
|
||||||
|
# Set if: always() to also generate the report if tests are failing
|
||||||
|
# Only works if you set `reportOnFailure: true` in your vite config as specified above
|
||||||
|
if: always()
|
||||||
|
uses: davelosert/vitest-coverage-report-action@v2
|
||||||
1
.gitignore
vendored
@@ -44,3 +44,4 @@ files/helm/fastgpt/fastgpt-0.1.0.tgz
|
|||||||
files/helm/fastgpt/charts/*.tgz
|
files/helm/fastgpt/charts/*.tgz
|
||||||
|
|
||||||
tmp/
|
tmp/
|
||||||
|
coverage
|
||||||
|
|||||||
@@ -5,4 +5,6 @@ node_modules
|
|||||||
docSite/
|
docSite/
|
||||||
*.md
|
*.md
|
||||||
|
|
||||||
cl100l_base.ts
|
pnpm-lock.yaml
|
||||||
|
cl100l_base.ts
|
||||||
|
dict.json
|
||||||
7
.vscode/i18n-ally-custom-framework.yml
vendored
@@ -17,15 +17,8 @@ usageMatchRegex:
|
|||||||
# you can ignore it and use your own matching rules as well
|
# you can ignore it and use your own matching rules as well
|
||||||
- "[^\\w\\d]t\\(['\"`]({key})['\"`]"
|
- "[^\\w\\d]t\\(['\"`]({key})['\"`]"
|
||||||
- "[^\\w\\d]commonT\\(['\"`]({key})['\"`]"
|
- "[^\\w\\d]commonT\\(['\"`]({key})['\"`]"
|
||||||
# 支持 appT("your.i18n.keys")
|
|
||||||
- "[^\\w\\d]appT\\(['\"`]({key})['\"`]"
|
|
||||||
# 支持 datasetT("your.i18n.keys")
|
|
||||||
- "[^\\w\\d]datasetT\\(['\"`]({key})['\"`]"
|
|
||||||
- "[^\\w\\d]fileT\\(['\"`]({key})['\"`]"
|
- "[^\\w\\d]fileT\\(['\"`]({key})['\"`]"
|
||||||
- "[^\\w\\d]publishT\\(['\"`]({key})['\"`]"
|
|
||||||
- "[^\\w\\d]workflowT\\(['\"`]({key})['\"`]"
|
- "[^\\w\\d]workflowT\\(['\"`]({key})['\"`]"
|
||||||
- "[^\\w\\d]userT\\(['\"`]({key})['\"`]"
|
|
||||||
- "[^\\w\\d]chatT\\(['\"`]({key})['\"`]"
|
|
||||||
- "[^\\w\\d]i18nT\\(['\"`]({key})['\"`]"
|
- "[^\\w\\d]i18nT\\(['\"`]({key})['\"`]"
|
||||||
|
|
||||||
# A RegEx to set a custom scope range. This scope will be used as a prefix when detecting keys
|
# A RegEx to set a custom scope range. This scope will be used as a prefix when detecting keys
|
||||||
|
|||||||
@@ -129,7 +129,8 @@ https://github.com/labring/FastGPT/assets/15308462/7d3a38df-eb0e-4388-9250-2409b
|
|||||||
</a>
|
</a>
|
||||||
|
|
||||||
## 🌿 第三方生态
|
## 🌿 第三方生态
|
||||||
|
- [PPIO 派欧云:一键调用高性价比的开源模型 API 和 GPU 容器](https://ppinfra.com/user/register?invited_by=VITYVU&utm_source=github_fastgpt)
|
||||||
|
- [AI Proxy:国内模型聚合服务](https://sealos.run/aiproxy/?k=fastgpt-github/)
|
||||||
- [SiliconCloud (硅基流动) —— 开源模型在线体验平台](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
- [SiliconCloud (硅基流动) —— 开源模型在线体验平台](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
||||||
- [COW 个人微信/企微机器人](https://doc.tryfastgpt.ai/docs/use-cases/external-integration/onwechat/)
|
- [COW 个人微信/企微机器人](https://doc.tryfastgpt.ai/docs/use-cases/external-integration/onwechat/)
|
||||||
|
|
||||||
|
|||||||
@@ -69,7 +69,7 @@ Project tech stack: NextJs + TS + ChakraUI + MongoDB + PostgreSQL (PG Vector plu
|
|||||||
|
|
||||||
> When using [Sealos](https://sealos.io) services, there is no need to purchase servers or domain names. It supports high concurrency and dynamic scaling, and the database application uses the kubeblocks database, which far exceeds the simple Docker container deployment in terms of IO performance.
|
> When using [Sealos](https://sealos.io) services, there is no need to purchase servers or domain names. It supports high concurrency and dynamic scaling, and the database application uses the kubeblocks database, which far exceeds the simple Docker container deployment in terms of IO performance.
|
||||||
<div align="center">
|
<div align="center">
|
||||||
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt)
|
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt&uid=fnWRt09fZP)
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
Give it a 2-4 minute wait after deployment as it sets up the database. Initially, it might be a too slow since we're using the basic settings.
|
Give it a 2-4 minute wait after deployment as it sets up the database. Initially, it might be a too slow since we're using the basic settings.
|
||||||
|
|||||||
@@ -94,7 +94,7 @@ https://github.com/labring/FastGPT/assets/15308462/7d3a38df-eb0e-4388-9250-2409b
|
|||||||
|
|
||||||
- **⚡ デプロイ**
|
- **⚡ デプロイ**
|
||||||
|
|
||||||
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt)
|
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt&uid=fnWRt09fZP)
|
||||||
|
|
||||||
デプロイ 後、データベースをセットアップするので、2~4分待 ってください。基本設定 を 使 っているので、最初 は 少 し 遅 いかもしれません。
|
デプロイ 後、データベースをセットアップするので、2~4分待 ってください。基本設定 を 使 っているので、最初 は 少 し 遅 いかもしれません。
|
||||||
|
|
||||||
|
|||||||
@@ -100,7 +100,7 @@ services:
|
|||||||
exec docker-entrypoint.sh "$$@" &
|
exec docker-entrypoint.sh "$$@" &
|
||||||
|
|
||||||
# 等待MongoDB服务启动
|
# 等待MongoDB服务启动
|
||||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
|
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
|
||||||
echo "Waiting for MongoDB to start..."
|
echo "Waiting for MongoDB to start..."
|
||||||
sleep 2
|
sleep 2
|
||||||
done
|
done
|
||||||
@@ -114,15 +114,15 @@ services:
|
|||||||
# fastgpt
|
# fastgpt
|
||||||
sandbox:
|
sandbox:
|
||||||
container_name: sandbox
|
container_name: sandbox
|
||||||
image: ghcr.io/labring/fastgpt-sandbox:v4.8.23-fix # git
|
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.23-fix # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||||
networks:
|
networks:
|
||||||
- fastgpt
|
- fastgpt
|
||||||
restart: always
|
restart: always
|
||||||
fastgpt:
|
fastgpt:
|
||||||
container_name: fastgpt
|
container_name: fastgpt
|
||||||
image: ghcr.io/labring/fastgpt:v4.8.23-fix # git
|
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.23-fix # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||||
ports:
|
ports:
|
||||||
- 3000:3000
|
- 3000:3000
|
||||||
networks:
|
networks:
|
||||||
@@ -175,14 +175,13 @@ services:
|
|||||||
|
|
||||||
# AI Proxy
|
# AI Proxy
|
||||||
aiproxy:
|
aiproxy:
|
||||||
image: 'ghcr.io/labring/sealos-aiproxy-service:latest'
|
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||||
|
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||||
container_name: aiproxy
|
container_name: aiproxy
|
||||||
restart: unless-stopped
|
restart: unless-stopped
|
||||||
depends_on:
|
depends_on:
|
||||||
aiproxy_pg:
|
aiproxy_pg:
|
||||||
condition: service_healthy
|
condition: service_healthy
|
||||||
ports:
|
|
||||||
- '3002:3000'
|
|
||||||
networks:
|
networks:
|
||||||
- fastgpt
|
- fastgpt
|
||||||
environment:
|
environment:
|
||||||
@@ -193,7 +192,7 @@ services:
|
|||||||
# 数据库连接地址
|
# 数据库连接地址
|
||||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||||
# 最大重试次数
|
# 最大重试次数
|
||||||
- RetryTimes=3
|
- RETRY_TIMES=3
|
||||||
# 不需要计费
|
# 不需要计费
|
||||||
- BILLING_ENABLED=false
|
- BILLING_ENABLED=false
|
||||||
# 不需要严格检测模型
|
# 不需要严格检测模型
|
||||||
@@ -204,8 +203,8 @@ services:
|
|||||||
timeout: 5s
|
timeout: 5s
|
||||||
retries: 10
|
retries: 10
|
||||||
aiproxy_pg:
|
aiproxy_pg:
|
||||||
# image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||||
restart: unless-stopped
|
restart: unless-stopped
|
||||||
container_name: aiproxy_pg
|
container_name: aiproxy_pg
|
||||||
volumes:
|
volumes:
|
||||||
|
|||||||
@@ -28,8 +28,8 @@ services:
|
|||||||
# image: mongo:4.4.29 # cpu不支持AVX时候使用
|
# image: mongo:4.4.29 # cpu不支持AVX时候使用
|
||||||
container_name: mongo
|
container_name: mongo
|
||||||
restart: always
|
restart: always
|
||||||
ports:
|
# ports:
|
||||||
- 27017:27017
|
# - 27017:27017
|
||||||
networks:
|
networks:
|
||||||
- fastgpt
|
- fastgpt
|
||||||
command: mongod --keyFile /data/mongodb.key --replSet rs0
|
command: mongod --keyFile /data/mongodb.key --replSet rs0
|
||||||
@@ -58,7 +58,7 @@ services:
|
|||||||
exec docker-entrypoint.sh "$$@" &
|
exec docker-entrypoint.sh "$$@" &
|
||||||
|
|
||||||
# 等待MongoDB服务启动
|
# 等待MongoDB服务启动
|
||||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
|
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
|
||||||
echo "Waiting for MongoDB to start..."
|
echo "Waiting for MongoDB to start..."
|
||||||
sleep 2
|
sleep 2
|
||||||
done
|
done
|
||||||
@@ -72,15 +72,15 @@ services:
|
|||||||
# fastgpt
|
# fastgpt
|
||||||
sandbox:
|
sandbox:
|
||||||
container_name: sandbox
|
container_name: sandbox
|
||||||
image: ghcr.io/labring/fastgpt-sandbox:v4.8.23-fix # git
|
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.23-fix # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||||
networks:
|
networks:
|
||||||
- fastgpt
|
- fastgpt
|
||||||
restart: always
|
restart: always
|
||||||
fastgpt:
|
fastgpt:
|
||||||
container_name: fastgpt
|
container_name: fastgpt
|
||||||
image: ghcr.io/labring/fastgpt:v4.8.23-fix # git
|
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.23-fix # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||||
ports:
|
ports:
|
||||||
- 3000:3000
|
- 3000:3000
|
||||||
networks:
|
networks:
|
||||||
@@ -132,14 +132,13 @@ services:
|
|||||||
|
|
||||||
# AI Proxy
|
# AI Proxy
|
||||||
aiproxy:
|
aiproxy:
|
||||||
image: 'ghcr.io/labring/sealos-aiproxy-service:latest'
|
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||||
|
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||||
container_name: aiproxy
|
container_name: aiproxy
|
||||||
restart: unless-stopped
|
restart: unless-stopped
|
||||||
depends_on:
|
depends_on:
|
||||||
aiproxy_pg:
|
aiproxy_pg:
|
||||||
condition: service_healthy
|
condition: service_healthy
|
||||||
ports:
|
|
||||||
- '3002:3000'
|
|
||||||
networks:
|
networks:
|
||||||
- fastgpt
|
- fastgpt
|
||||||
environment:
|
environment:
|
||||||
@@ -150,7 +149,7 @@ services:
|
|||||||
# 数据库连接地址
|
# 数据库连接地址
|
||||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||||
# 最大重试次数
|
# 最大重试次数
|
||||||
- RetryTimes=3
|
- RETRY_TIMES=3
|
||||||
# 不需要计费
|
# 不需要计费
|
||||||
- BILLING_ENABLED=false
|
- BILLING_ENABLED=false
|
||||||
# 不需要严格检测模型
|
# 不需要严格检测模型
|
||||||
@@ -161,8 +160,8 @@ services:
|
|||||||
timeout: 5s
|
timeout: 5s
|
||||||
retries: 10
|
retries: 10
|
||||||
aiproxy_pg:
|
aiproxy_pg:
|
||||||
# image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||||
restart: unless-stopped
|
restart: unless-stopped
|
||||||
container_name: aiproxy_pg
|
container_name: aiproxy_pg
|
||||||
volumes:
|
volumes:
|
||||||
|
|||||||
@@ -41,7 +41,7 @@ services:
|
|||||||
exec docker-entrypoint.sh "$$@" &
|
exec docker-entrypoint.sh "$$@" &
|
||||||
|
|
||||||
# 等待MongoDB服务启动
|
# 等待MongoDB服务启动
|
||||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
|
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
|
||||||
echo "Waiting for MongoDB to start..."
|
echo "Waiting for MongoDB to start..."
|
||||||
sleep 2
|
sleep 2
|
||||||
done
|
done
|
||||||
@@ -53,15 +53,15 @@ services:
|
|||||||
wait $$!
|
wait $$!
|
||||||
sandbox:
|
sandbox:
|
||||||
container_name: sandbox
|
container_name: sandbox
|
||||||
image: ghcr.io/labring/fastgpt-sandbox:v4.8.23-fix # git
|
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.23-fix # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||||
networks:
|
networks:
|
||||||
- fastgpt
|
- fastgpt
|
||||||
restart: always
|
restart: always
|
||||||
fastgpt:
|
fastgpt:
|
||||||
container_name: fastgpt
|
container_name: fastgpt
|
||||||
image: ghcr.io/labring/fastgpt:v4.8.23-fix # git
|
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.23-fix # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||||
ports:
|
ports:
|
||||||
- 3000:3000
|
- 3000:3000
|
||||||
networks:
|
networks:
|
||||||
@@ -113,14 +113,13 @@ services:
|
|||||||
|
|
||||||
# AI Proxy
|
# AI Proxy
|
||||||
aiproxy:
|
aiproxy:
|
||||||
image: 'ghcr.io/labring/sealos-aiproxy-service:latest'
|
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||||
|
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||||
container_name: aiproxy
|
container_name: aiproxy
|
||||||
restart: unless-stopped
|
restart: unless-stopped
|
||||||
depends_on:
|
depends_on:
|
||||||
aiproxy_pg:
|
aiproxy_pg:
|
||||||
condition: service_healthy
|
condition: service_healthy
|
||||||
ports:
|
|
||||||
- '3002:3000'
|
|
||||||
networks:
|
networks:
|
||||||
- fastgpt
|
- fastgpt
|
||||||
environment:
|
environment:
|
||||||
@@ -131,7 +130,7 @@ services:
|
|||||||
# 数据库连接地址
|
# 数据库连接地址
|
||||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||||
# 最大重试次数
|
# 最大重试次数
|
||||||
- RetryTimes=3
|
- RETRY_TIMES=3
|
||||||
# 不需要计费
|
# 不需要计费
|
||||||
- BILLING_ENABLED=false
|
- BILLING_ENABLED=false
|
||||||
# 不需要严格检测模型
|
# 不需要严格检测模型
|
||||||
@@ -142,8 +141,8 @@ services:
|
|||||||
timeout: 5s
|
timeout: 5s
|
||||||
retries: 10
|
retries: 10
|
||||||
aiproxy_pg:
|
aiproxy_pg:
|
||||||
# image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||||
restart: unless-stopped
|
restart: unless-stopped
|
||||||
container_name: aiproxy_pg
|
container_name: aiproxy_pg
|
||||||
volumes:
|
volumes:
|
||||||
|
|||||||
BIN
docSite/assets/imgs/Ollama-aiproxy1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 68 KiB |
BIN
docSite/assets/imgs/Ollama-aiproxy2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 9.0 KiB |
BIN
docSite/assets/imgs/Ollama-aiproxy3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 179 KiB |
BIN
docSite/assets/imgs/Ollama-direct1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
BIN
docSite/assets/imgs/Ollama-models1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
docSite/assets/imgs/Ollama-models2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 138 KiB |
BIN
docSite/assets/imgs/Ollama-models3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 122 KiB |
BIN
docSite/assets/imgs/Ollama-models4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 124 KiB |
BIN
docSite/assets/imgs/Ollama-oneapi1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 94 KiB |
BIN
docSite/assets/imgs/Ollama-oneapi2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 57 KiB |
BIN
docSite/assets/imgs/Ollama-oneapi3 .png
Normal file
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
BIN
docSite/assets/imgs/Ollama-pull.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
{kind=link}
|
After Width: | Height: | Size: 170 KiB |
{kind=link}
|
After Width: | Height: | Size: 102 KiB |
{kind=link}
|
After Width: | Height: | Size: 70 KiB |
{kind=link}
|
After Width: | Height: | Size: 89 KiB |
{kind=link}
|
After Width: | Height: | Size: 87 KiB |
@@ -44,7 +44,7 @@ weight: 707
|
|||||||
|
|
||||||
#### 1. 申请 Sealos AI proxy API Key
|
#### 1. 申请 Sealos AI proxy API Key
|
||||||
|
|
||||||
[点击打开 Sealos Pdf parser 官网](https://cloud.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy),并进行对应 API Key 的申请。
|
[点击打开 Sealos Pdf parser 官网](https://hzh.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy),并进行对应 API Key 的申请。
|
||||||
|
|
||||||
#### 2. 修改 FastGPT 配置文件
|
#### 2. 修改 FastGPT 配置文件
|
||||||
|
|
||||||
|
|||||||
@@ -24,10 +24,9 @@ PDF 是一个相对复杂的文件格式,在 FastGPT 内置的 pdf 解析器
|
|||||||
这里介绍快速 Docker 安装的方法:
|
这里介绍快速 Docker 安装的方法:
|
||||||
|
|
||||||
```dockerfile
|
```dockerfile
|
||||||
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:latest
|
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
|
||||||
docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:latest
|
docker run --gpus all -itd -p 7231:7232 --name model_pdf_v2 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2. 添加 FastGPT 文件配置
|
### 2. 添加 FastGPT 文件配置
|
||||||
|
|
||||||
```json
|
```json
|
||||||
@@ -36,7 +35,7 @@ docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 crpi-h3snc261q1dosro
|
|||||||
"systemEnv": {
|
"systemEnv": {
|
||||||
xxx
|
xxx
|
||||||
"customPdfParse": {
|
"customPdfParse": {
|
||||||
"url": "http://xxxx.com/v1/parse/file", // 自定义 PDF 解析服务地址
|
"url": "http://xxxx.com/v2/parse/file", // 自定义 PDF 解析服务地址 marker v0.2
|
||||||
"key": "", // 自定义 PDF 解析服务密钥
|
"key": "", // 自定义 PDF 解析服务密钥
|
||||||
"doc2xKey": "", // doc2x 服务密钥
|
"doc2xKey": "", // doc2x 服务密钥
|
||||||
"price": 0 // PDF 解析服务价格
|
"price": 0 // PDF 解析服务价格
|
||||||
@@ -80,4 +79,25 @@ docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 crpi-h3snc261q1dosro
|
|||||||
|
|
||||||
上图是分块后的结果,下图是 pdf 原文。整体图片、公式、表格都可以提取出来,效果还是杠杠的。
|
上图是分块后的结果,下图是 pdf 原文。整体图片、公式、表格都可以提取出来,效果还是杠杠的。
|
||||||
|
|
||||||
不过要注意的是,[Marker](https://github.com/VikParuchuri/marker) 的协议是`GPL-3.0 license`,请在遵守协议的前提下使用。
|
不过要注意的是,[Marker](https://github.com/VikParuchuri/marker) 的协议是`GPL-3.0 license`,请在遵守协议的前提下使用。
|
||||||
|
|
||||||
|
## 旧版 Marker 使用方法
|
||||||
|
|
||||||
|
FastGPT V4.9.0 版本之前,可以用以下方式,试用 Marker 解析服务。
|
||||||
|
|
||||||
|
安装和运行 Marker 服务:
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
|
||||||
|
docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
|
||||||
|
```
|
||||||
|
|
||||||
|
并修改 FastGPT 环境变量:
|
||||||
|
|
||||||
|
```
|
||||||
|
CUSTOM_READ_FILE_URL=http://xxxx.com/v1/parse/file
|
||||||
|
CUSTOM_READ_FILE_EXTENSION=pdf
|
||||||
|
```
|
||||||
|
|
||||||
|
* CUSTOM_READ_FILE_URL - 自定义解析服务的地址, host改成解析服务的访问地址,path 不能变动。
|
||||||
|
* CUSTOM_READ_FILE_EXTENSION - 支持的文件后缀,多个文件类型,可用逗号隔开。
|
||||||
184
docSite/content/zh-cn/docs/development/custom-models/ollama.md
Normal file
@@ -0,0 +1,184 @@
|
|||||||
|
---
|
||||||
|
title: '使用 Ollama 接入本地模型 '
|
||||||
|
description: ' 采用 Ollama 部署自己的模型'
|
||||||
|
icon: 'api'
|
||||||
|
draft: false
|
||||||
|
toc: true
|
||||||
|
weight: 950
|
||||||
|
---
|
||||||
|
|
||||||
|
[Ollama](https://ollama.com/) 是一个开源的AI大模型部署工具,专注于简化大语言模型的部署和使用,支持一键下载和运行各种大模型。
|
||||||
|
|
||||||
|
## 安装 Ollama
|
||||||
|
|
||||||
|
Ollama 本身支持多种安装方式,但是推荐使用 Docker 拉取镜像部署。如果是个人设备上安装了 Ollama 后续需要解决如何让 Docker 中 FastGPT 容器访问宿主机 Ollama的问题,较为麻烦。
|
||||||
|
|
||||||
|
### Docker 安装(推荐)
|
||||||
|
|
||||||
|
你可以使用 Ollama 官方的 Docker 镜像来一键安装和启动 Ollama 服务(确保你的机器上已经安装了 Docker),命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker pull ollama/ollama
|
||||||
|
docker run --rm -d --name ollama -p 11434:11434 ollama/ollama
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你的 FastGPT 是在 Docker 中进行部署的,建议在拉取 Ollama 镜像时保证和 FastGPT 镜像处于同一网络,否则可能出现 FastGPT 无法访问的问题,命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker run --rm -d --name ollama --network (你的 Fastgpt 容器所在网络) -p 11434:11434 ollama/ollama
|
||||||
|
```
|
||||||
|
|
||||||
|
### 主机安装
|
||||||
|
|
||||||
|
如果你不想使用 Docker ,也可以采用主机安装,以下是主机安装的一些方式。
|
||||||
|
|
||||||
|
#### MacOS
|
||||||
|
|
||||||
|
如果你使用的是 macOS,且系统中已经安装了 Homebrew 包管理器,可通过以下命令来安装 Ollama:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
brew install ollama
|
||||||
|
ollama serve #安装完成后,使用该命令启动服务
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Linux
|
||||||
|
|
||||||
|
在 Linux 系统上,你可以借助包管理器来安装 Ollama。以 Ubuntu 为例,在终端执行以下命令:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl https://ollama.com/install.sh | sh #此命令会从官方网站下载并执行安装脚本。
|
||||||
|
ollama serve #安装完成后,同样启动服务
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Windows
|
||||||
|
|
||||||
|
在 Windows 系统中,你可以从 Ollama 官方网站 下载 Windows 版本的安装程序。下载完成后,运行安装程序,按照安装向导的提示完成安装。安装完成后,在命令提示符或 PowerShell 中启动服务:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
ollama serve #安装完成并启动服务后,你可以在浏览器中访问 http://localhost:11434 来验证 Ollama 是否安装成功。
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 补充说明
|
||||||
|
|
||||||
|
如果你是采用的主机应用 Ollama 而不是镜像,需要确保你的 Ollama 可以监听0.0.0.0。
|
||||||
|
|
||||||
|
##### 1. Linxu 系统
|
||||||
|
|
||||||
|
如果 Ollama 作为 systemd 服务运行,打开终端,编辑 Ollama 的 systemd 服务文件,使用命令sudo systemctl edit ollama.service,在[Service]部分添加Environment="OLLAMA_HOST=0.0.0.0"。保存并退出编辑器,然后执行sudo systemctl daemon - reload和sudo systemctl restart ollama使配置生效。
|
||||||
|
|
||||||
|
##### 2. MacOS 系统
|
||||||
|
|
||||||
|
打开终端,使用launchctl setenv ollama_host "0.0.0.0"命令设置环境变量,然后重启 Ollama 应用程序以使更改生效。
|
||||||
|
|
||||||
|
##### 3. Windows 系统
|
||||||
|
|
||||||
|
通过 “开始” 菜单或搜索栏打开 “编辑系统环境变量”,在 “系统属性” 窗口中点击 “环境变量”,在 “系统变量” 部分点击 “新建”,创建一个名为OLLAMA_HOST的变量,变量值设置为0.0.0.0,点击 “确定” 保存更改,最后从 “开始” 菜单重启 Ollama 应用程序。
|
||||||
|
|
||||||
|
### Ollama 拉取模型镜像
|
||||||
|
|
||||||
|
在安装后 Ollama 后,本地是没有模型镜像的,需要自己去拉取 Ollama 中的模型镜像。命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Docker 部署需要先进容器,命令为: docker exec -it < Ollama 容器名 > /bin/sh
|
||||||
|
ollama pull <模型名>
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
### 测试通信
|
||||||
|
|
||||||
|
在安装完成后,需要进行检测测试,首先进入 FastGPT 所在的容器,尝试访问自己的 Ollama ,命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker exec -it < FastGPT 所在的容器名 > /bin/sh
|
||||||
|
curl http://XXX.XXX.XXX.XXX:11434 #容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||||||
|
```
|
||||||
|
|
||||||
|
看到访问显示自己的 Ollama 服务以及启动,说明可以正常通信。
|
||||||
|
|
||||||
|
## 将 Ollama 接入 FastGPT
|
||||||
|
|
||||||
|
### 1. 查看 Ollama 所拥有的模型
|
||||||
|
|
||||||
|
首先采用下述命令查看 Ollama 中所拥有的模型,
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Docker 部署 Ollama,需要此命令 docker exec -it < Ollama 容器名 > /bin/sh
|
||||||
|
ollama ls
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 2. AI Proxy 接入
|
||||||
|
|
||||||
|
如果你采用的是 FastGPT 中的默认配置文件部署[这里](/docs/development/docker.md),即默认采用 AI Proxy 进行启动。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
以及在确保你的 FastGPT 可以直接访问 Ollama 容器的情况下,无法访问,参考上文[点此跳转](#安装-ollama)的安装过程,检测是不是主机不能监测0.0.0.0,或者容器不在同一个网络。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。详细参考[这里](/docs/development/modelConfig/intro.md)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
运行 FastGPT ,在页面中选择账号->模型提供商->模型渠道->新增渠道。之后,在渠道选择中选择 Ollama ,然后加入自己拉取的模型,填入代理地址,如果是容器中安装 Ollama ,代理地址为http://地址:端口,补充:容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 3. OneAPI 接入
|
||||||
|
|
||||||
|
如果你想使用 OneAPI ,首先需要拉取 OneAPI 镜像,然后将其在 FastGPT 容器的网络中运行。具体命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 拉取 oneAPI 镜像
|
||||||
|
docker pull intel/oneapi-hpckit
|
||||||
|
|
||||||
|
# 运行容器并指定自定义网络和容器名
|
||||||
|
docker run -it --network < FastGPT 网络 > --name 容器名 intel/oneapi-hpckit /bin/bash
|
||||||
|
```
|
||||||
|
|
||||||
|
进入 OneAPI 页面,添加新的渠道,类型选择 Ollama ,在模型中填入自己 Ollama 中的模型,需要保证添加的模型名称和 Ollama 中一致,再在下方填入自己的 Ollama 代理地址,默认http://地址:端口,不需要填写/v1。添加成功后在 OneAPI 进行渠道测试,测试成功则说明添加成功。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
渠道添加成功后,点击令牌,点击添加令牌,填写名称,修改配置。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,在 OPENAI_BASE_URL 中加入自己的 OneAPI 开放地址,默认是http://地址:端口/v1,v1必须填写。KEY 中填写自己在 OneAPI 的令牌。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
[直接跳转5](#5-模型添加和使用)添加模型,并使用。
|
||||||
|
|
||||||
|
### 4. 直接接入
|
||||||
|
|
||||||
|
如果你既不想使用 AI Proxy,也不想使用 OneAPI,也可以选择直接接入,修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,采用和 OneAPI 的类似配置。注释掉 AIProxy 相关代码,在OPENAI_BASE_URL中加入自己的 Ollama 开放地址,默认是http://地址:端口/v1,强调:v1必须填写。在KEY中随便填入,因为 Ollama 默认没有鉴权,如果开启鉴权,请自行填写。其他操作和在 OneAPI 中加入 Ollama 一致,只需在 FastGPT 中加入自己的模型即可使用。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
完成后[点击这里](#5-模型添加和使用)进行模型添加并使用。
|
||||||
|
|
||||||
|
### 5. 模型添加和使用
|
||||||
|
|
||||||
|
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 6. 补充
|
||||||
|
上述接入 Ollama 的代理地址中,主机安装 Ollama 的地址为“http://<主机IP>:<端口>”,容器部署 Ollama 地址为“http://<容器名>:<端口>”
|
||||||
@@ -56,7 +56,7 @@ weight: 707
|
|||||||
|
|
||||||
### zilliz cloud版本
|
### zilliz cloud版本
|
||||||
|
|
||||||
Milvus 的全托管服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
Zilliz Cloud 由 Milvus 原厂打造,是全托管的 SaaS 向量数据库服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||||||
|
|
||||||
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
|
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
|
||||||
|
|
||||||
|
|||||||
@@ -29,7 +29,7 @@ weight: 744
|
|||||||
|
|
||||||
{{% alert icon=" " context="info" %}}
|
{{% alert icon=" " context="info" %}}
|
||||||
- [SiliconCloud(硅基流动)](https://cloud.siliconflow.cn/i/TR9Ym0c4): 提供开源模型调用的平台。
|
- [SiliconCloud(硅基流动)](https://cloud.siliconflow.cn/i/TR9Ym0c4): 提供开源模型调用的平台。
|
||||||
- [Sealos AIProxy](https://cloud.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy): 提供国内各家模型代理,无需逐一申请 api。
|
- [Sealos AIProxy](https://hzh.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy): 提供国内各家模型代理,无需逐一申请 api。
|
||||||
{{% /alert %}}
|
{{% /alert %}}
|
||||||
|
|
||||||
在 OneAPI 配置好模型后,你就可以打开 FastGPT 页面,启用对应模型了。
|
在 OneAPI 配置好模型后,你就可以打开 FastGPT 页面,启用对应模型了。
|
||||||
|
|||||||
@@ -23,7 +23,7 @@ FastGPT 目前采用模型分离的部署方案,FastGPT 中只兼容 OpenAI
|
|||||||
### Sealos 版本
|
### Sealos 版本
|
||||||
|
|
||||||
* 北京区: [点击部署 OneAPI](https://hzh.sealos.run/?openapp=system-template%3FtemplateName%3Done-api)
|
* 北京区: [点击部署 OneAPI](https://hzh.sealos.run/?openapp=system-template%3FtemplateName%3Done-api)
|
||||||
* 新加坡区(可用 GPT) [点击部署 OneAPI](https://cloud.sealos.io/?openapp=system-template%3FtemplateName%3Done-api)
|
* 新加坡区(可用 GPT) [点击部署 OneAPI](https://cloud.sealos.io/?openapp=system-template%3FtemplateName%3Done-api&uid=fnWRt09fZP)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
100
docSite/content/zh-cn/docs/development/modelConfig/ppio.md
Normal file
@@ -0,0 +1,100 @@
|
|||||||
|
---
|
||||||
|
title: '通过 PPIO LLM API 接入模型'
|
||||||
|
description: '通过 PPIO LLM API 接入模型'
|
||||||
|
icon: 'api'
|
||||||
|
draft: false
|
||||||
|
toc: true
|
||||||
|
weight: 747
|
||||||
|
---
|
||||||
|
|
||||||
|
FastGPT 还可以通过 PPIO LLM API 接入模型。
|
||||||
|
{{% alert context="warning" %}}
|
||||||
|
以下内容搬运自 [FastGPT 接入 PPIO LLM API](https://ppinfra.com/docs/third-party/fastgpt-use),可能会有更新不及时的情况。
|
||||||
|
{{% /alert %}}
|
||||||
|
|
||||||
|
FastGPT 是一个将 AI 开发、部署和使用全流程简化为可视化操作的平台。它使开发者不需要深入研究算法,
|
||||||
|
用户也不需要掌握复杂技术,通过一站式服务将人工智能技术变成易于使用的工具。
|
||||||
|
|
||||||
|
PPIO 派欧云提供简单易用的 API 接口,让开发者能够轻松调用 DeepSeek 等模型。
|
||||||
|
|
||||||
|
- 对开发者:无需重构架构,3 个接口完成从文本生成到决策推理的全场景接入,像搭积木一样设计 AI 工作流;
|
||||||
|
- 对生态:自动适配从中小应用到企业级系统的资源需求,让智能随业务自然生长。
|
||||||
|
|
||||||
|
下方教程提供完整接入方案(含密钥配置),帮助您快速将 FastGPT 与 PPIO API 连接起来。
|
||||||
|
|
||||||
|
## 1. 配置前置条件
|
||||||
|
|
||||||
|
(1) 获取 API 接口地址
|
||||||
|
|
||||||
|
固定为: `https://api.ppinfra.com/v3/openai/chat/completions`。
|
||||||
|
|
||||||
|
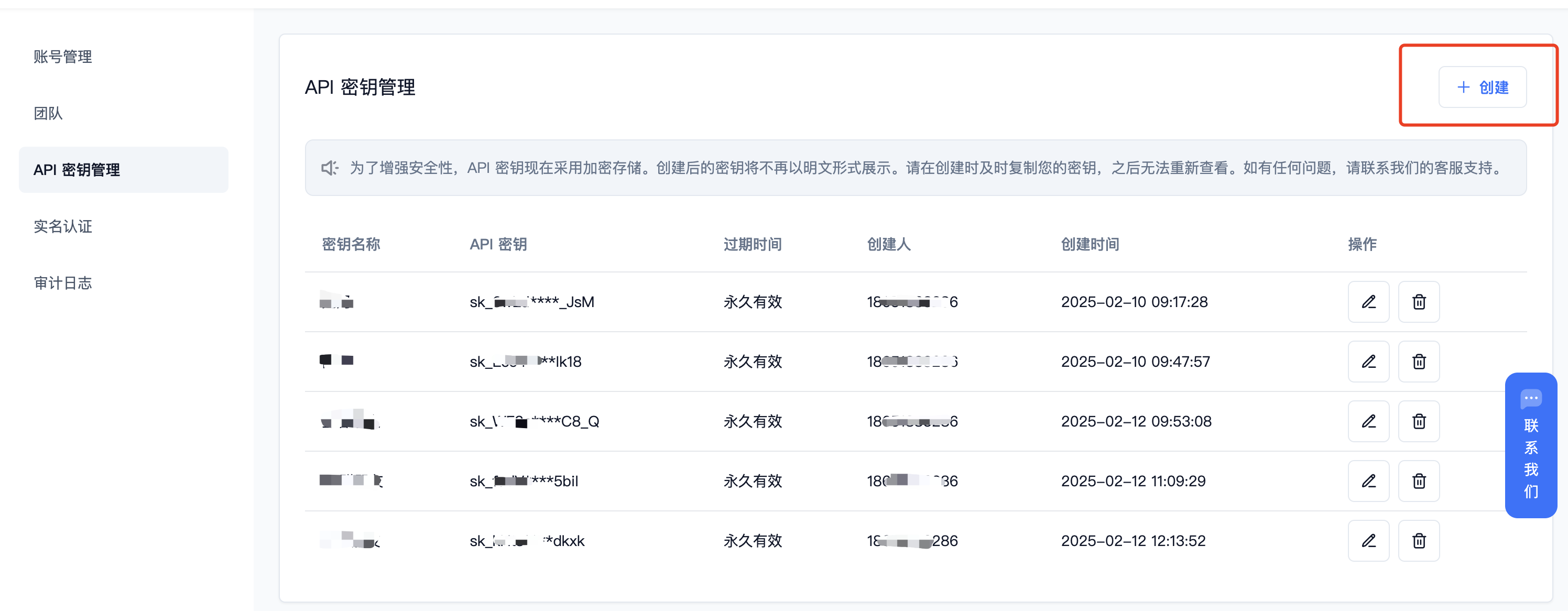
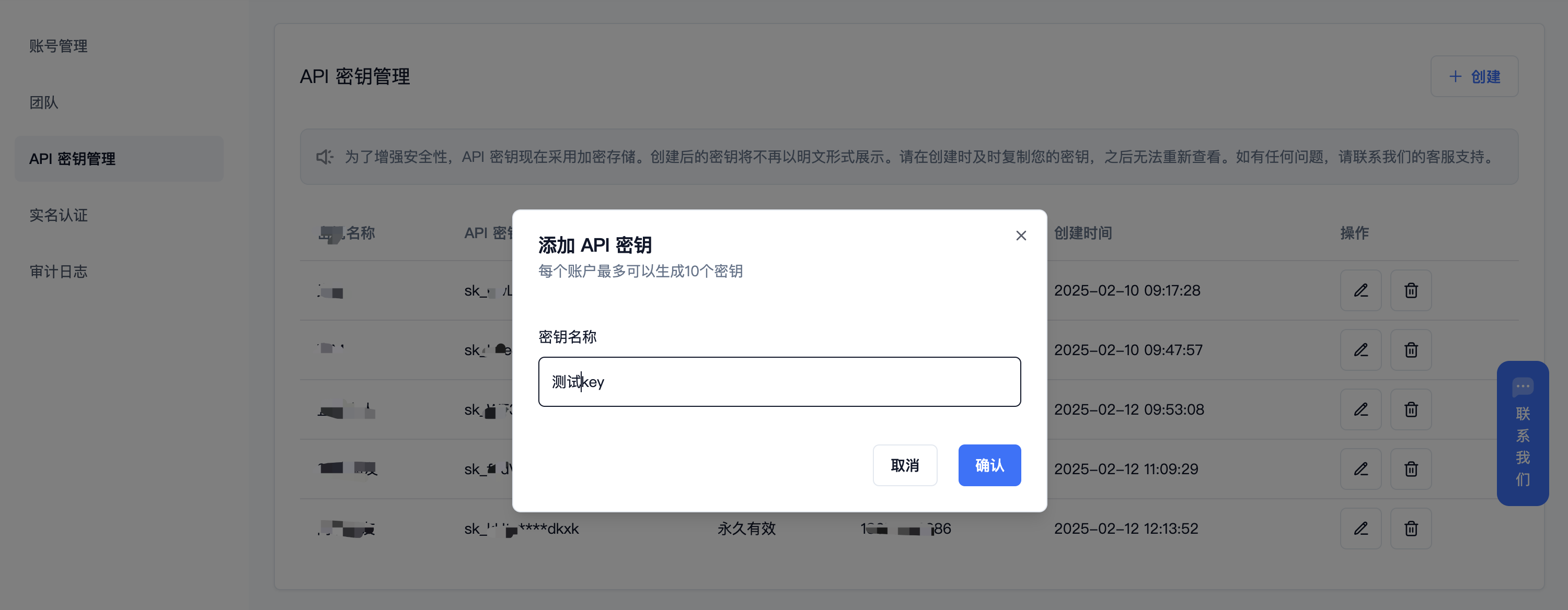
(2) 获取 【API 密钥】
|
||||||
|
|
||||||
|
登录派欧云控制台 [API 秘钥管理](https://www.ppinfra.com/settings/key-management) 页面,点击创建按钮。
|
||||||
|
注册账号填写邀请码【VOJL20】得 50 代金券
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
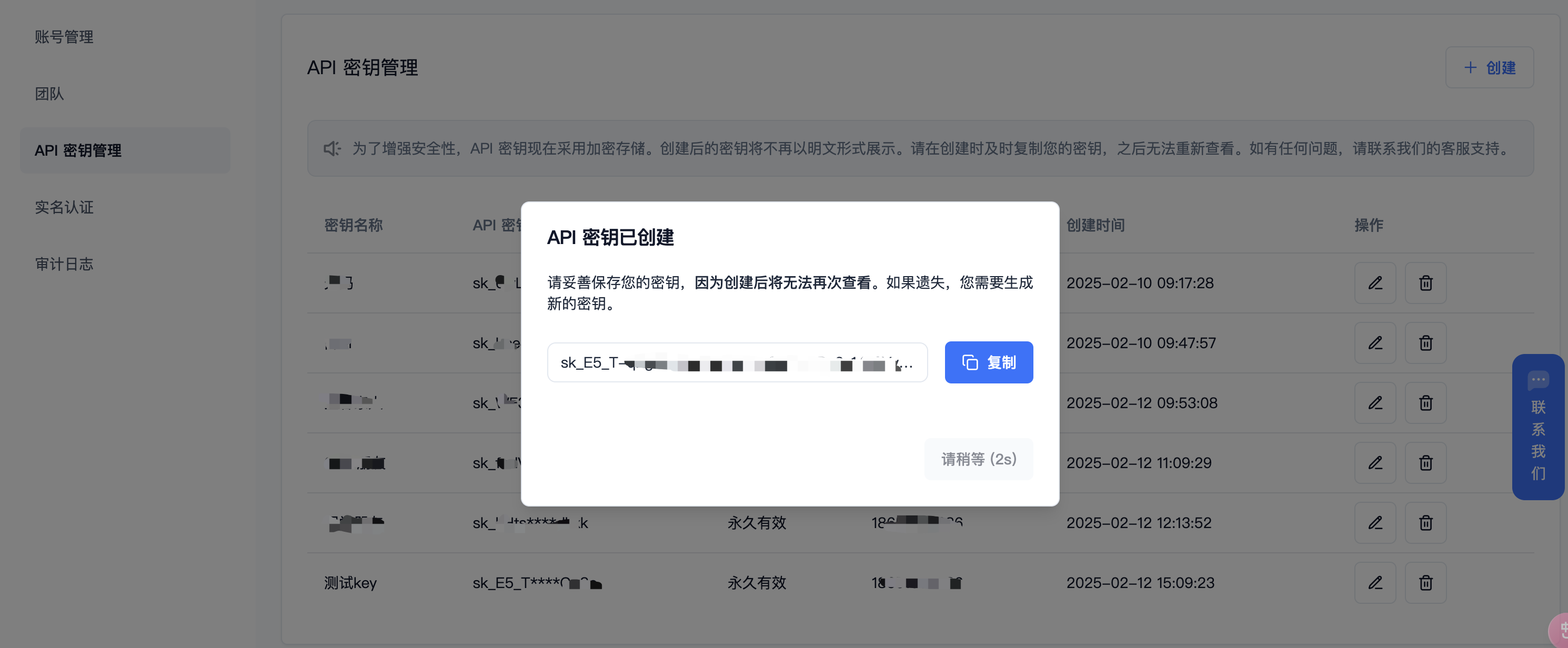
(3) 生成并保存 【API 密钥】
|
||||||
|
{{% alert context="warning" %}}
|
||||||
|
秘钥在服务端是加密存储,请在生成时保存好秘钥;若遗失可以在控制台上删除并创建一个新的秘钥。
|
||||||
|
{{% /alert %}}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
(4) 获取需要使用的模型 ID
|
||||||
|
|
||||||
|
deepseek 系列:
|
||||||
|
|
||||||
|
- DeepSeek R1:deepseek/deepseek-r1/community
|
||||||
|
|
||||||
|
- DeepSeek V3:deepseek/deepseek-v3/community
|
||||||
|
|
||||||
|
其他模型 ID、最大上下文及价格可参考:[模型列表](https://ppinfra.com/model-api/pricing)
|
||||||
|
|
||||||
|
## 2. 部署最新版 FastGPT 到本地环境
|
||||||
|
{{% alert context="warning" %}}
|
||||||
|
请使用 v4.8.22 以上版本,部署参考: https://doc.tryfastgpt.ai/docs/development/intro/
|
||||||
|
{{% /alert %}}
|
||||||
|
|
||||||
|
## 3. 模型配置(下面两种方式二选其一)
|
||||||
|
|
||||||
|
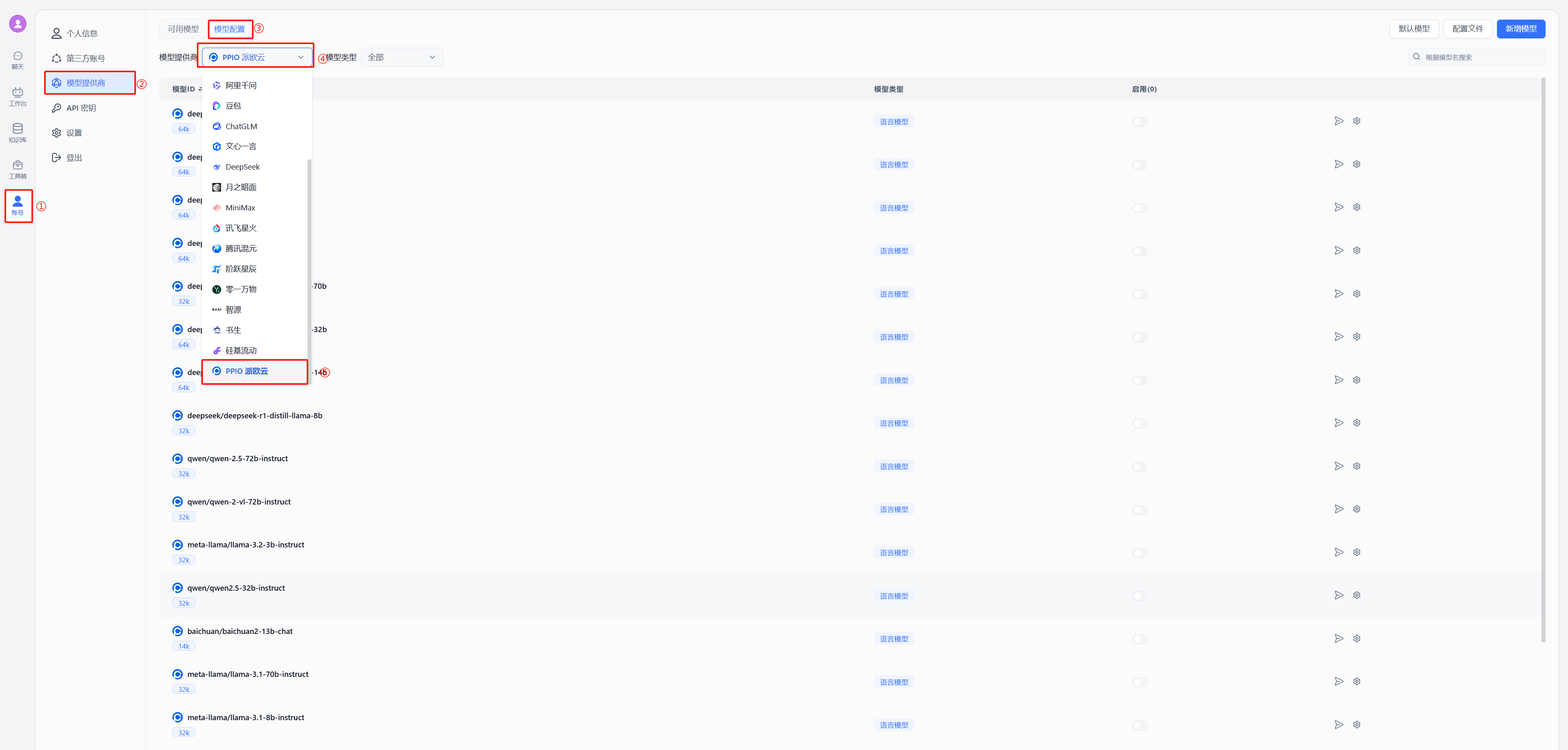
(1)通过 OneAPI 接入模型 PPIO 模型: 参考 OneAPI 使用文档,修改 FastGPT 的环境变量 在 One API 生成令牌后,FastGPT 可以通过修改 baseurl 和 key 去请求到 One API,再由 One API 去请求不同的模型。修改下面两个环境变量: 务必写上 v1。如果在同一个网络内,可改成内网地址。
|
||||||
|
|
||||||
|
OPENAI_BASE_URL= http://OneAPI-IP:OneAPI-PORT/v1
|
||||||
|
|
||||||
|
下面的 key 是由 One API 提供的令牌 CHAT_API_KEY=sk-UyVQcpQWMU7ChTVl74B562C28e3c46Fe8f16E6D8AeF8736e
|
||||||
|
|
||||||
|
- 修改后重启 FastGPT,按下图在模型提供商中选择派欧云
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
- 测试连通性
|
||||||
|
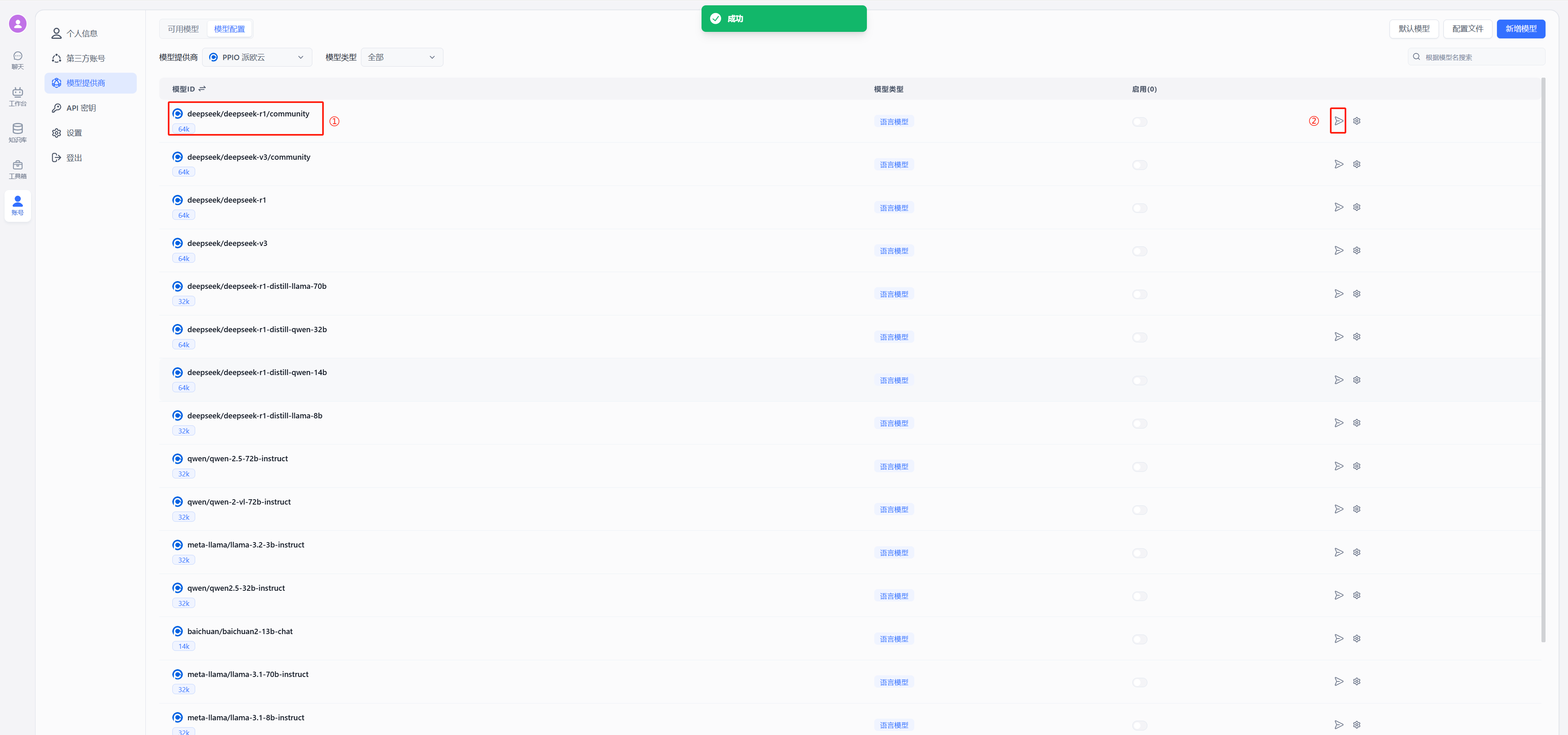
以 deepseek 为例,在模型中选择使用 deepseek/deepseek-r1/community,点击图中②的位置进行连通性测试,出现图中绿色的的成功显示证明连通成功,可以进行后续的配置对话了
|
||||||
|
|
||||||
|
|
||||||
|
(2)不使用 OneAPI 接入 PPIO 模型
|
||||||
|
|
||||||
|
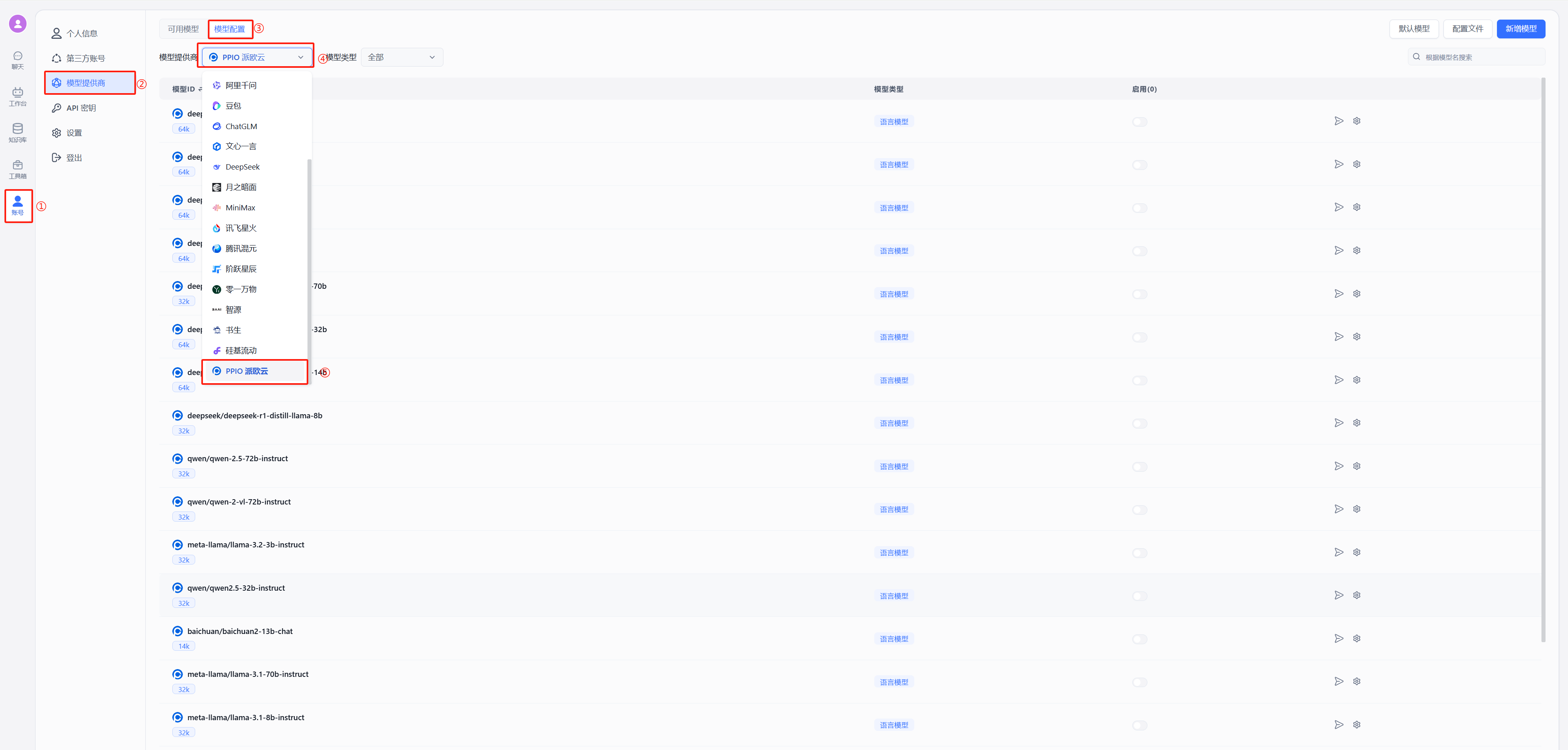
按照下图在模型提供商中选择派欧云
|
||||||
|
|
||||||
|
|
||||||
|
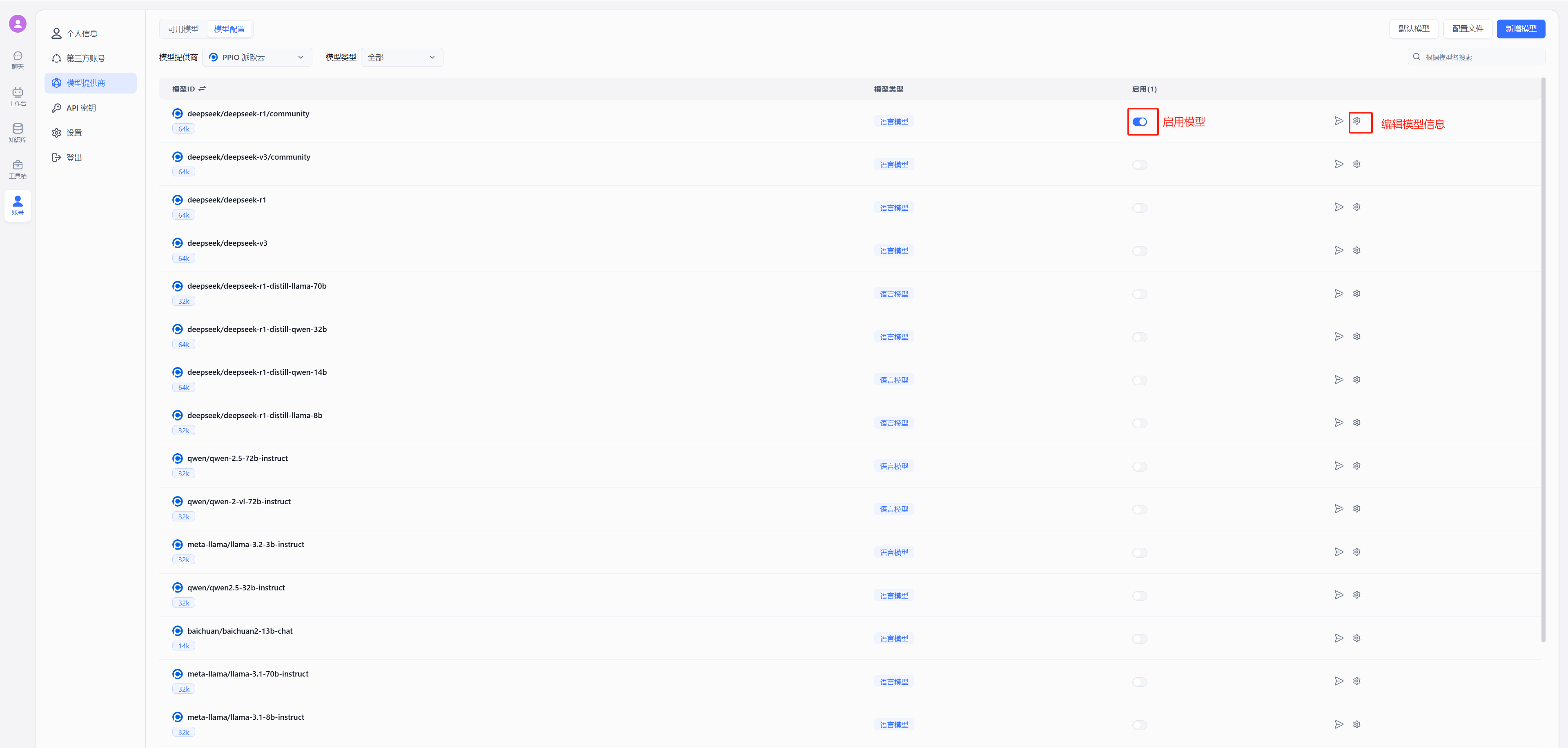
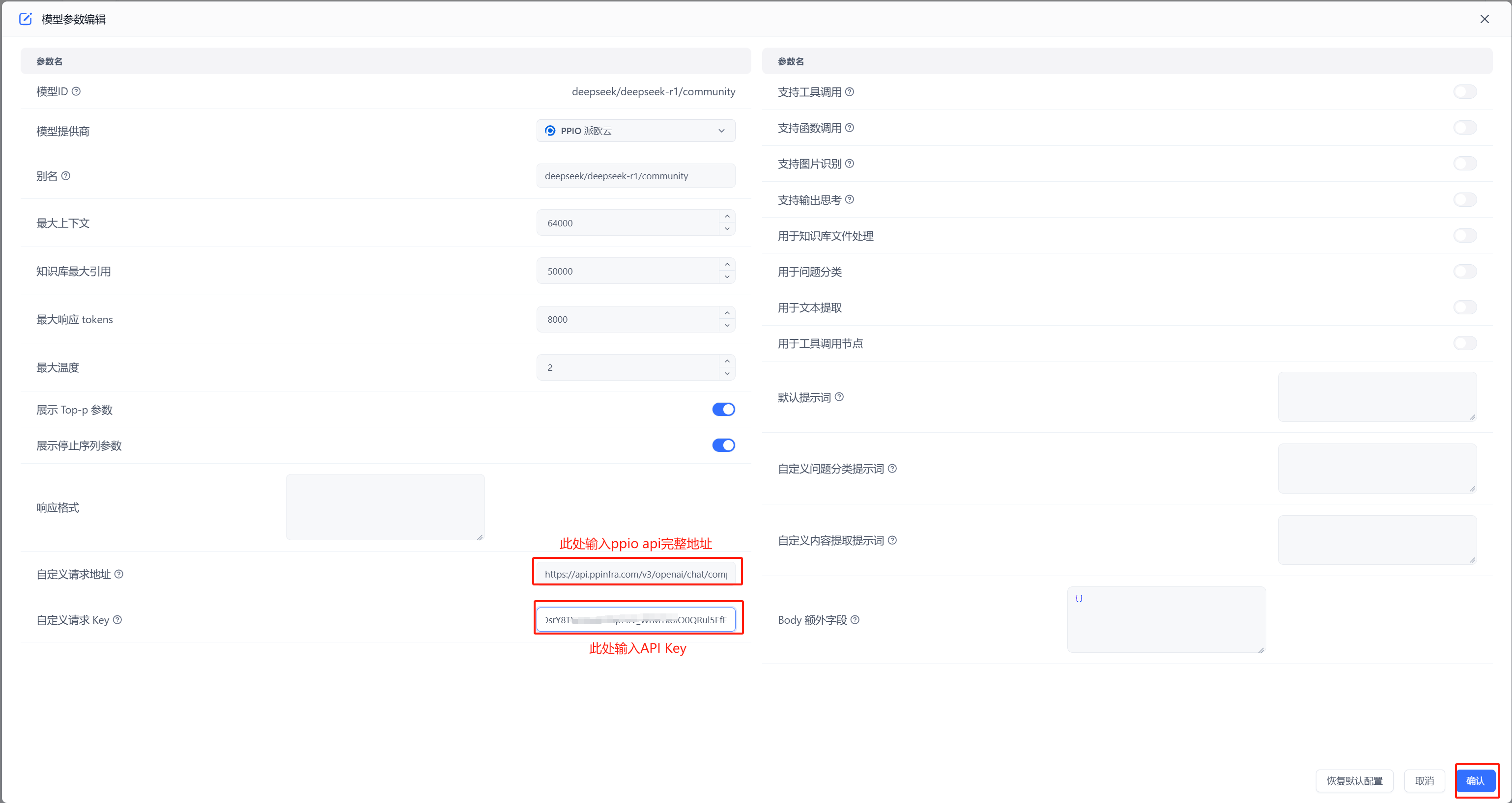
- 配置模型 自定义请求地址中输入:`https://api.ppinfra.com/v3/openai/chat/completions`
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
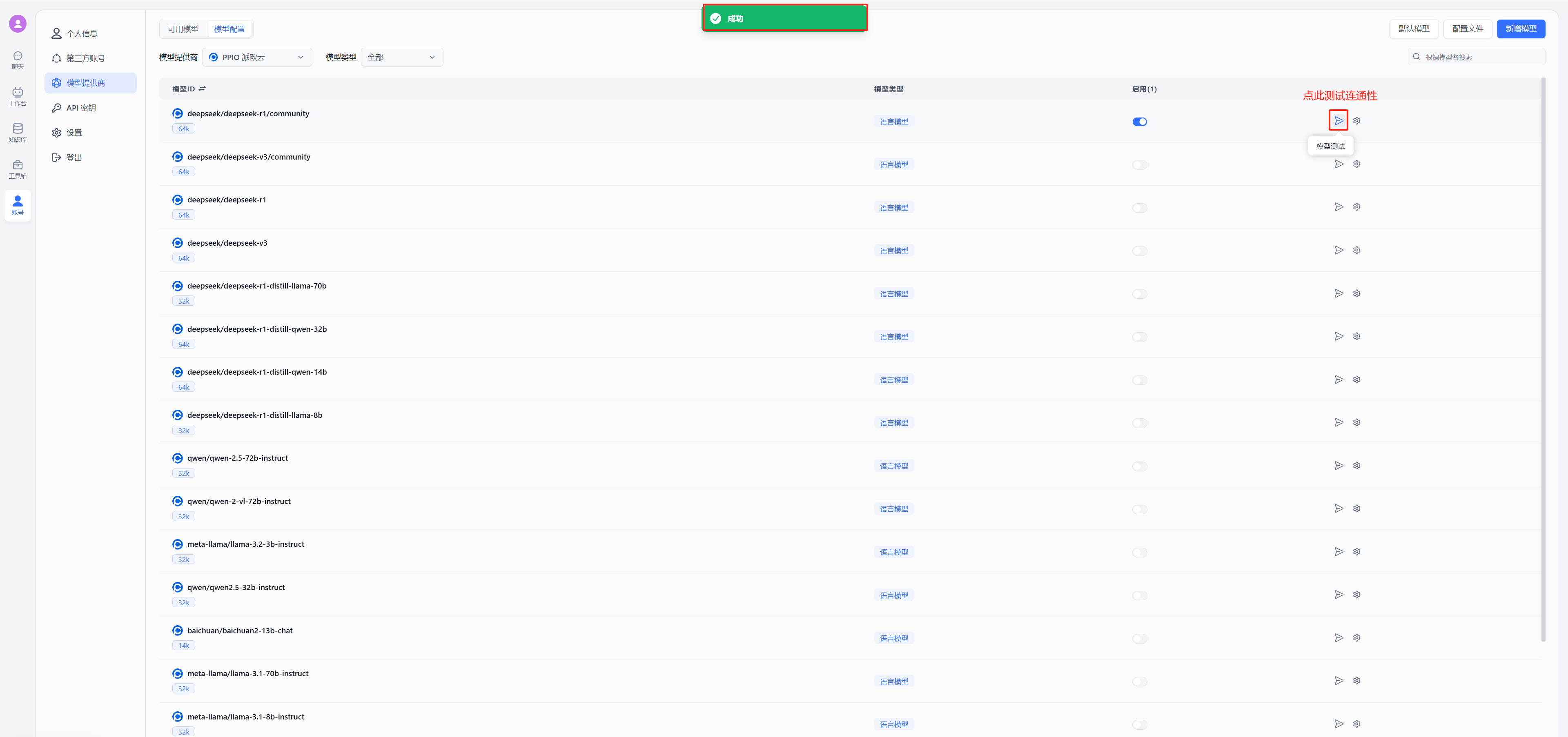
- 测试连通性
|
||||||
|
|
||||||
|
|
||||||
|
出现图中绿色的的成功显示证明连通成功,可以进行对话配置
|
||||||
|
|
||||||
|
## 4. 配置对话
|
||||||
|
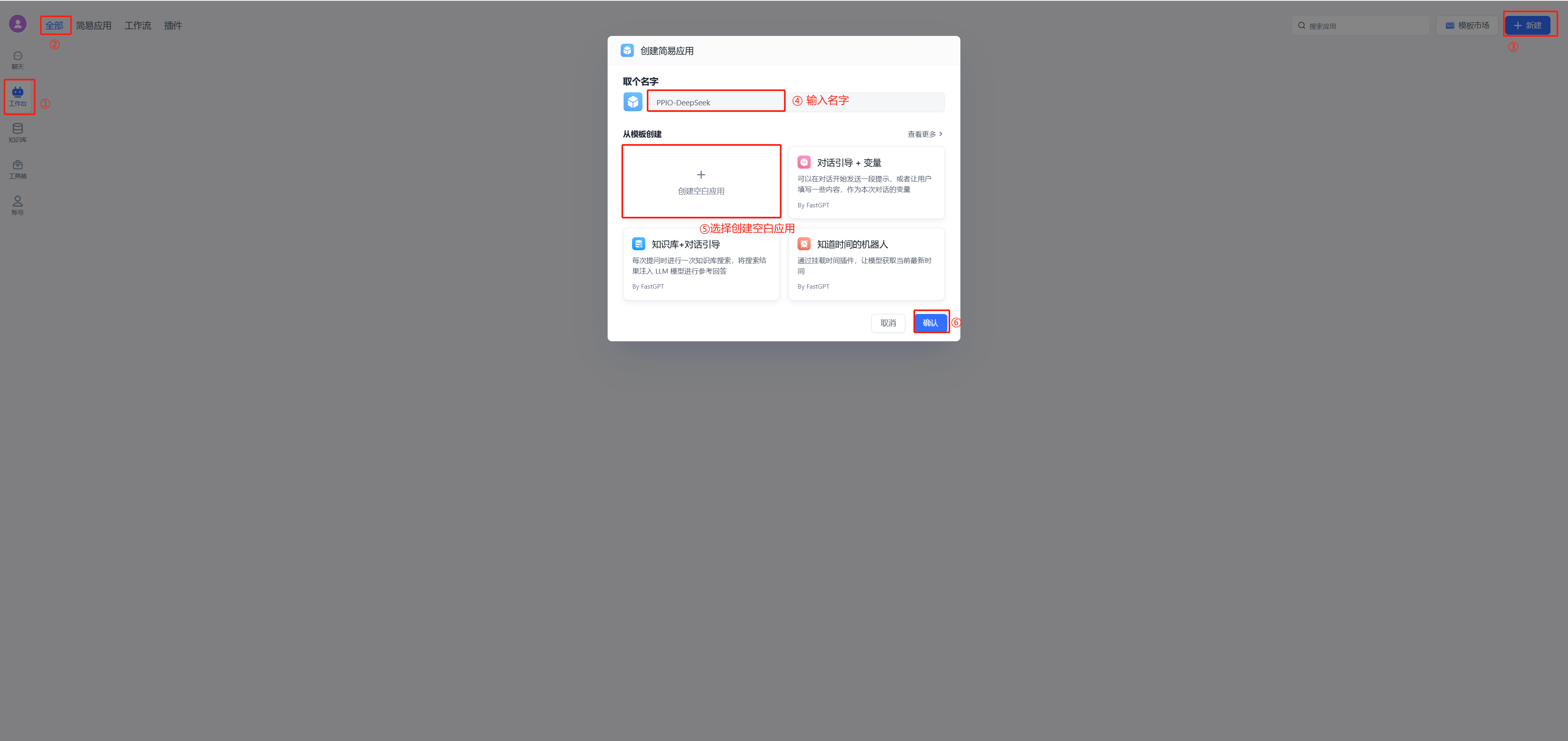
(1)新建工作台
|
||||||
|
|
||||||
|
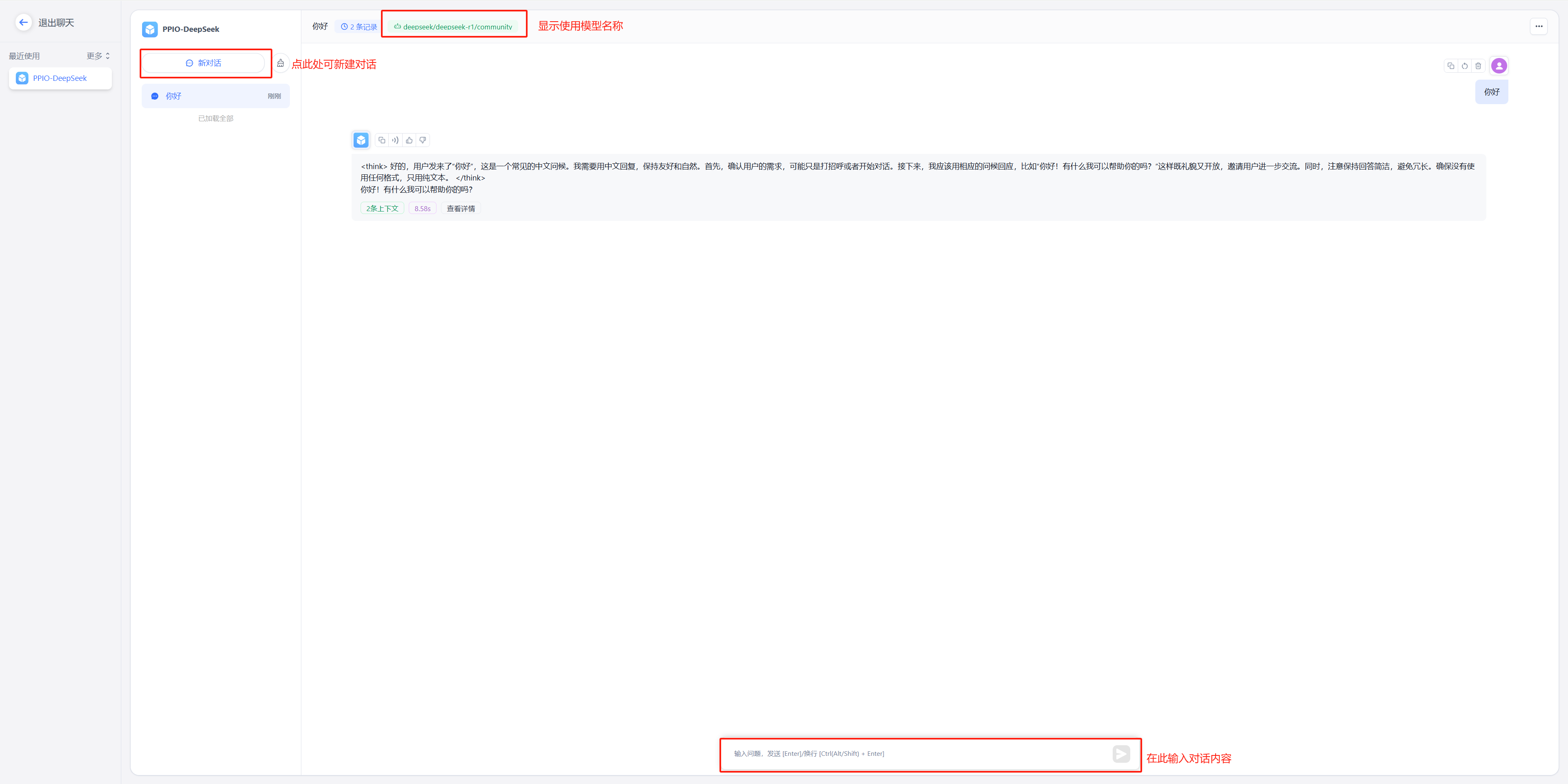
(2)开始聊天
|
||||||
|
|
||||||
|
|
||||||
|
## PPIO 全新福利重磅来袭 🔥
|
||||||
|
顺利完成教程配置步骤后,您将解锁两大权益:1. 畅享 PPIO 高速通道与 FastGPT 的效能组合;2.立即激活 **「新用户邀请奖励」** ————通过专属邀请码邀好友注册,您与好友可各领 50 元代金券,硬核福利助力 AI 工具效率倍增!
|
||||||
|
|
||||||
|
🎁 新手专享:立即使用邀请码【VOJL20】完成注册,50 元代金券奖励即刻到账!
|
||||||
@@ -11,8 +11,6 @@ weight: 853
|
|||||||
| --------------------- | --------------------- |
|
| --------------------- | --------------------- |
|
||||||
|  |  |
|
|  |  |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 创建训练订单
|
## 创建训练订单
|
||||||
|
|
||||||
{{< tabs tabTotal="2" >}}
|
{{< tabs tabTotal="2" >}}
|
||||||
@@ -289,7 +287,7 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?
|
|||||||
|
|
||||||
## 集合
|
## 集合
|
||||||
|
|
||||||
### 通用创建参数说明
|
### 通用创建参数说明(必看)
|
||||||
|
|
||||||
**入参**
|
**入参**
|
||||||
|
|
||||||
@@ -300,8 +298,11 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?
|
|||||||
| trainingType | 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 | ✅ |
|
| trainingType | 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 | ✅ |
|
||||||
| autoIndexes | 是否自动生成索引(仅商业版支持) | |
|
| autoIndexes | 是否自动生成索引(仅商业版支持) | |
|
||||||
| imageIndex | 是否自动生成图片索引(仅商业版支持) | |
|
| imageIndex | 是否自动生成图片索引(仅商业版支持) | |
|
||||||
| chunkSize | 预估块大小 | |
|
| chunkSettingMode | 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 | |
|
||||||
| chunkSplitter | 自定义最高优先分割符号 | |
|
| chunkSplitMode | 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 | |
|
||||||
|
| chunkSize | 分块大小,默认 1500。chunkSettingMode=auto时不生效。 | |
|
||||||
|
| indexSize | 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 | |
|
||||||
|
| chunkSplitter | 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 | |
|
||||||
| qaPrompt | qa拆分提示词 | |
|
| qaPrompt | qa拆分提示词 | |
|
||||||
| tags | 集合标签(字符串数组) | |
|
| tags | 集合标签(字符串数组) | |
|
||||||
| createTime | 文件创建时间(Date / String) | |
|
| createTime | 文件创建时间(Date / String) | |
|
||||||
@@ -389,9 +390,8 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
|||||||
"name":"测试训练",
|
"name":"测试训练",
|
||||||
|
|
||||||
"trainingType": "qa",
|
"trainingType": "qa",
|
||||||
"chunkSize":8000,
|
"chunkSettingMode": "auto",
|
||||||
"chunkSplitter":"",
|
"qaPrompt":"",
|
||||||
"qaPrompt":"11",
|
|
||||||
|
|
||||||
"metadata":{}
|
"metadata":{}
|
||||||
}'
|
}'
|
||||||
@@ -409,10 +409,6 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
|||||||
- parentId: 父级ID,不填则默认为根目录
|
- parentId: 父级ID,不填则默认为根目录
|
||||||
- name: 集合名称(必填)
|
- name: 集合名称(必填)
|
||||||
- metadata: 元数据(暂时没啥用)
|
- metadata: 元数据(暂时没啥用)
|
||||||
- trainingType: 训练模式(必填)
|
|
||||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
|
||||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
|
||||||
- qaPrompt: qa拆分自定义提示词(可选)
|
|
||||||
{{% /alert %}}
|
{{% /alert %}}
|
||||||
|
|
||||||
{{< /markdownify >}}
|
{{< /markdownify >}}
|
||||||
@@ -462,8 +458,7 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
|||||||
"parentId": null,
|
"parentId": null,
|
||||||
|
|
||||||
"trainingType": "chunk",
|
"trainingType": "chunk",
|
||||||
"chunkSize":512,
|
"chunkSettingMode": "auto",
|
||||||
"chunkSplitter":"",
|
|
||||||
"qaPrompt":"",
|
"qaPrompt":"",
|
||||||
|
|
||||||
"metadata":{
|
"metadata":{
|
||||||
@@ -483,10 +478,6 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
|||||||
- datasetId: 知识库的ID(必填)
|
- datasetId: 知识库的ID(必填)
|
||||||
- parentId: 父级ID,不填则默认为根目录
|
- parentId: 父级ID,不填则默认为根目录
|
||||||
- metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选)
|
- metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选)
|
||||||
- trainingType:训练模式(必填)
|
|
||||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
|
||||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
|
||||||
- qaPrompt: qa拆分自定义提示词(可选)
|
|
||||||
{{% /alert %}}
|
{{% /alert %}}
|
||||||
|
|
||||||
{{< /markdownify >}}
|
{{< /markdownify >}}
|
||||||
@@ -545,13 +536,7 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
|||||||
|
|
||||||
{{% alert icon=" " context="success" %}}
|
{{% alert icon=" " context="success" %}}
|
||||||
- file: 文件
|
- file: 文件
|
||||||
- data: 知识库相关信息(json序列化后传入)
|
- data: 知识库相关信息(json序列化后传入),参数说明见上方“通用创建参数说明”
|
||||||
- datasetId: 知识库的ID(必填)
|
|
||||||
- parentId: 父级ID,不填则默认为根目录
|
|
||||||
- trainingType:训练模式(必填)
|
|
||||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
|
||||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
|
||||||
- qaPrompt: qa拆分自定义提示词(可选)
|
|
||||||
{{% /alert %}}
|
{{% /alert %}}
|
||||||
|
|
||||||
{{< /markdownify >}}
|
{{< /markdownify >}}
|
||||||
@@ -1063,10 +1048,12 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/collect
|
|||||||
|
|
||||||
| 字段 | 类型 | 说明 | 必填 |
|
| 字段 | 类型 | 说明 | 必填 |
|
||||||
| --- | --- | --- | --- |
|
| --- | --- | --- | --- |
|
||||||
| defaultIndex | Boolean | 是否为默认索引 | ✅ |
|
| type | String | 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 | |
|
||||||
| dataId | String | 关联的向量ID | ✅ |
|
| dataId | String | 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 | |
|
||||||
| text | String | 文本内容 | ✅ |
|
| text | String | 文本内容 | ✅ |
|
||||||
|
|
||||||
|
`type` 不填则默认为 `custom` 索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。
|
||||||
|
|
||||||
### 为集合批量添加添加数据
|
### 为集合批量添加添加数据
|
||||||
|
|
||||||
注意,每次最多推送 200 组数据。
|
注意,每次最多推送 200 组数据。
|
||||||
@@ -1298,8 +1285,7 @@ curl --location --request GET 'http://localhost:3000/api/core/dataset/data/detai
|
|||||||
"chunkIndex": 0,
|
"chunkIndex": 0,
|
||||||
"indexes": [
|
"indexes": [
|
||||||
{
|
{
|
||||||
"defaultIndex": true,
|
"type": "default",
|
||||||
"type": "chunk",
|
|
||||||
"dataId": "3720083",
|
"dataId": "3720083",
|
||||||
"text": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
|
"text": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
|
||||||
"_id": "65abd4b29d1448617cba61dc"
|
"_id": "65abd4b29d1448617cba61dc"
|
||||||
@@ -1335,12 +1321,18 @@ curl --location --request PUT 'http://localhost:3000/api/core/dataset/data/updat
|
|||||||
"a":"sss",
|
"a":"sss",
|
||||||
"indexes":[
|
"indexes":[
|
||||||
{
|
{
|
||||||
"dataId": "xxx",
|
"dataId": "xxxx",
|
||||||
"defaultIndex":false,
|
"type": "default",
|
||||||
"text":"自定义索引1"
|
"text": "默认索引"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"text":"修改后的自定义索引2。(会删除原来的自定义索引2,并插入新的自定义索引2)"
|
"dataId": "xxx",
|
||||||
|
"type": "custom",
|
||||||
|
"text": "旧的自定义索引1"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"type":"custom",
|
||||||
|
"text":"新增的自定义索引"
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
}'
|
}'
|
||||||
|
|||||||
@@ -9,7 +9,7 @@ weight: 951
|
|||||||
|
|
||||||
## 登录 Sealos
|
## 登录 Sealos
|
||||||
|
|
||||||
[Sealos](https://cloud.sealos.io/)
|
[Sealos](https://cloud.sealos.io?uid=fnWRt09fZP)
|
||||||
|
|
||||||
## 创建应用
|
## 创建应用
|
||||||
|
|
||||||
|
|||||||
@@ -26,13 +26,13 @@ FastGPT 使用了 one-api 项目来管理模型池,其可以兼容 OpenAI 、A
|
|||||||
|
|
||||||
新加披区的服务器在国外,可以直接访问 OpenAI,但国内用户需要梯子才可以正常访问新加坡区。国际区价格稍贵,点击下面按键即可部署👇
|
新加披区的服务器在国外,可以直接访问 OpenAI,但国内用户需要梯子才可以正常访问新加坡区。国际区价格稍贵,点击下面按键即可部署👇
|
||||||
|
|
||||||
<a href="https://template.cloud.sealos.io/deploy?templateName=fastgpt" rel="external" target="_blank"><img src="https://cdn.jsdelivr.net/gh/labring-actions/templates@main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
<a href="https://template.cloud.sealos.io/deploy?templateName=fastgpt&uid=fnWRt09fZP" rel="external" target="_blank"><img src="https://cdn.jsdelivr.net/gh/labring-actions/templates@main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||||||
|
|
||||||
### 北京区
|
### 北京区
|
||||||
|
|
||||||
北京区服务提供商为火山云,国内用户可以稳定访问,但无法访问 OpenAI 等境外服务,价格约为新加坡区的 1/4。点击下面按键即可部署👇
|
北京区服务提供商为火山云,国内用户可以稳定访问,但无法访问 OpenAI 等境外服务,价格约为新加坡区的 1/4。点击下面按键即可部署👇
|
||||||
|
|
||||||
<a href="https://bja.sealos.run/?openapp=system-template%3FtemplateName%3Dfastgpt" rel="external" target="_blank"><img src="https://raw.githubusercontent.com/labring-actions/templates/main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
<a href="https://bja.sealos.run/?openapp=system-template%3FtemplateName%3Dfastgpt&uid=fnWRt09fZP" rel="external" target="_blank"><img src="https://raw.githubusercontent.com/labring-actions/templates/main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||||||
|
|
||||||
### 1. 开始部署
|
### 1. 开始部署
|
||||||
|
|
||||||
|
|||||||
@@ -13,7 +13,7 @@ FastGPT V4.5 引入 PgVector0.5 版本的 HNSW 索引,极大的提高了知识
|
|||||||
|
|
||||||
## PgVector升级:Sealos 部署方案
|
## PgVector升级:Sealos 部署方案
|
||||||
|
|
||||||
1. 点击[Sealos桌面](https://cloud.sealos.io)的数据库应用。
|
1. 点击[Sealos桌面](https://cloud.sealos.io?uid=fnWRt09fZP)的数据库应用。
|
||||||
2. 点击【pg】数据库的详情。
|
2. 点击【pg】数据库的详情。
|
||||||
3. 点击右上角的重启,等待重启完成。
|
3. 点击右上角的重启,等待重启完成。
|
||||||
4. 点击左侧的一键链接,等待打开 Terminal。
|
4. 点击左侧的一键链接,等待打开 Terminal。
|
||||||
|
|||||||
@@ -35,7 +35,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv4820' \
|
|||||||
|
|
||||||
## 完整更新内容
|
## 完整更新内容
|
||||||
|
|
||||||
1. 新增 - 可视化模型参数配置,取代原配置文件配置模型。预设超过 100 个模型配置。同时支持所有类型模型的一键测试。(预计下个版本会完全支持在页面上配置渠道)。
|
1. 新增 - 可视化模型参数配置,取代原配置文件配置模型。预设超过 100 个模型配置。同时支持所有类型模型的一键测试。(预计下个版本会完全支持在页面上配置渠道)。[点击查看模型配置方案](/docs/development/modelconfig/intro/)
|
||||||
2. 新增 - DeepSeek resoner 模型支持输出思考过程。
|
2. 新增 - DeepSeek resoner 模型支持输出思考过程。
|
||||||
3. 新增 - 使用记录导出和仪表盘。
|
3. 新增 - 使用记录导出和仪表盘。
|
||||||
4. 新增 - markdown 语法扩展,支持音视频(代码块 audio 和 video)。
|
4. 新增 - markdown 语法扩展,支持音视频(代码块 audio 和 video)。
|
||||||
|
|||||||
@@ -4,7 +4,7 @@ description: 'FastGPT V4.8.23 更新说明'
|
|||||||
icon: 'upgrade'
|
icon: 'upgrade'
|
||||||
draft: false
|
draft: false
|
||||||
toc: true
|
toc: true
|
||||||
weight: 802
|
weight: 801
|
||||||
---
|
---
|
||||||
|
|
||||||
## 更新指南
|
## 更新指南
|
||||||
|
|||||||
@@ -1,10 +1,10 @@
|
|||||||
---
|
---
|
||||||
title: 'V4.9.0(进行中)'
|
title: 'V4.9.0(包含升级脚本)'
|
||||||
description: 'FastGPT V4.9.0 更新说明'
|
description: 'FastGPT V4.9.0 更新说明'
|
||||||
icon: 'upgrade'
|
icon: 'upgrade'
|
||||||
draft: false
|
draft: false
|
||||||
toc: true
|
toc: true
|
||||||
weight: 801
|
weight: 800
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
@@ -12,9 +12,141 @@ weight: 801
|
|||||||
|
|
||||||
### 1. 做好数据库备份
|
### 1. 做好数据库备份
|
||||||
|
|
||||||
### 2. 更新镜像
|
### 2. 更新镜像和 PG 容器
|
||||||
|
|
||||||
### 3. 运行升级脚本
|
- 更新 FastGPT 镜像 tag: v4.9.0
|
||||||
|
- 更新 FastGPT 商业版镜像 tag: v4.9.0
|
||||||
|
- Sandbox 镜像,可以不更新
|
||||||
|
- 更新 PG 容器为 v0.8.0-pg15, 可以查看[最新的 yml](https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml)
|
||||||
|
|
||||||
|
### 3. 替换 OneAPI(可选)
|
||||||
|
|
||||||
|
如果需要使用 [AI Proxy](https://github.com/labring/aiproxy) 替换 OneAPI 的用户可执行该步骤。
|
||||||
|
|
||||||
|
#### 1. 修改 yml 文件
|
||||||
|
|
||||||
|
参考[最新的 yml](https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml) 文件。里面已移除 OneAPI 并添加了 AIProxy配置。包含一个服务和一个 PgSQL 数据库。将 `aiproxy` 的配置`追加`到 OneAPI 的配置后面(先不要删除 OneAPI,有一个初始化会自动同步 OneAPI 的配置)
|
||||||
|
|
||||||
|
{{% details title="AI Proxy Yml 配置" closed="true" %}}
|
||||||
|
|
||||||
|
```
|
||||||
|
# AI Proxy
|
||||||
|
aiproxy:
|
||||||
|
image: 'ghcr.io/labring/aiproxy:latest'
|
||||||
|
container_name: aiproxy
|
||||||
|
restart: unless-stopped
|
||||||
|
depends_on:
|
||||||
|
aiproxy_pg:
|
||||||
|
condition: service_healthy
|
||||||
|
networks:
|
||||||
|
- fastgpt
|
||||||
|
environment:
|
||||||
|
# 对应 fastgpt 里的AIPROXY_API_TOKEN
|
||||||
|
- ADMIN_KEY=aiproxy
|
||||||
|
# 错误日志详情保存时间(小时)
|
||||||
|
- LOG_DETAIL_STORAGE_HOURS=1
|
||||||
|
# 数据库连接地址
|
||||||
|
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||||
|
# 最大重试次数
|
||||||
|
- RETRY_TIMES=3
|
||||||
|
# 不需要计费
|
||||||
|
- BILLING_ENABLED=false
|
||||||
|
# 不需要严格检测模型
|
||||||
|
- DISABLE_MODEL_CONFIG=true
|
||||||
|
healthcheck:
|
||||||
|
test: ['CMD', 'curl', '-f', 'http://localhost:3000/api/status']
|
||||||
|
interval: 5s
|
||||||
|
timeout: 5s
|
||||||
|
retries: 10
|
||||||
|
aiproxy_pg:
|
||||||
|
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||||
|
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||||
|
restart: unless-stopped
|
||||||
|
container_name: aiproxy_pg
|
||||||
|
volumes:
|
||||||
|
- ./aiproxy_pg:/var/lib/postgresql/data
|
||||||
|
networks:
|
||||||
|
- fastgpt
|
||||||
|
environment:
|
||||||
|
TZ: Asia/Shanghai
|
||||||
|
POSTGRES_USER: postgres
|
||||||
|
POSTGRES_DB: aiproxy
|
||||||
|
POSTGRES_PASSWORD: aiproxy
|
||||||
|
healthcheck:
|
||||||
|
test: ['CMD', 'pg_isready', '-U', 'postgres', '-d', 'aiproxy']
|
||||||
|
interval: 5s
|
||||||
|
timeout: 5s
|
||||||
|
retries: 10
|
||||||
|
```
|
||||||
|
|
||||||
|
{{% /details %}}
|
||||||
|
|
||||||
|
#### 2. 增加 FastGPT 环境变量:
|
||||||
|
|
||||||
|
修改 yml 文件中,fastgpt 容器的环境变量:
|
||||||
|
|
||||||
|
```
|
||||||
|
# AI Proxy 的地址,如果配了该地址,优先使用
|
||||||
|
- AIPROXY_API_ENDPOINT=http://aiproxy:3000
|
||||||
|
# AI Proxy 的 Admin Token,与 AI Proxy 中的环境变量 ADMIN_KEY
|
||||||
|
- AIPROXY_API_TOKEN=aiproxy
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 3. 重载服务
|
||||||
|
|
||||||
|
`docker-compose down` 停止服务,然后 `docker-compose up -d` 启动服务,此时会追加 `aiproxy` 服务,并修改 FastGPT 的配置。
|
||||||
|
|
||||||
|
#### 4. 执行OneAPI迁移AI proxy脚本
|
||||||
|
|
||||||
|
- 可联网方案:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 进入 aiproxy 容器
|
||||||
|
docker exec -it aiproxy sh
|
||||||
|
# 安装 curl
|
||||||
|
apk add curl
|
||||||
|
# 执行脚本
|
||||||
|
curl --location --request POST 'http://localhost:3000/api/channels/import/oneapi' \
|
||||||
|
--header 'Authorization: Bearer aiproxy' \
|
||||||
|
--header 'Content-Type: application/json' \
|
||||||
|
--data-raw '{
|
||||||
|
"dsn": "mysql://root:oneapimmysql@tcp(mysql:3306)/oneapi"
|
||||||
|
}'
|
||||||
|
# 返回 {"data":[],"success":true} 代表成功
|
||||||
|
```
|
||||||
|
|
||||||
|
- 无法联网时,可打开`aiproxy`的外网暴露端口,然后在本地执行脚本。
|
||||||
|
|
||||||
|
aiProxy 暴露端口:3003:3000,修改后重新 `docker-compose up -d` 启动服务。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 在终端执行脚本
|
||||||
|
curl --location --request POST 'http://localhost:3003/api/channels/import/oneapi' \
|
||||||
|
--header 'Authorization: Bearer aiproxy' \
|
||||||
|
--header 'Content-Type: application/json' \
|
||||||
|
--data-raw '{
|
||||||
|
"dsn": "mysql://root:oneapimmysql@tcp(mysql:3306)/oneapi"
|
||||||
|
}'
|
||||||
|
# 返回 {"data":[],"success":true} 代表成功
|
||||||
|
```
|
||||||
|
|
||||||
|
- 如果不熟悉 docker 操作,建议不要走脚本迁移,直接删除 OneAPI 所有内容,然后手动重新添加渠道。
|
||||||
|
|
||||||
|
#### 5. 进入 FastGPT 检查`AI Proxy` 服务是否正常启动。
|
||||||
|
|
||||||
|
登录 root 账号后,在`账号-模型提供商`页面,可以看到多出了`模型渠道`和`调用日志`两个选项,打开模型渠道,可以看到之前 OneAPI 的渠道,说明迁移完成,此时可以手动再检查下渠道是否正常。
|
||||||
|
|
||||||
|
#### 6. 删除 OneAPI 服务
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 停止服务,或者针对性停止 OneAPI 和其 Mysql
|
||||||
|
docker-compose down
|
||||||
|
# yml 文件中删除 OneAPI 和其 Mysql 依赖
|
||||||
|
# 重启服务
|
||||||
|
docker-compose up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4. 运行 FastGPT 升级脚本
|
||||||
|
|
||||||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||||||
|
|
||||||
@@ -28,7 +160,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv490' \
|
|||||||
|
|
||||||
1. 升级 PG Vector 插件版本
|
1. 升级 PG Vector 插件版本
|
||||||
2. 全量更新知识库集合字段。
|
2. 全量更新知识库集合字段。
|
||||||
3. 全量更新知识库数据中,index 的 type 类型。(时间较长)
|
3. 全量更新知识库数据中,index 的 type 类型。(时间较长,最后可能提示 timeout,可忽略,数据库不崩都会一直增量执行)
|
||||||
|
|
||||||
## 兼容 & 弃用
|
## 兼容 & 弃用
|
||||||
|
|
||||||
@@ -42,6 +174,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv490' \
|
|||||||
1. PDF增强解析交互添加到页面上。同时内嵌 Doc2x 服务,可直接使用 Doc2x 服务解析 PDF 文件。
|
1. PDF增强解析交互添加到页面上。同时内嵌 Doc2x 服务,可直接使用 Doc2x 服务解析 PDF 文件。
|
||||||
2. 图片自动标注,同时修改知识库文件上传部分数据逻辑和交互。
|
2. 图片自动标注,同时修改知识库文件上传部分数据逻辑和交互。
|
||||||
3. pg vector 插件升级 0.8.0 版本,引入迭代搜索,减少部分数据无法被检索的情况。
|
3. pg vector 插件升级 0.8.0 版本,引入迭代搜索,减少部分数据无法被检索的情况。
|
||||||
|
4. 新增 qwen-qwq 系列模型配置。
|
||||||
|
|
||||||
## ⚙️ 优化
|
## ⚙️ 优化
|
||||||
|
|
||||||
@@ -49,8 +182,9 @@ curl --location --request POST 'https://{{host}}/api/admin/initv490' \
|
|||||||
2. Markdown 解析,增加链接后中文标点符号检测,增加空格。
|
2. Markdown 解析,增加链接后中文标点符号检测,增加空格。
|
||||||
3. Prompt 模式工具调用,支持思考模型。同时优化其格式检测,减少空输出的概率。
|
3. Prompt 模式工具调用,支持思考模型。同时优化其格式检测,减少空输出的概率。
|
||||||
4. Mongo 文件读取流合并,减少计算量。同时优化存储 chunks,极大提高大文件读取速度。50M PDF 读取时间提高 3 倍。
|
4. Mongo 文件读取流合并,减少计算量。同时优化存储 chunks,极大提高大文件读取速度。50M PDF 读取时间提高 3 倍。
|
||||||
|
5. HTTP Body 适配,增加对字符串对象的适配。
|
||||||
|
|
||||||
## 🐛 修复
|
## 🐛 修复
|
||||||
|
|
||||||
1. 增加网页抓取安全链接校验。
|
1. 增加网页抓取安全链接校验。
|
||||||
2. 批量运行时,全局变量未进一步传递到下一次运行中,导致最终变量更新错误。
|
2. 批量运行时,全局变量未进一步传递到下一次运行中,导致最终变量更新错误。
|
||||||
|
|||||||
65
docSite/content/zh-cn/docs/development/upgrading/491.md
Normal file
@@ -0,0 +1,65 @@
|
|||||||
|
---
|
||||||
|
title: 'V4.9.1'
|
||||||
|
description: 'FastGPT V4.9.1 更新说明'
|
||||||
|
icon: 'upgrade'
|
||||||
|
draft: false
|
||||||
|
toc: true
|
||||||
|
weight: 799
|
||||||
|
---
|
||||||
|
|
||||||
|
## 更新指南
|
||||||
|
|
||||||
|
### 1. 做好数据库备份
|
||||||
|
|
||||||
|
### 2. 更新镜像
|
||||||
|
|
||||||
|
- 更新 FastGPT 镜像 tag: v4.9.1-fix2
|
||||||
|
- 更新 FastGPT 商业版镜像 tag: v4.9.1-fix2
|
||||||
|
- Sandbox 镜像,可以不更新
|
||||||
|
- AIProxy 镜像修改为: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3
|
||||||
|
|
||||||
|
### 3. 执行升级脚本
|
||||||
|
|
||||||
|
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||||
|
--header 'rootkey: {{rootkey}}' \
|
||||||
|
--header 'Content-Type: application/json'
|
||||||
|
```
|
||||||
|
|
||||||
|
**脚本功能**
|
||||||
|
|
||||||
|
重新使用最新的 jieba 分词库进行分词处理。时间较长,可以从日志里查看进度。
|
||||||
|
|
||||||
|
## 🚀 新增内容
|
||||||
|
|
||||||
|
1. 商业版支持单团队模式,更好的管理内部成员。
|
||||||
|
2. 知识库分块阅读器。
|
||||||
|
3. API 知识库支持 PDF 增强解析。
|
||||||
|
4. 邀请团队成员,改为邀请链接模式。
|
||||||
|
5. 支持混合检索权重设置。
|
||||||
|
6. 支持重排模型选择和权重设置,同时调整了知识库搜索权重计算方式,改成 搜索权重 + 重排权重,而不是向量检索权重+全文检索权重+重排权重。
|
||||||
|
|
||||||
|
## ⚙️ 优化
|
||||||
|
|
||||||
|
1. 知识库数据输入框交互
|
||||||
|
2. 应用拉取绑定知识库数据交由后端处理。
|
||||||
|
3. 增加依赖包安全版本检测,并升级部分依赖包。
|
||||||
|
4. 模型测试代码。
|
||||||
|
5. 优化思考过程解析逻辑:只要配置了模型支持思考,均会解析 <think> 标签,不会因为对话时,关闭思考而不解析。
|
||||||
|
6. 载入最新 jieba 分词库,增强全文检索分词效果。
|
||||||
|
|
||||||
|
## 🐛 修复
|
||||||
|
|
||||||
|
1. 最大响应 tokens 提示显示错误的问题。
|
||||||
|
2. HTTP Node 中,字符串包含换行符时,会解析失败。
|
||||||
|
3. 知识库问题优化中,未传递历史记录。
|
||||||
|
4. 错误提示翻译缺失。
|
||||||
|
5. 内容提取节点,array 类型 schema 错误。
|
||||||
|
6. 模型渠道测试时,实际未指定渠道测试。
|
||||||
|
7. 新增自定义模型时,会把默认模型字段也保存,导致默认模型误判。
|
||||||
|
8. 修复 promp 模式工具调用,未判空思考链,导致 UI 错误展示。
|
||||||
|
9. 编辑应用信息导致头像丢失。
|
||||||
|
10. 分享链接标题会被刷新掉。
|
||||||
|
11. 计算 parentPath 时,存在鉴权失败清空。
|
||||||
44
docSite/content/zh-cn/docs/development/upgrading/492.md
Normal file
@@ -0,0 +1,44 @@
|
|||||||
|
---
|
||||||
|
title: 'V4.9.2(进行中)'
|
||||||
|
description: 'FastGPT V4.9.2 更新说明'
|
||||||
|
icon: 'upgrade'
|
||||||
|
draft: false
|
||||||
|
toc: true
|
||||||
|
weight: 799
|
||||||
|
---
|
||||||
|
|
||||||
|
## 重要提示
|
||||||
|
|
||||||
|
- 知识库导入数据 API 变更,增加`chunkSettingMode`,`chunkSplitMode`,`indexSize`可选参数,具体可参考 [知识库导入数据 API](/docs/development/openapi/dataset) 文档。
|
||||||
|
|
||||||
|
|
||||||
|
## 🚀 新增内容
|
||||||
|
|
||||||
|
1. 知识库分块优化:支持单独配置分块大小和索引大小,允许进行超大分块,以更大的输入 Tokens 换取完整分块。
|
||||||
|
2. 知识库分块增加自定义分隔符预设值,同时支持自定义换行符分割。
|
||||||
|
3. 外部变量改名:自定义变量。 并且支持在测试时调试,在分享链接中,该变量直接隐藏。
|
||||||
|
4. 集合同步时,支持同步修改标题。
|
||||||
|
5. 团队成员管理重构,抽离主流 IM SSO(企微、飞书、钉钉),并支持通过自定义 SSO 接入 FastGPT。同时完善与外部系统的成员同步。
|
||||||
|
|
||||||
|
## ⚙️ 优化
|
||||||
|
|
||||||
|
1. 导出对话日志时,支持导出成员名。
|
||||||
|
2. 邀请链接交互。
|
||||||
|
3. 无 SSL 证书时复制失败,会提示弹窗用于手动复制。
|
||||||
|
4. FastGPT 未内置 ai proxy 渠道时,也能正常展示其名称。
|
||||||
|
5. 升级 nextjs 版本至 14.2.25。
|
||||||
|
6. 工作流节点数组字符串类型,自动适配 string 输入。
|
||||||
|
7. 工作流节点数组类型,自动进行 JSON parse 解析 string 输入。
|
||||||
|
8. AI proxy 日志优化,去除重试失败的日志,仅保留最后一份错误日志。
|
||||||
|
9. 分块算法小调整:
|
||||||
|
* 跨处理符号之间连续性更强。
|
||||||
|
* 代码块分割时,用 LLM 模型上下文作为分块大小,尽可能保证代码块完整性。
|
||||||
|
* 表格分割时,用 LLM 模型上下文作为分块大小,尽可能保证表格完整性。
|
||||||
|
|
||||||
|
## 🐛 修复
|
||||||
|
|
||||||
|
1. 飞书和语雀知识库无法同步。
|
||||||
|
2. 渠道测试时,如果配置了模型自定义请求地址,会走自定义请求地址,而不是渠道请求地址。
|
||||||
|
3. 语音识别模型测试未启用的模型时,无法正常测试。
|
||||||
|
4. 管理员配置系统插件时,如果插件包含其他系统应用,无法正常鉴权。
|
||||||
|
5. 移除 TTS 自定义请求地址时,必须需要填 requestAuth 字段。
|
||||||
@@ -30,7 +30,7 @@ FastGPT 升级包括两个步骤:
|
|||||||
|
|
||||||
## Sealos 修改镜像
|
## Sealos 修改镜像
|
||||||
|
|
||||||
1. 打开 [Sealos Cloud](https://cloud.sealos.io/), 找到桌面上的应用管理
|
1. 打开 [Sealos Cloud](https://cloud.sealos.io?uid=fnWRt09fZP), 找到桌面上的应用管理
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
@@ -124,6 +124,7 @@ curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
|
|||||||
"success": true,
|
"success": true,
|
||||||
"message": "",
|
"message": "",
|
||||||
"data": {
|
"data": {
|
||||||
|
"title": "文档标题",
|
||||||
"content": "FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!\n",
|
"content": "FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!\n",
|
||||||
"previewUrl": "xxxx"
|
"previewUrl": "xxxx"
|
||||||
}
|
}
|
||||||
@@ -131,10 +132,13 @@ curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
|
|||||||
```
|
```
|
||||||
|
|
||||||
{{% alert icon=" " context="success" %}}
|
{{% alert icon=" " context="success" %}}
|
||||||
二选一返回,如果同时返回则 content 优先级更高。
|
|
||||||
|
|
||||||
|
- title - 文件标题。
|
||||||
- content - 文件内容,直接拿来用。
|
- content - 文件内容,直接拿来用。
|
||||||
- previewUrl - 文件链接,系统会请求该地址获取文件内容。
|
- previewUrl - 文件链接,系统会请求该地址获取文件内容。
|
||||||
|
|
||||||
|
`content`和`previewUrl`二选一返回,如果同时返回则 `content` 优先级更高,返回 `previewUrl`时,则会访问该链接进行文档内容读取。
|
||||||
|
|
||||||
{{% /alert %}}
|
{{% /alert %}}
|
||||||
|
|
||||||
{{< /markdownify >}}
|
{{< /markdownify >}}
|
||||||
|
|||||||
@@ -14,7 +14,7 @@ weight: 303
|
|||||||
|
|
||||||
这里介绍在 Sealos 中部署 SearXNG 的方法。Docker 部署,可以直接参考 [SearXNG 官方教程](https://github.com/searxng/searxng)。
|
这里介绍在 Sealos 中部署 SearXNG 的方法。Docker 部署,可以直接参考 [SearXNG 官方教程](https://github.com/searxng/searxng)。
|
||||||
|
|
||||||
点击打开 [Sealos 北京区](https://bja.sealos.run/),点击应用部署,并新建一个应用:
|
点击打开 [Sealos 北京区](https://bja.sealos.run?uid=fnWRt09fZP),点击应用部署,并新建一个应用:
|
||||||
|
|
||||||
| 打开应用部署 | 点击新建应用 |
|
| 打开应用部署 | 点击新建应用 |
|
||||||
| --- | --- |
|
| --- | --- |
|
||||||
@@ -130,7 +130,7 @@ doi_resolvers:
|
|||||||
default_doi_resolver: 'oadoi.org'
|
default_doi_resolver: 'oadoi.org'
|
||||||
```
|
```
|
||||||
|
|
||||||
国内目前只有 Bing 引擎可以正常用,所以上面的配置只配置了 bing 引擎。如果在海外部署,可以使用[Sealos 新加坡可用区](https://cloud.sealos.io/),并配置其他搜索引擎,可以参考[SearXNG 默认配置文件](https://github.com/searxng/searxng/blob/master/searx/settings.yml), 从里面复制一些 engine 配置。例如:
|
国内目前只有 Bing 引擎可以正常用,所以上面的配置只配置了 bing 引擎。如果在海外部署,可以使用[Sealos 新加坡可用区](https://cloud.sealos.io?uid=fnWRt09fZP),并配置其他搜索引擎,可以参考[SearXNG 默认配置文件](https://github.com/searxng/searxng/blob/master/searx/settings.yml), 从里面复制一些 engine 配置。例如:
|
||||||
|
|
||||||
```
|
```
|
||||||
- name: duckduckgo
|
- name: duckduckgo
|
||||||
|
|||||||
@@ -0,0 +1,66 @@
|
|||||||
|
---
|
||||||
|
title: "邀请链接说明文档"
|
||||||
|
description: "如何使用邀请链接来邀请团队成员"
|
||||||
|
icon: "group"
|
||||||
|
draft: false
|
||||||
|
toc: true
|
||||||
|
weight: 451
|
||||||
|
---
|
||||||
|
|
||||||
|
v4.9.1 团队邀请成员将开始使用「邀请链接」的模式,弃用之前输入用户名进行添加的形式。
|
||||||
|
|
||||||
|
在版本升级后,原收到邀请还未加入团队的成员,将自动清除邀请。请使用邀请链接重新邀请成员。
|
||||||
|
|
||||||
|
## 如何使用
|
||||||
|
|
||||||
|
1. **在团队管理页面,管理员可点击「邀请成员」按钮打开邀请成员弹窗**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
2. **在邀请成员弹窗中,点击「创建邀请链接」按钮,创建邀请链接。**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
3. **输入对应内容**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
链接描述:建议将链接描述为使用场景或用途。链接创建后不支持修改噢。
|
||||||
|
|
||||||
|
有效期:30分钟,7天,1年
|
||||||
|
|
||||||
|
有效人数:1人,无限制
|
||||||
|
|
||||||
|
4. **点击复制链接,并将其发送给想要邀请的人。**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
5. **用户访问链接后,如果未登录/未注册,则先跳转到登录页面进行登录。在登录后将进入团队页面,处理邀请。**
|
||||||
|
|
||||||
|
> 邀请链接形如:fastgpt.cn/account/team?invitelinkid=xxxx
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
点击接受,则用户将加入团队
|
||||||
|
|
||||||
|
点击忽略,则关闭弹窗,用户下次访问该邀请链接则还可以选择加入。
|
||||||
|
|
||||||
|
## 链接失效和自动清理
|
||||||
|
|
||||||
|
### 链接失效原因
|
||||||
|
|
||||||
|
手动停用链接
|
||||||
|
|
||||||
|
邀请链接到达有效期,自动停用
|
||||||
|
|
||||||
|
有效人数为1人的链接,已有1人通过邀请链接加入团队。
|
||||||
|
|
||||||
|
停用的链接无法访问,也无法再次启用。
|
||||||
|
|
||||||
|
### 链接上限
|
||||||
|
|
||||||
|
一个用户最多可以同时存在 10 个**有效的**邀请链接。
|
||||||
|
|
||||||
|
### 链接自动清理
|
||||||
|
|
||||||
|
失效的链接将在 30 天后自动清理。
|
||||||
@@ -89,6 +89,12 @@ weight: 506
|
|||||||
47.99.59.223
|
47.99.59.223
|
||||||
112.124.46.5
|
112.124.46.5
|
||||||
121.40.46.247
|
121.40.46.247
|
||||||
|
120.26.145.73
|
||||||
|
120.26.147.199
|
||||||
|
121.43.125.163
|
||||||
|
121.196.228.45
|
||||||
|
121.43.126.202
|
||||||
|
120.26.144.37
|
||||||
```
|
```
|
||||||
|
|
||||||
## 4. 获取AES Key,选择加密方式
|
## 4. 获取AES Key,选择加密方式
|
||||||
|
|||||||
@@ -27,7 +27,7 @@ weight: 510
|
|||||||
|
|
||||||
## sealos部署服务
|
## sealos部署服务
|
||||||
|
|
||||||
[访问sealos](https://cloud.sealos.run/) 登录进来之后打开「应用管理」-> 「新建应用」。
|
[访问sealos](https://hzh.sealos.run?uid=fnWRt09fZP) 登录进来之后打开「应用管理」-> 「新建应用」。
|
||||||
- 应用名:称随便填写
|
- 应用名:称随便填写
|
||||||
- 镜像名:私人微信填写 aibotk/wechat-assistant 企业微信填写 aibotk/worker-assistant
|
- 镜像名:私人微信填写 aibotk/wechat-assistant 企业微信填写 aibotk/worker-assistant
|
||||||
- cpu和内存建议 1c1g
|
- cpu和内存建议 1c1g
|
||||||
|
|||||||
14
package.json
@@ -11,16 +11,22 @@
|
|||||||
"initIcon": "node ./scripts/icon/init.js",
|
"initIcon": "node ./scripts/icon/init.js",
|
||||||
"previewIcon": "node ./scripts/icon/index.js",
|
"previewIcon": "node ./scripts/icon/index.js",
|
||||||
"api:gen": "tsc ./scripts/openapi/index.ts && node ./scripts/openapi/index.js && npx @redocly/cli build-docs ./scripts/openapi/openapi.json -o ./projects/app/public/openapi/index.html",
|
"api:gen": "tsc ./scripts/openapi/index.ts && node ./scripts/openapi/index.js && npx @redocly/cli build-docs ./scripts/openapi/openapi.json -o ./projects/app/public/openapi/index.html",
|
||||||
"create:i18n": "node ./scripts/i18n/index.js"
|
"create:i18n": "node ./scripts/i18n/index.js",
|
||||||
|
"test": "vitest run --exclude 'test/cases/spec'",
|
||||||
|
"test:all": "vitest run",
|
||||||
|
"test:workflow": "vitest run workflow"
|
||||||
},
|
},
|
||||||
"devDependencies": {
|
"devDependencies": {
|
||||||
"@chakra-ui/cli": "^2.4.1",
|
"@chakra-ui/cli": "^2.4.1",
|
||||||
|
"@vitest/coverage-v8": "^3.0.2",
|
||||||
"husky": "^8.0.3",
|
"husky": "^8.0.3",
|
||||||
|
"i18next": "23.16.8",
|
||||||
"lint-staged": "^13.3.0",
|
"lint-staged": "^13.3.0",
|
||||||
"i18next": "23.11.5",
|
"next-i18next": "15.4.2",
|
||||||
"next-i18next": "15.3.0",
|
|
||||||
"react-i18next": "14.1.2",
|
|
||||||
"prettier": "3.2.4",
|
"prettier": "3.2.4",
|
||||||
|
"react-i18next": "14.1.2",
|
||||||
|
"vitest": "^3.0.2",
|
||||||
|
"vitest-mongodb": "^1.0.1",
|
||||||
"zhlint": "^0.7.4"
|
"zhlint": "^0.7.4"
|
||||||
},
|
},
|
||||||
"lint-staged": {
|
"lint-staged": {
|
||||||
|
|||||||
@@ -24,7 +24,10 @@ export enum TeamErrEnum {
|
|||||||
cannotModifyRootOrg = 'cannotModifyRootOrg',
|
cannotModifyRootOrg = 'cannotModifyRootOrg',
|
||||||
cannotDeleteNonEmptyOrg = 'cannotDeleteNonEmptyOrg',
|
cannotDeleteNonEmptyOrg = 'cannotDeleteNonEmptyOrg',
|
||||||
cannotDeleteDefaultGroup = 'cannotDeleteDefaultGroup',
|
cannotDeleteDefaultGroup = 'cannotDeleteDefaultGroup',
|
||||||
userNotActive = 'userNotActive'
|
userNotActive = 'userNotActive',
|
||||||
|
invitationLinkInvalid = 'invitationLinkInvalid',
|
||||||
|
youHaveBeenInTheTeam = 'youHaveBeenInTheTeam',
|
||||||
|
tooManyInvitations = 'tooManyInvitations'
|
||||||
}
|
}
|
||||||
|
|
||||||
const teamErr = [
|
const teamErr = [
|
||||||
@@ -112,6 +115,18 @@ const teamErr = [
|
|||||||
{
|
{
|
||||||
statusText: TeamErrEnum.cannotDeleteNonEmptyOrg,
|
statusText: TeamErrEnum.cannotDeleteNonEmptyOrg,
|
||||||
message: i18nT('common:code_error.team_error.cannot_delete_non_empty_org')
|
message: i18nT('common:code_error.team_error.cannot_delete_non_empty_org')
|
||||||
|
},
|
||||||
|
{
|
||||||
|
statusText: TeamErrEnum.invitationLinkInvalid,
|
||||||
|
message: i18nT('common:code_error.team_error.invitation_link_invalid')
|
||||||
|
},
|
||||||
|
{
|
||||||
|
statusText: TeamErrEnum.youHaveBeenInTheTeam,
|
||||||
|
message: i18nT('common:code_error.team_error.you_have_been_in_the_team')
|
||||||
|
},
|
||||||
|
{
|
||||||
|
statusText: TeamErrEnum.tooManyInvitations,
|
||||||
|
message: i18nT('common:code_error.team_error.too_many_invitations')
|
||||||
}
|
}
|
||||||
];
|
];
|
||||||
|
|
||||||
|
|||||||
@@ -1,3 +1,8 @@
|
|||||||
|
export type GetPathProps = {
|
||||||
|
sourceId?: ParentIdType;
|
||||||
|
type: 'current' | 'parent';
|
||||||
|
};
|
||||||
|
|
||||||
export type ParentTreePathItemType = {
|
export type ParentTreePathItemType = {
|
||||||
parentId: string;
|
parentId: string;
|
||||||
parentName: string;
|
parentName: string;
|
||||||
|
|||||||
@@ -168,7 +168,7 @@ export const markdownProcess = async ({
|
|||||||
return simpleMarkdownText(imageProcess);
|
return simpleMarkdownText(imageProcess);
|
||||||
};
|
};
|
||||||
|
|
||||||
export const matchMdImgTextAndUpload = (text: string) => {
|
export const matchMdImg = (text: string) => {
|
||||||
const base64Regex = /!\[([^\]]*)\]\((data:image\/[^;]+;base64[^)]+)\)/g;
|
const base64Regex = /!\[([^\]]*)\]\((data:image\/[^;]+;base64[^)]+)\)/g;
|
||||||
const imageList: ImageType[] = [];
|
const imageList: ImageType[] = [];
|
||||||
|
|
||||||
|
|||||||
@@ -1,16 +1,17 @@
|
|||||||
|
import { defaultMaxChunkSize } from '../../core/dataset/training/utils';
|
||||||
import { getErrText } from '../error/utils';
|
import { getErrText } from '../error/utils';
|
||||||
import { replaceRegChars } from './tools';
|
|
||||||
|
|
||||||
export const CUSTOM_SPLIT_SIGN = '-----CUSTOM_SPLIT_SIGN-----';
|
export const CUSTOM_SPLIT_SIGN = '-----CUSTOM_SPLIT_SIGN-----';
|
||||||
|
|
||||||
type SplitProps = {
|
type SplitProps = {
|
||||||
text: string;
|
text: string;
|
||||||
chunkLen: number;
|
chunkSize: number;
|
||||||
|
maxSize?: number;
|
||||||
overlapRatio?: number;
|
overlapRatio?: number;
|
||||||
customReg?: string[];
|
customReg?: string[];
|
||||||
};
|
};
|
||||||
export type TextSplitProps = Omit<SplitProps, 'text' | 'chunkLen'> & {
|
export type TextSplitProps = Omit<SplitProps, 'text' | 'chunkSize'> & {
|
||||||
chunkLen?: number;
|
chunkSize?: number;
|
||||||
};
|
};
|
||||||
|
|
||||||
type SplitResponse = {
|
type SplitResponse = {
|
||||||
@@ -56,7 +57,7 @@ const strIsMdTable = (str: string) => {
|
|||||||
return true;
|
return true;
|
||||||
};
|
};
|
||||||
const markdownTableSplit = (props: SplitProps): SplitResponse => {
|
const markdownTableSplit = (props: SplitProps): SplitResponse => {
|
||||||
let { text = '', chunkLen } = props;
|
let { text = '', chunkSize } = props;
|
||||||
const splitText2Lines = text.split('\n');
|
const splitText2Lines = text.split('\n');
|
||||||
const header = splitText2Lines[0];
|
const header = splitText2Lines[0];
|
||||||
const headerSize = header.split('|').length - 2;
|
const headerSize = header.split('|').length - 2;
|
||||||
@@ -72,7 +73,7 @@ ${mdSplitString}
|
|||||||
`;
|
`;
|
||||||
|
|
||||||
for (let i = 2; i < splitText2Lines.length; i++) {
|
for (let i = 2; i < splitText2Lines.length; i++) {
|
||||||
if (chunk.length + splitText2Lines[i].length > chunkLen * 1.2) {
|
if (chunk.length + splitText2Lines[i].length > chunkSize * 1.2) {
|
||||||
chunks.push(chunk);
|
chunks.push(chunk);
|
||||||
chunk = `${header}
|
chunk = `${header}
|
||||||
${mdSplitString}
|
${mdSplitString}
|
||||||
@@ -93,17 +94,23 @@ ${mdSplitString}
|
|||||||
|
|
||||||
/*
|
/*
|
||||||
1. 自定义分隔符:不需要重叠,不需要小块合并
|
1. 自定义分隔符:不需要重叠,不需要小块合并
|
||||||
2. Markdown 标题:不需要重叠;标题嵌套共享,不需要小块合并
|
2. Markdown 标题:不需要重叠;标题嵌套共享,需要小块合并
|
||||||
3. 特殊 markdown 语法:不需要重叠,需要小块合并
|
3. 特殊 markdown 语法:不需要重叠,需要小块合并
|
||||||
4. 段落:尽可能保证它是一个完整的段落。
|
4. 段落:尽可能保证它是一个完整的段落。
|
||||||
5. 标点分割:重叠
|
5. 标点分割:重叠
|
||||||
*/
|
*/
|
||||||
const commonSplit = (props: SplitProps): SplitResponse => {
|
const commonSplit = (props: SplitProps): SplitResponse => {
|
||||||
let { text = '', chunkLen, overlapRatio = 0.15, customReg = [] } = props;
|
let {
|
||||||
|
text = '',
|
||||||
|
chunkSize,
|
||||||
|
maxSize = defaultMaxChunkSize,
|
||||||
|
overlapRatio = 0.15,
|
||||||
|
customReg = []
|
||||||
|
} = props;
|
||||||
|
|
||||||
const splitMarker = 'SPLIT_HERE_SPLIT_HERE';
|
const splitMarker = 'SPLIT_HERE_SPLIT_HERE';
|
||||||
const codeBlockMarker = 'CODE_BLOCK_LINE_MARKER';
|
const codeBlockMarker = 'CODE_BLOCK_LINE_MARKER';
|
||||||
const overlapLen = Math.round(chunkLen * overlapRatio);
|
const overlapLen = Math.round(chunkSize * overlapRatio);
|
||||||
|
|
||||||
// replace code block all \n to codeBlockMarker
|
// replace code block all \n to codeBlockMarker
|
||||||
text = text.replace(/(```[\s\S]*?```|~~~[\s\S]*?~~~)/g, function (match) {
|
text = text.replace(/(```[\s\S]*?```|~~~[\s\S]*?~~~)/g, function (match) {
|
||||||
@@ -115,34 +122,38 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
// The larger maxLen is, the next sentence is less likely to trigger splitting
|
// The larger maxLen is, the next sentence is less likely to trigger splitting
|
||||||
const markdownIndex = 4;
|
const markdownIndex = 4;
|
||||||
const forbidOverlapIndex = 8;
|
const forbidOverlapIndex = 8;
|
||||||
const stepReges: { reg: RegExp; maxLen: number }[] = [
|
|
||||||
...customReg.map((text) => ({
|
|
||||||
reg: new RegExp(`(${replaceRegChars(text)})`, 'g'),
|
|
||||||
maxLen: chunkLen * 1.4
|
|
||||||
})),
|
|
||||||
{ reg: /^(#\s[^\n]+\n)/gm, maxLen: chunkLen * 1.2 },
|
|
||||||
{ reg: /^(##\s[^\n]+\n)/gm, maxLen: chunkLen * 1.4 },
|
|
||||||
{ reg: /^(###\s[^\n]+\n)/gm, maxLen: chunkLen * 1.6 },
|
|
||||||
{ reg: /^(####\s[^\n]+\n)/gm, maxLen: chunkLen * 1.8 },
|
|
||||||
{ reg: /^(#####\s[^\n]+\n)/gm, maxLen: chunkLen * 1.8 },
|
|
||||||
|
|
||||||
{ reg: /([\n]([`~]))/g, maxLen: chunkLen * 4 }, // code block
|
const stepReges: { reg: RegExp | string; maxLen: number }[] = [
|
||||||
{ reg: /([\n](?=\s*[0-9]+\.))/g, maxLen: chunkLen * 2 }, // 增大块,尽可能保证它是一个完整的段落。 (?![\*\-|>`0-9]): markdown special char
|
...customReg.map((text) => ({
|
||||||
{ reg: /(\n{2,})/g, maxLen: chunkLen * 1.6 },
|
reg: text.replaceAll('\\n', '\n'),
|
||||||
{ reg: /([\n])/g, maxLen: chunkLen * 1.2 },
|
maxLen: chunkSize
|
||||||
|
})),
|
||||||
|
{ reg: /^(#\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||||
|
{ reg: /^(##\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||||
|
{ reg: /^(###\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||||
|
{ reg: /^(####\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||||
|
{ reg: /^(#####\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||||
|
|
||||||
|
{ reg: /([\n](```[\s\S]*?```|~~~[\s\S]*?~~~))/g, maxLen: maxSize }, // code block
|
||||||
|
{
|
||||||
|
reg: /(\n\|(?:(?:[^\n|]+\|){1,})\n\|(?:[:\-\s]+\|){1,}\n(?:\|(?:[^\n|]+\|)*\n)*)/g,
|
||||||
|
maxLen: maxSize
|
||||||
|
}, // Table 尽可能保证完整性
|
||||||
|
{ reg: /(\n{2,})/g, maxLen: chunkSize },
|
||||||
|
{ reg: /([\n])/g, maxLen: chunkSize },
|
||||||
// ------ There's no overlap on the top
|
// ------ There's no overlap on the top
|
||||||
{ reg: /([。]|([a-zA-Z])\.\s)/g, maxLen: chunkLen * 1.2 },
|
{ reg: /([。]|([a-zA-Z])\.\s)/g, maxLen: chunkSize },
|
||||||
{ reg: /([!]|!\s)/g, maxLen: chunkLen * 1.2 },
|
{ reg: /([!]|!\s)/g, maxLen: chunkSize },
|
||||||
{ reg: /([?]|\?\s)/g, maxLen: chunkLen * 1.4 },
|
{ reg: /([?]|\?\s)/g, maxLen: chunkSize },
|
||||||
{ reg: /([;]|;\s)/g, maxLen: chunkLen * 1.6 },
|
{ reg: /([;]|;\s)/g, maxLen: chunkSize },
|
||||||
{ reg: /([,]|,\s)/g, maxLen: chunkLen * 2 }
|
{ reg: /([,]|,\s)/g, maxLen: chunkSize }
|
||||||
];
|
];
|
||||||
|
|
||||||
const customRegLen = customReg.length;
|
const customRegLen = customReg.length;
|
||||||
const checkIsCustomStep = (step: number) => step < customRegLen;
|
const checkIsCustomStep = (step: number) => step < customRegLen;
|
||||||
const checkIsMarkdownSplit = (step: number) =>
|
const checkIsMarkdownSplit = (step: number) =>
|
||||||
step >= customRegLen && step <= markdownIndex + customRegLen;
|
step >= customRegLen && step <= markdownIndex + customRegLen;
|
||||||
+customReg.length;
|
|
||||||
const checkForbidOverlap = (step: number) => step <= forbidOverlapIndex + customRegLen;
|
const checkForbidOverlap = (step: number) => step <= forbidOverlapIndex + customRegLen;
|
||||||
|
|
||||||
// if use markdown title split, Separate record title
|
// if use markdown title split, Separate record title
|
||||||
@@ -151,7 +162,8 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
return [
|
return [
|
||||||
{
|
{
|
||||||
text,
|
text,
|
||||||
title: ''
|
title: '',
|
||||||
|
chunkMaxSize: chunkSize
|
||||||
}
|
}
|
||||||
];
|
];
|
||||||
}
|
}
|
||||||
@@ -159,27 +171,46 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
const isCustomStep = checkIsCustomStep(step);
|
const isCustomStep = checkIsCustomStep(step);
|
||||||
const isMarkdownSplit = checkIsMarkdownSplit(step);
|
const isMarkdownSplit = checkIsMarkdownSplit(step);
|
||||||
|
|
||||||
const { reg } = stepReges[step];
|
const { reg, maxLen } = stepReges[step];
|
||||||
|
|
||||||
const splitTexts = text
|
const replaceText = (() => {
|
||||||
.replace(
|
if (typeof reg === 'string') {
|
||||||
|
let tmpText = text;
|
||||||
|
reg.split('|').forEach((itemReg) => {
|
||||||
|
tmpText = tmpText.replaceAll(
|
||||||
|
itemReg,
|
||||||
|
(() => {
|
||||||
|
if (isCustomStep) return splitMarker;
|
||||||
|
if (isMarkdownSplit) return `${splitMarker}$1`;
|
||||||
|
return `$1${splitMarker}`;
|
||||||
|
})()
|
||||||
|
);
|
||||||
|
});
|
||||||
|
return tmpText;
|
||||||
|
}
|
||||||
|
|
||||||
|
return text.replace(
|
||||||
reg,
|
reg,
|
||||||
(() => {
|
(() => {
|
||||||
if (isCustomStep) return splitMarker;
|
if (isCustomStep) return splitMarker;
|
||||||
if (isMarkdownSplit) return `${splitMarker}$1`;
|
if (isMarkdownSplit) return `${splitMarker}$1`;
|
||||||
return `$1${splitMarker}`;
|
return `$1${splitMarker}`;
|
||||||
})()
|
})()
|
||||||
)
|
);
|
||||||
.split(`${splitMarker}`)
|
})();
|
||||||
.filter((part) => part.trim());
|
|
||||||
|
const splitTexts = replaceText.split(splitMarker).filter((part) => part.trim());
|
||||||
|
|
||||||
return splitTexts
|
return splitTexts
|
||||||
.map((text) => {
|
.map((text) => {
|
||||||
const matchTitle = isMarkdownSplit ? text.match(reg)?.[0] || '' : '';
|
const matchTitle = isMarkdownSplit ? text.match(reg)?.[0] || '' : '';
|
||||||
|
// 如果一个分块没有匹配到,则使用默认块大小,否则使用最大块大小
|
||||||
|
const chunkMaxSize = text.match(reg) === null ? chunkSize : maxLen;
|
||||||
|
|
||||||
return {
|
return {
|
||||||
text: isMarkdownSplit ? text.replace(matchTitle, '') : text,
|
text: isMarkdownSplit ? text.replace(matchTitle, '') : text,
|
||||||
title: matchTitle
|
title: matchTitle,
|
||||||
|
chunkMaxSize
|
||||||
};
|
};
|
||||||
})
|
})
|
||||||
.filter((item) => !!item.title || !!item.text?.trim());
|
.filter((item) => !!item.title || !!item.text?.trim());
|
||||||
@@ -188,7 +219,7 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
/* Gets the overlap at the end of a text as the beginning of the next block */
|
/* Gets the overlap at the end of a text as the beginning of the next block */
|
||||||
const getOneTextOverlapText = ({ text, step }: { text: string; step: number }): string => {
|
const getOneTextOverlapText = ({ text, step }: { text: string; step: number }): string => {
|
||||||
const forbidOverlap = checkForbidOverlap(step);
|
const forbidOverlap = checkForbidOverlap(step);
|
||||||
const maxOverlapLen = chunkLen * 0.4;
|
const maxOverlapLen = chunkSize * 0.4;
|
||||||
|
|
||||||
// step >= stepReges.length: Do not overlap incomplete sentences
|
// step >= stepReges.length: Do not overlap incomplete sentences
|
||||||
if (forbidOverlap || overlapLen === 0 || step >= stepReges.length) return '';
|
if (forbidOverlap || overlapLen === 0 || step >= stepReges.length) return '';
|
||||||
@@ -227,17 +258,17 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
}): string[] => {
|
}): string[] => {
|
||||||
const isMarkdownStep = checkIsMarkdownSplit(step);
|
const isMarkdownStep = checkIsMarkdownSplit(step);
|
||||||
const isCustomStep = checkIsCustomStep(step);
|
const isCustomStep = checkIsCustomStep(step);
|
||||||
const forbidConcat = isMarkdownStep || isCustomStep; // forbid=true时候,lastText肯定为空
|
const forbidConcat = isCustomStep; // forbid=true时候,lastText肯定为空
|
||||||
|
|
||||||
// oversize
|
// Over step
|
||||||
if (step >= stepReges.length) {
|
if (step >= stepReges.length) {
|
||||||
if (text.length < chunkLen * 3) {
|
if (text.length < maxSize) {
|
||||||
return [text];
|
return [text];
|
||||||
}
|
}
|
||||||
// use slice-chunkLen to split text
|
// use slice-chunkSize to split text
|
||||||
const chunks: string[] = [];
|
const chunks: string[] = [];
|
||||||
for (let i = 0; i < text.length; i += chunkLen - overlapLen) {
|
for (let i = 0; i < text.length; i += chunkSize - overlapLen) {
|
||||||
chunks.push(text.slice(i, i + chunkLen));
|
chunks.push(text.slice(i, i + chunkSize));
|
||||||
}
|
}
|
||||||
return chunks;
|
return chunks;
|
||||||
}
|
}
|
||||||
@@ -245,19 +276,18 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
// split text by special char
|
// split text by special char
|
||||||
const splitTexts = getSplitTexts({ text, step });
|
const splitTexts = getSplitTexts({ text, step });
|
||||||
|
|
||||||
const maxLen = splitTexts.length > 1 ? stepReges[step].maxLen : chunkLen;
|
|
||||||
const minChunkLen = chunkLen * 0.7;
|
|
||||||
|
|
||||||
const chunks: string[] = [];
|
const chunks: string[] = [];
|
||||||
for (let i = 0; i < splitTexts.length; i++) {
|
for (let i = 0; i < splitTexts.length; i++) {
|
||||||
const item = splitTexts[i];
|
const item = splitTexts[i];
|
||||||
|
|
||||||
|
const maxLen = item.chunkMaxSize; // 当前块最大长度
|
||||||
|
|
||||||
const lastTextLen = lastText.length;
|
const lastTextLen = lastText.length;
|
||||||
const currentText = item.text;
|
const currentText = item.text;
|
||||||
const newText = lastText + currentText;
|
const newText = lastText + currentText;
|
||||||
const newTextLen = newText.length;
|
const newTextLen = newText.length;
|
||||||
|
|
||||||
// Markdown 模式下,会强制向下拆分最小块,并再最后一个标题时候,给小块都补充上所有标题(包含父级标题)
|
// Markdown 模式下,会强制向下拆分最小块,并再最后一个标题深度,给小块都补充上所有标题(包含父级标题)
|
||||||
if (isMarkdownStep) {
|
if (isMarkdownStep) {
|
||||||
// split new Text, split chunks must will greater 1 (small lastText)
|
// split new Text, split chunks must will greater 1 (small lastText)
|
||||||
const innerChunks = splitTextRecursively({
|
const innerChunks = splitTextRecursively({
|
||||||
@@ -267,11 +297,13 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
parentTitle: parentTitle + item.title
|
parentTitle: parentTitle + item.title
|
||||||
});
|
});
|
||||||
|
|
||||||
|
// 只有标题,没有内容。
|
||||||
if (innerChunks.length === 0) {
|
if (innerChunks.length === 0) {
|
||||||
chunks.push(`${parentTitle}${item.title}`);
|
chunks.push(`${parentTitle}${item.title}`);
|
||||||
continue;
|
continue;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// 在合并最深级标题时,需要补充标题
|
||||||
chunks.push(
|
chunks.push(
|
||||||
...innerChunks.map(
|
...innerChunks.map(
|
||||||
(chunk) =>
|
(chunk) =>
|
||||||
@@ -282,9 +314,18 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
continue;
|
continue;
|
||||||
}
|
}
|
||||||
|
|
||||||
// newText is too large(now, The lastText must be smaller than chunkLen)
|
// newText is too large(now, The lastText must be smaller than chunkSize)
|
||||||
if (newTextLen > maxLen) {
|
if (newTextLen > maxLen) {
|
||||||
// lastText greater minChunkLen, direct push it to chunks, not add to next chunk. (large lastText)
|
const minChunkLen = maxLen * 0.8; // 当前块最小长度
|
||||||
|
const maxChunkLen = maxLen * 1.2; // 当前块最大长度
|
||||||
|
|
||||||
|
// 新文本没有非常大,直接认为它是一个新的块
|
||||||
|
if (newTextLen < maxChunkLen) {
|
||||||
|
chunks.push(newText);
|
||||||
|
lastText = getOneTextOverlapText({ text: newText, step }); // next chunk will start with overlayText
|
||||||
|
continue;
|
||||||
|
}
|
||||||
|
// 上一个文本块已经挺大的,单独做一个块
|
||||||
if (lastTextLen > minChunkLen) {
|
if (lastTextLen > minChunkLen) {
|
||||||
chunks.push(lastText);
|
chunks.push(lastText);
|
||||||
|
|
||||||
@@ -294,13 +335,13 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
continue;
|
continue;
|
||||||
}
|
}
|
||||||
|
|
||||||
// 说明是新的文本块比较大,需要进一步拆分
|
// 说明是当前文本比较大,需要进一步拆分
|
||||||
|
|
||||||
// split new Text, split chunks must will greater 1 (small lastText)
|
// 把新的文本块进行一个拆分,并追加到 latestText 中
|
||||||
const innerChunks = splitTextRecursively({
|
const innerChunks = splitTextRecursively({
|
||||||
text: newText,
|
text: currentText,
|
||||||
step: step + 1,
|
step: step + 1,
|
||||||
lastText: '',
|
lastText,
|
||||||
parentTitle: parentTitle + item.title
|
parentTitle: parentTitle + item.title
|
||||||
});
|
});
|
||||||
const lastChunk = innerChunks[innerChunks.length - 1];
|
const lastChunk = innerChunks[innerChunks.length - 1];
|
||||||
@@ -328,16 +369,16 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
|
|
||||||
// Not overlap
|
// Not overlap
|
||||||
if (forbidConcat) {
|
if (forbidConcat) {
|
||||||
chunks.push(item.text);
|
chunks.push(currentText);
|
||||||
continue;
|
continue;
|
||||||
}
|
}
|
||||||
|
|
||||||
lastText += item.text;
|
lastText = newText;
|
||||||
}
|
}
|
||||||
|
|
||||||
/* If the last chunk is independent, it needs to be push chunks. */
|
/* If the last chunk is independent, it needs to be push chunks. */
|
||||||
if (lastText && chunks[chunks.length - 1] && !chunks[chunks.length - 1].endsWith(lastText)) {
|
if (lastText && chunks[chunks.length - 1] && !chunks[chunks.length - 1].endsWith(lastText)) {
|
||||||
if (lastText.length < chunkLen * 0.4) {
|
if (lastText.length < chunkSize * 0.4) {
|
||||||
chunks[chunks.length - 1] = chunks[chunks.length - 1] + lastText;
|
chunks[chunks.length - 1] = chunks[chunks.length - 1] + lastText;
|
||||||
} else {
|
} else {
|
||||||
chunks.push(lastText);
|
chunks.push(lastText);
|
||||||
@@ -371,9 +412,9 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
|||||||
|
|
||||||
/**
|
/**
|
||||||
* text split into chunks
|
* text split into chunks
|
||||||
* chunkLen - one chunk len. max: 3500
|
* chunkSize - one chunk len. max: 3500
|
||||||
* overlapLen - The size of the before and after Text
|
* overlapLen - The size of the before and after Text
|
||||||
* chunkLen > overlapLen
|
* chunkSize > overlapLen
|
||||||
* markdown
|
* markdown
|
||||||
*/
|
*/
|
||||||
export const splitText2Chunks = (props: SplitProps): SplitResponse => {
|
export const splitText2Chunks = (props: SplitProps): SplitResponse => {
|
||||||
|
|||||||
@@ -56,7 +56,7 @@ export const replaceSensitiveText = (text: string) => {
|
|||||||
};
|
};
|
||||||
|
|
||||||
/* Make sure the first letter is definitely lowercase */
|
/* Make sure the first letter is definitely lowercase */
|
||||||
export const getNanoid = (size = 12) => {
|
export const getNanoid = (size = 16) => {
|
||||||
const firstChar = customAlphabet('abcdefghijklmnopqrstuvwxyz', 1)();
|
const firstChar = customAlphabet('abcdefghijklmnopqrstuvwxyz', 1)();
|
||||||
|
|
||||||
if (size === 1) return firstChar;
|
if (size === 1) return firstChar;
|
||||||
|
|||||||
@@ -6,7 +6,7 @@ import type {
|
|||||||
EmbeddingModelItemType,
|
EmbeddingModelItemType,
|
||||||
AudioSpeechModels,
|
AudioSpeechModels,
|
||||||
STTModelType,
|
STTModelType,
|
||||||
ReRankModelItemType
|
RerankModelItemType
|
||||||
} from '../../../core/ai/model.d';
|
} from '../../../core/ai/model.d';
|
||||||
import { SubTypeEnum } from '../../../support/wallet/sub/constants';
|
import { SubTypeEnum } from '../../../support/wallet/sub/constants';
|
||||||
|
|
||||||
@@ -35,7 +35,7 @@ export type FastGPTConfigFileType = {
|
|||||||
// Abandon
|
// Abandon
|
||||||
llmModels?: ChatModelItemType[];
|
llmModels?: ChatModelItemType[];
|
||||||
vectorModels?: EmbeddingModelItemType[];
|
vectorModels?: EmbeddingModelItemType[];
|
||||||
reRankModels?: ReRankModelItemType[];
|
reRankModels?: RerankModelItemType[];
|
||||||
audioSpeechModels?: TTSModelType[];
|
audioSpeechModels?: TTSModelType[];
|
||||||
whisperModel?: STTModelType;
|
whisperModel?: STTModelType;
|
||||||
};
|
};
|
||||||
@@ -84,11 +84,6 @@ export type FastGPTFeConfigsType = {
|
|||||||
github?: string;
|
github?: string;
|
||||||
google?: string;
|
google?: string;
|
||||||
wechat?: string;
|
wechat?: string;
|
||||||
dingtalk?: string;
|
|
||||||
wecom?: {
|
|
||||||
corpid?: string;
|
|
||||||
agentid?: string;
|
|
||||||
};
|
|
||||||
microsoft?: {
|
microsoft?: {
|
||||||
clientId?: string;
|
clientId?: string;
|
||||||
tenantId?: string;
|
tenantId?: string;
|
||||||
|
|||||||
2
packages/global/core/ai/model.d.ts
vendored
@@ -72,7 +72,7 @@ export type EmbeddingModelItemType = PriceType &
|
|||||||
queryConfig?: Record<string, any>; // Custom parameters for query
|
queryConfig?: Record<string, any>; // Custom parameters for query
|
||||||
};
|
};
|
||||||
|
|
||||||
export type ReRankModelItemType = PriceType &
|
export type RerankModelItemType = PriceType &
|
||||||
BaseModelItemType & {
|
BaseModelItemType & {
|
||||||
type: ModelTypeEnum.rerank;
|
type: ModelTypeEnum.rerank;
|
||||||
};
|
};
|
||||||
|
|||||||
@@ -1,54 +1,70 @@
|
|||||||
import { PromptTemplateItem } from '../type.d';
|
import { PromptTemplateItem } from '../type.d';
|
||||||
import { i18nT } from '../../../../web/i18n/utils';
|
import { i18nT } from '../../../../web/i18n/utils';
|
||||||
|
import { getPromptByVersion } from './utils';
|
||||||
|
|
||||||
export const Prompt_QuoteTemplateList: PromptTemplateItem[] = [
|
export const Prompt_QuoteTemplateList: PromptTemplateItem[] = [
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.standard_template'),
|
title: i18nT('app:template.standard_template'),
|
||||||
desc: i18nT('app:template.standard_template_des'),
|
desc: i18nT('app:template.standard_template_des'),
|
||||||
value: `{
|
value: {
|
||||||
|
['4.9.2']: `{
|
||||||
"sourceName": "{{source}}",
|
"sourceName": "{{source}}",
|
||||||
"updateTime": "{{updateTime}}",
|
"updateTime": "{{updateTime}}",
|
||||||
"content": "{{q}}\n{{a}}"
|
"content": "{{q}}\n{{a}}"
|
||||||
}
|
}
|
||||||
`
|
`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.qa_template'),
|
title: i18nT('app:template.qa_template'),
|
||||||
desc: i18nT('app:template.qa_template_des'),
|
desc: i18nT('app:template.qa_template_des'),
|
||||||
value: `<Question>
|
value: {
|
||||||
|
['4.9.2']: `<Question>
|
||||||
{{q}}
|
{{q}}
|
||||||
</Question>
|
</Question>
|
||||||
<Answer>
|
<Answer>
|
||||||
{{a}}
|
{{a}}
|
||||||
</Answer>`
|
</Answer>`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.standard_strict'),
|
title: i18nT('app:template.standard_strict'),
|
||||||
desc: i18nT('app:template.standard_strict_des'),
|
desc: i18nT('app:template.standard_strict_des'),
|
||||||
value: `{
|
value: {
|
||||||
|
['4.9.2']: `{
|
||||||
"sourceName": "{{source}}",
|
"sourceName": "{{source}}",
|
||||||
"updateTime": "{{updateTime}}",
|
"updateTime": "{{updateTime}}",
|
||||||
"content": "{{q}}\n{{a}}"
|
"content": "{{q}}\n{{a}}"
|
||||||
}
|
}
|
||||||
`
|
`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.hard_strict'),
|
title: i18nT('app:template.hard_strict'),
|
||||||
desc: i18nT('app:template.hard_strict_des'),
|
desc: i18nT('app:template.hard_strict_des'),
|
||||||
value: `<Question>
|
value: {
|
||||||
|
['4.9.2']: `<Question>
|
||||||
{{q}}
|
{{q}}
|
||||||
</Question>
|
</Question>
|
||||||
<Answer>
|
<Answer>
|
||||||
{{a}}
|
{{a}}
|
||||||
</Answer>`
|
</Answer>`
|
||||||
|
}
|
||||||
}
|
}
|
||||||
];
|
];
|
||||||
|
|
||||||
|
export const getQuoteTemplate = (version?: string) => {
|
||||||
|
const defaultTemplate = Prompt_QuoteTemplateList[0].value;
|
||||||
|
|
||||||
|
return getPromptByVersion(version, defaultTemplate);
|
||||||
|
};
|
||||||
|
|
||||||
export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.standard_template'),
|
title: i18nT('app:template.standard_template'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
value: {
|
||||||
|
['4.9.2']: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||||
|
|
||||||
<Reference>
|
<Reference>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -62,11 +78,13 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 使用与问题相同的语言回答。
|
- 使用与问题相同的语言回答。
|
||||||
|
|
||||||
问题:"""{{question}}"""`
|
问题:"""{{question}}"""`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.qa_template'),
|
title: i18nT('app:template.qa_template'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `使用 <QA></QA> 标记中的问答对进行回答。
|
value: {
|
||||||
|
['4.9.2']: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||||
|
|
||||||
<QA>
|
<QA>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -79,11 +97,13 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
||||||
|
|
||||||
问题:"""{{question}}"""`
|
问题:"""{{question}}"""`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.standard_strict'),
|
title: i18nT('app:template.standard_strict'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
value: {
|
||||||
|
['4.9.2']: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||||
|
|
||||||
<Reference>
|
<Reference>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -101,11 +121,13 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 使用与问题相同的语言回答。
|
- 使用与问题相同的语言回答。
|
||||||
|
|
||||||
问题:"""{{question}}"""`
|
问题:"""{{question}}"""`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.hard_strict'),
|
title: i18nT('app:template.hard_strict'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
value: {
|
||||||
|
['4.9.2']: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||||
|
|
||||||
<QA>
|
<QA>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -126,6 +148,7 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 使用与问题相同的语言回答。
|
- 使用与问题相同的语言回答。
|
||||||
|
|
||||||
问题:"""{{question}}"""`
|
问题:"""{{question}}"""`
|
||||||
|
}
|
||||||
}
|
}
|
||||||
];
|
];
|
||||||
|
|
||||||
@@ -133,7 +156,8 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
|||||||
{
|
{
|
||||||
title: i18nT('app:template.standard_template'),
|
title: i18nT('app:template.standard_template'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
value: {
|
||||||
|
['4.9.2']: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||||
|
|
||||||
<Reference>
|
<Reference>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -145,11 +169,13 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 保持答案与 <Reference></Reference> 中描述的一致。
|
- 保持答案与 <Reference></Reference> 中描述的一致。
|
||||||
- 使用 Markdown 语法优化回答格式。
|
- 使用 Markdown 语法优化回答格式。
|
||||||
- 使用与问题相同的语言回答。`
|
- 使用与问题相同的语言回答。`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.qa_template'),
|
title: i18nT('app:template.qa_template'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `使用 <QA></QA> 标记中的问答对进行回答。
|
value: {
|
||||||
|
['4.9.2']: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||||
|
|
||||||
<QA>
|
<QA>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -160,11 +186,13 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 回答的内容应尽可能与 <答案></答案> 中的内容一致。
|
- 回答的内容应尽可能与 <答案></答案> 中的内容一致。
|
||||||
- 如果没有相关的问答对,你需要澄清。
|
- 如果没有相关的问答对,你需要澄清。
|
||||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。`
|
- 避免提及你是从 QA 获取的知识,只需要回复答案。`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.standard_strict'),
|
title: i18nT('app:template.standard_strict'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
value: {
|
||||||
|
['4.9.2']: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||||
|
|
||||||
<Reference>
|
<Reference>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -180,11 +208,13 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 保持答案与 <Reference></Reference> 中描述的一致。
|
- 保持答案与 <Reference></Reference> 中描述的一致。
|
||||||
- 使用 Markdown 语法优化回答格式。
|
- 使用 Markdown 语法优化回答格式。
|
||||||
- 使用与问题相同的语言回答。`
|
- 使用与问题相同的语言回答。`
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
title: i18nT('app:template.hard_strict'),
|
title: i18nT('app:template.hard_strict'),
|
||||||
desc: '',
|
desc: '',
|
||||||
value: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
value: {
|
||||||
|
['4.9.2']: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||||
|
|
||||||
<QA>
|
<QA>
|
||||||
{{quote}}
|
{{quote}}
|
||||||
@@ -203,12 +233,28 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
|||||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
||||||
- 使用 Markdown 语法优化回答格式。
|
- 使用 Markdown 语法优化回答格式。
|
||||||
- 使用与问题相同的语言回答。`
|
- 使用与问题相同的语言回答。`
|
||||||
|
}
|
||||||
}
|
}
|
||||||
];
|
];
|
||||||
|
|
||||||
|
export const getQuotePrompt = (version?: string, role: 'user' | 'system' = 'user') => {
|
||||||
|
const quotePromptTemplates =
|
||||||
|
role === 'user' ? Prompt_userQuotePromptList : Prompt_systemQuotePromptList;
|
||||||
|
|
||||||
|
const defaultTemplate = quotePromptTemplates[0].value;
|
||||||
|
|
||||||
|
return getPromptByVersion(version, defaultTemplate);
|
||||||
|
};
|
||||||
|
|
||||||
// Document quote prompt
|
// Document quote prompt
|
||||||
export const Prompt_DocumentQuote = `将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
|
export const getDocumentQuotePrompt = (version: string) => {
|
||||||
<FilesContent>
|
const promptMap = {
|
||||||
{{quote}}
|
['4.9.2']: `将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
|
||||||
</FilesContent>
|
<FilesContent>
|
||||||
`;
|
{{quote}}
|
||||||
|
</FilesContent>
|
||||||
|
`
|
||||||
|
};
|
||||||
|
|
||||||
|
return getPromptByVersion(version, promptMap);
|
||||||
|
};
|
||||||
|
|||||||
@@ -1,3 +1,5 @@
|
|||||||
|
import { getPromptByVersion } from './utils';
|
||||||
|
|
||||||
export const Prompt_AgentQA = {
|
export const Prompt_AgentQA = {
|
||||||
description: `<Context></Context> 标记中是一段文本,学习和分析它,并整理学习成果:
|
description: `<Context></Context> 标记中是一段文本,学习和分析它,并整理学习成果:
|
||||||
- 提出问题并给出每个问题的答案。
|
- 提出问题并给出每个问题的答案。
|
||||||
@@ -25,7 +27,9 @@ A2:
|
|||||||
`
|
`
|
||||||
};
|
};
|
||||||
|
|
||||||
export const Prompt_ExtractJson = `你可以从 <对话记录></对话记录> 中提取指定 Json 信息,你仅需返回 Json 字符串,无需回答问题。
|
export const getExtractJsonPrompt = (version?: string) => {
|
||||||
|
const promptMap: Record<string, string> = {
|
||||||
|
['4.9.2']: `你可以从 <对话记录></对话记录> 中提取指定 Json 信息,你仅需返回 Json 字符串,无需回答问题。
|
||||||
<提取要求>
|
<提取要求>
|
||||||
{{description}}
|
{{description}}
|
||||||
</提取要求>
|
</提取要求>
|
||||||
@@ -44,9 +48,31 @@ export const Prompt_ExtractJson = `你可以从 <对话记录></对话记录>
|
|||||||
{{text}}
|
{{text}}
|
||||||
</对话记录>
|
</对话记录>
|
||||||
|
|
||||||
提取的 json 字符串:`;
|
提取的 json 字符串:`
|
||||||
|
};
|
||||||
|
|
||||||
export const Prompt_CQJson = `请帮我执行一个“问题分类”任务,将问题分类为以下几种类型之一:
|
return getPromptByVersion(version, promptMap);
|
||||||
|
};
|
||||||
|
|
||||||
|
export const getExtractJsonToolPrompt = (version?: string) => {
|
||||||
|
const promptMap: Record<string, string> = {
|
||||||
|
['4.9.2']: `我正在执行一个函数,需要你提供一些参数,请以 JSON 字符串格式返回这些参数,要求:
|
||||||
|
"""
|
||||||
|
- {{description}}
|
||||||
|
- 不是每个参数都是必须生成的,如果没有合适的参数值,不要生成该参数,或返回空字符串。
|
||||||
|
- 需要结合前面的对话内容,一起生成合适的参数。
|
||||||
|
"""
|
||||||
|
|
||||||
|
本次输入内容: """{{content}}"""
|
||||||
|
`
|
||||||
|
};
|
||||||
|
|
||||||
|
return getPromptByVersion(version, promptMap);
|
||||||
|
};
|
||||||
|
|
||||||
|
export const getCQPrompt = (version?: string) => {
|
||||||
|
const promptMap: Record<string, string> = {
|
||||||
|
['4.9.2']: `请帮我执行一个"问题分类"任务,将问题分类为以下几种类型之一:
|
||||||
|
|
||||||
"""
|
"""
|
||||||
{{typeList}}
|
{{typeList}}
|
||||||
@@ -64,9 +90,13 @@ export const Prompt_CQJson = `请帮我执行一个“问题分类”任务,
|
|||||||
|
|
||||||
问题:"{{question}}"
|
问题:"{{question}}"
|
||||||
类型ID=
|
类型ID=
|
||||||
`;
|
`
|
||||||
|
};
|
||||||
|
|
||||||
export const PROMPT_QUESTION_GUIDE = `You are an AI assistant tasked with predicting the user's next question based on the conversation history. Your goal is to generate 3 potential questions that will guide the user to continue the conversation. When generating these questions, adhere to the following rules:
|
return getPromptByVersion(version, promptMap);
|
||||||
|
};
|
||||||
|
|
||||||
|
export const QuestionGuidePrompt = `You are an AI assistant tasked with predicting the user's next question based on the conversation history. Your goal is to generate 3 potential questions that will guide the user to continue the conversation. When generating these questions, adhere to the following rules:
|
||||||
|
|
||||||
1. Use the same language as the user's last question in the conversation history.
|
1. Use the same language as the user's last question in the conversation history.
|
||||||
2. Keep each question under 20 characters in length.
|
2. Keep each question under 20 characters in length.
|
||||||
@@ -74,4 +104,5 @@ export const PROMPT_QUESTION_GUIDE = `You are an AI assistant tasked with predic
|
|||||||
Analyze the conversation history provided to you and use it as context to generate relevant and engaging follow-up questions. Your predictions should be logical extensions of the current topic or related areas that the user might be interested in exploring further.
|
Analyze the conversation history provided to you and use it as context to generate relevant and engaging follow-up questions. Your predictions should be logical extensions of the current topic or related areas that the user might be interested in exploring further.
|
||||||
|
|
||||||
Remember to maintain consistency in tone and style with the existing conversation while providing diverse options for the user to choose from. Your goal is to keep the conversation flowing naturally and help the user delve deeper into the subject matter or explore related topics.`;
|
Remember to maintain consistency in tone and style with the existing conversation while providing diverse options for the user to choose from. Your goal is to keep the conversation flowing naturally and help the user delve deeper into the subject matter or explore related topics.`;
|
||||||
export const PROMPT_QUESTION_GUIDE_FOOTER = `Please strictly follow the format rules: \nReturn questions in JSON format: ['Question 1', 'Question 2', 'Question 3']. Your output: `;
|
|
||||||
|
export const QuestionGuideFooterPrompt = `Please strictly follow the format rules: \nReturn questions in JSON format: ['Question 1', 'Question 2', 'Question 3']. Your output: `;
|
||||||
|
|||||||
19
packages/global/core/ai/prompt/utils.ts
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
export const getPromptByVersion = (version?: string, promptMap: Record<string, string> = {}) => {
|
||||||
|
const versions = Object.keys(promptMap).sort((a, b) => {
|
||||||
|
const [majorA, minorA, patchA] = a.split('.').map(Number);
|
||||||
|
const [majorB, minorB, patchB] = b.split('.').map(Number);
|
||||||
|
|
||||||
|
if (majorA !== majorB) return majorB - majorA;
|
||||||
|
if (minorA !== minorB) return minorB - minorA;
|
||||||
|
return patchB - patchA;
|
||||||
|
});
|
||||||
|
|
||||||
|
if (!version) {
|
||||||
|
return promptMap[versions[0]];
|
||||||
|
}
|
||||||
|
|
||||||
|
if (version in promptMap) {
|
||||||
|
return promptMap[version];
|
||||||
|
}
|
||||||
|
return promptMap[versions[versions.length - 1]];
|
||||||
|
};
|
||||||
2
packages/global/core/ai/type.d.ts
vendored
@@ -80,5 +80,5 @@ export * from 'openai';
|
|||||||
export type PromptTemplateItem = {
|
export type PromptTemplateItem = {
|
||||||
title: string;
|
title: string;
|
||||||
desc: string;
|
desc: string;
|
||||||
value: string;
|
value: Record<string, string>;
|
||||||
};
|
};
|
||||||
|
|||||||
@@ -1,4 +1,3 @@
|
|||||||
import { PROMPT_QUESTION_GUIDE } from '../ai/prompt/agent';
|
|
||||||
import {
|
import {
|
||||||
AppTTSConfigType,
|
AppTTSConfigType,
|
||||||
AppFileSelectConfigType,
|
AppFileSelectConfigType,
|
||||||
|
|||||||
23
packages/global/core/app/type.d.ts
vendored
@@ -71,6 +71,20 @@ export type AppDetailType = AppSchema & {
|
|||||||
permission: AppPermission;
|
permission: AppPermission;
|
||||||
};
|
};
|
||||||
|
|
||||||
|
export type AppDatasetSearchParamsType = {
|
||||||
|
searchMode: `${DatasetSearchModeEnum}`;
|
||||||
|
limit?: number; // limit max tokens
|
||||||
|
similarity?: number;
|
||||||
|
embeddingWeight?: number; // embedding weight, fullText weight = 1 - embeddingWeight
|
||||||
|
|
||||||
|
usingReRank?: boolean;
|
||||||
|
rerankModel?: string;
|
||||||
|
rerankWeight?: number;
|
||||||
|
|
||||||
|
datasetSearchUsingExtensionQuery?: boolean;
|
||||||
|
datasetSearchExtensionModel?: string;
|
||||||
|
datasetSearchExtensionBg?: string;
|
||||||
|
};
|
||||||
export type AppSimpleEditFormType = {
|
export type AppSimpleEditFormType = {
|
||||||
// templateId: string;
|
// templateId: string;
|
||||||
aiSettings: {
|
aiSettings: {
|
||||||
@@ -88,14 +102,7 @@ export type AppSimpleEditFormType = {
|
|||||||
};
|
};
|
||||||
dataset: {
|
dataset: {
|
||||||
datasets: SelectedDatasetType;
|
datasets: SelectedDatasetType;
|
||||||
searchMode: `${DatasetSearchModeEnum}`;
|
} & AppDatasetSearchParamsType;
|
||||||
similarity?: number;
|
|
||||||
limit?: number;
|
|
||||||
usingReRank?: boolean;
|
|
||||||
datasetSearchUsingExtensionQuery?: boolean;
|
|
||||||
datasetSearchExtensionModel?: string;
|
|
||||||
datasetSearchExtensionBg?: string;
|
|
||||||
};
|
|
||||||
selectedTools: FlowNodeTemplateType[];
|
selectedTools: FlowNodeTemplateType[];
|
||||||
chatConfig: AppChatConfigType;
|
chatConfig: AppChatConfigType;
|
||||||
};
|
};
|
||||||
|
|||||||
@@ -24,9 +24,11 @@ export const getDefaultAppForm = (): AppSimpleEditFormType => {
|
|||||||
dataset: {
|
dataset: {
|
||||||
datasets: [],
|
datasets: [],
|
||||||
similarity: 0.4,
|
similarity: 0.4,
|
||||||
limit: 1500,
|
limit: 3000,
|
||||||
searchMode: DatasetSearchModeEnum.embedding,
|
searchMode: DatasetSearchModeEnum.embedding,
|
||||||
usingReRank: false,
|
usingReRank: false,
|
||||||
|
rerankModel: '',
|
||||||
|
rerankWeight: 0.5,
|
||||||
datasetSearchUsingExtensionQuery: true,
|
datasetSearchUsingExtensionQuery: true,
|
||||||
datasetSearchExtensionBg: ''
|
datasetSearchExtensionBg: ''
|
||||||
},
|
},
|
||||||
@@ -70,6 +72,26 @@ export const appWorkflow2Form = ({
|
|||||||
node.inputs,
|
node.inputs,
|
||||||
NodeInputKeyEnum.history
|
NodeInputKeyEnum.history
|
||||||
);
|
);
|
||||||
|
defaultAppForm.aiSettings.aiChatReasoning = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.aiChatReasoning
|
||||||
|
);
|
||||||
|
defaultAppForm.aiSettings.aiChatTopP = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.aiChatTopP
|
||||||
|
);
|
||||||
|
defaultAppForm.aiSettings.aiChatStopSign = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.aiChatStopSign
|
||||||
|
);
|
||||||
|
defaultAppForm.aiSettings.aiChatResponseFormat = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.aiChatResponseFormat
|
||||||
|
);
|
||||||
|
defaultAppForm.aiSettings.aiChatJsonSchema = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.aiChatJsonSchema
|
||||||
|
);
|
||||||
} else if (node.flowNodeType === FlowNodeTypeEnum.datasetSearchNode) {
|
} else if (node.flowNodeType === FlowNodeTypeEnum.datasetSearchNode) {
|
||||||
defaultAppForm.dataset.datasets = findInputValueByKey(
|
defaultAppForm.dataset.datasets = findInputValueByKey(
|
||||||
node.inputs,
|
node.inputs,
|
||||||
@@ -86,10 +108,24 @@ export const appWorkflow2Form = ({
|
|||||||
defaultAppForm.dataset.searchMode =
|
defaultAppForm.dataset.searchMode =
|
||||||
findInputValueByKey(node.inputs, NodeInputKeyEnum.datasetSearchMode) ||
|
findInputValueByKey(node.inputs, NodeInputKeyEnum.datasetSearchMode) ||
|
||||||
DatasetSearchModeEnum.embedding;
|
DatasetSearchModeEnum.embedding;
|
||||||
|
defaultAppForm.dataset.embeddingWeight = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.datasetSearchEmbeddingWeight
|
||||||
|
);
|
||||||
|
// Rerank
|
||||||
defaultAppForm.dataset.usingReRank = !!findInputValueByKey(
|
defaultAppForm.dataset.usingReRank = !!findInputValueByKey(
|
||||||
node.inputs,
|
node.inputs,
|
||||||
NodeInputKeyEnum.datasetSearchUsingReRank
|
NodeInputKeyEnum.datasetSearchUsingReRank
|
||||||
);
|
);
|
||||||
|
defaultAppForm.dataset.rerankModel = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.datasetSearchRerankModel
|
||||||
|
);
|
||||||
|
defaultAppForm.dataset.rerankWeight = findInputValueByKey(
|
||||||
|
node.inputs,
|
||||||
|
NodeInputKeyEnum.datasetSearchRerankWeight
|
||||||
|
);
|
||||||
|
// Query extension
|
||||||
defaultAppForm.dataset.datasetSearchUsingExtensionQuery = findInputValueByKey(
|
defaultAppForm.dataset.datasetSearchUsingExtensionQuery = findInputValueByKey(
|
||||||
node.inputs,
|
node.inputs,
|
||||||
NodeInputKeyEnum.datasetSearchUsingExtensionQuery
|
NodeInputKeyEnum.datasetSearchUsingExtensionQuery
|
||||||
|
|||||||
@@ -256,7 +256,7 @@ export const GPTMessages2Chats = (
|
|||||||
) {
|
) {
|
||||||
const value: AIChatItemValueItemType[] = [];
|
const value: AIChatItemValueItemType[] = [];
|
||||||
|
|
||||||
if (typeof item.reasoning_text === 'string') {
|
if (typeof item.reasoning_text === 'string' && item.reasoning_text) {
|
||||||
value.push({
|
value.push({
|
||||||
type: ChatItemValueTypeEnum.reasoning,
|
type: ChatItemValueTypeEnum.reasoning,
|
||||||
reasoning: {
|
reasoning: {
|
||||||
@@ -323,7 +323,7 @@ export const GPTMessages2Chats = (
|
|||||||
interactive: item.interactive
|
interactive: item.interactive
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
if (typeof item.content === 'string') {
|
if (typeof item.content === 'string' && item.content) {
|
||||||
const lastValue = value[value.length - 1];
|
const lastValue = value[value.length - 1];
|
||||||
if (lastValue && lastValue.type === ChatItemValueTypeEnum.text && lastValue.text) {
|
if (lastValue && lastValue.type === ChatItemValueTypeEnum.text && lastValue.text) {
|
||||||
lastValue.text.content += item.content;
|
lastValue.text.content += item.content;
|
||||||
|
|||||||
1
packages/global/core/chat/type.d.ts
vendored
@@ -134,6 +134,7 @@ export type ChatItemType = (UserChatItemType | SystemChatItemType | AIChatItemTy
|
|||||||
|
|
||||||
// Frontend type
|
// Frontend type
|
||||||
export type ChatSiteItemType = (UserChatItemType | SystemChatItemType | AIChatItemType) & {
|
export type ChatSiteItemType = (UserChatItemType | SystemChatItemType | AIChatItemType) & {
|
||||||
|
_id?: string;
|
||||||
dataId: string;
|
dataId: string;
|
||||||
status: `${ChatStatusEnum}`;
|
status: `${ChatStatusEnum}`;
|
||||||
moduleName?: string;
|
moduleName?: string;
|
||||||
|
|||||||
13
packages/global/core/dataset/api.d.ts
vendored
@@ -1,5 +1,10 @@
|
|||||||
import { DatasetDataIndexItemType, DatasetSchemaType } from './type';
|
import { DatasetDataIndexItemType, DatasetSchemaType } from './type';
|
||||||
import { DatasetCollectionTypeEnum, DatasetCollectionDataProcessModeEnum } from './constants';
|
import {
|
||||||
|
DatasetCollectionTypeEnum,
|
||||||
|
DatasetCollectionDataProcessModeEnum,
|
||||||
|
ChunkSettingModeEnum,
|
||||||
|
DataChunkSplitModeEnum
|
||||||
|
} from './constants';
|
||||||
import type { LLMModelItemType } from '../ai/model.d';
|
import type { LLMModelItemType } from '../ai/model.d';
|
||||||
import { ParentIdType } from 'common/parentFolder/type';
|
import { ParentIdType } from 'common/parentFolder/type';
|
||||||
|
|
||||||
@@ -33,7 +38,13 @@ export type DatasetCollectionChunkMetadataType = {
|
|||||||
trainingType?: DatasetCollectionDataProcessModeEnum;
|
trainingType?: DatasetCollectionDataProcessModeEnum;
|
||||||
imageIndex?: boolean;
|
imageIndex?: boolean;
|
||||||
autoIndexes?: boolean;
|
autoIndexes?: boolean;
|
||||||
|
|
||||||
|
chunkSettingMode?: ChunkSettingModeEnum;
|
||||||
|
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||||
|
|
||||||
chunkSize?: number;
|
chunkSize?: number;
|
||||||
|
indexSize?: number;
|
||||||
|
|
||||||
chunkSplitter?: string;
|
chunkSplitter?: string;
|
||||||
qaPrompt?: string;
|
qaPrompt?: string;
|
||||||
metadata?: Record<string, any>;
|
metadata?: Record<string, any>;
|
||||||
|
|||||||
8
packages/global/core/dataset/apiDataset.d.ts
vendored
@@ -1,3 +1,5 @@
|
|||||||
|
import { RequireOnlyOne } from '../../common/type/utils';
|
||||||
|
|
||||||
export type APIFileItem = {
|
export type APIFileItem = {
|
||||||
id: string;
|
id: string;
|
||||||
parentId: string | null;
|
parentId: string | null;
|
||||||
@@ -15,9 +17,9 @@ export type APIFileServer = {
|
|||||||
|
|
||||||
export type APIFileListResponse = APIFileItem[];
|
export type APIFileListResponse = APIFileItem[];
|
||||||
|
|
||||||
export type APIFileContentResponse = {
|
export type ApiFileReadContentResponse = {
|
||||||
content?: string;
|
title?: string;
|
||||||
previewUrl?: string;
|
rawText: string;
|
||||||
};
|
};
|
||||||
|
|
||||||
export type APIFileReadResponse = {
|
export type APIFileReadResponse = {
|
||||||
|
|||||||
@@ -16,3 +16,7 @@ export const getCollectionSourceData = (collection?: DatasetCollectionSchemaType
|
|||||||
export const checkCollectionIsFolder = (type: DatasetCollectionTypeEnum) => {
|
export const checkCollectionIsFolder = (type: DatasetCollectionTypeEnum) => {
|
||||||
return type === DatasetCollectionTypeEnum.folder || type === DatasetCollectionTypeEnum.virtual;
|
return type === DatasetCollectionTypeEnum.folder || type === DatasetCollectionTypeEnum.virtual;
|
||||||
};
|
};
|
||||||
|
|
||||||
|
export const collectionCanSync = (type: DatasetCollectionTypeEnum) => {
|
||||||
|
return [DatasetCollectionTypeEnum.link, DatasetCollectionTypeEnum.apiFile].includes(type);
|
||||||
|
};
|
||||||
|
|||||||
@@ -13,38 +13,38 @@ export enum DatasetTypeEnum {
|
|||||||
export const DatasetTypeMap = {
|
export const DatasetTypeMap = {
|
||||||
[DatasetTypeEnum.folder]: {
|
[DatasetTypeEnum.folder]: {
|
||||||
icon: 'common/folderFill',
|
icon: 'common/folderFill',
|
||||||
label: 'folder_dataset',
|
label: i18nT('dataset:folder_dataset'),
|
||||||
collectionLabel: 'common.Folder'
|
collectionLabel: i18nT('common:Folder')
|
||||||
},
|
},
|
||||||
[DatasetTypeEnum.dataset]: {
|
[DatasetTypeEnum.dataset]: {
|
||||||
icon: 'core/dataset/commonDatasetOutline',
|
icon: 'core/dataset/commonDatasetOutline',
|
||||||
label: 'common_dataset',
|
label: i18nT('dataset:common_dataset'),
|
||||||
collectionLabel: 'common.File'
|
collectionLabel: i18nT('common:common.File')
|
||||||
},
|
},
|
||||||
[DatasetTypeEnum.websiteDataset]: {
|
[DatasetTypeEnum.websiteDataset]: {
|
||||||
icon: 'core/dataset/websiteDatasetOutline',
|
icon: 'core/dataset/websiteDatasetOutline',
|
||||||
label: 'website_dataset',
|
label: i18nT('dataset:website_dataset'),
|
||||||
collectionLabel: 'common.Website'
|
collectionLabel: i18nT('common:common.Website')
|
||||||
},
|
},
|
||||||
[DatasetTypeEnum.externalFile]: {
|
[DatasetTypeEnum.externalFile]: {
|
||||||
icon: 'core/dataset/externalDatasetOutline',
|
icon: 'core/dataset/externalDatasetOutline',
|
||||||
label: 'external_file',
|
label: i18nT('dataset:external_file'),
|
||||||
collectionLabel: 'common.File'
|
collectionLabel: i18nT('common:common.File')
|
||||||
},
|
},
|
||||||
[DatasetTypeEnum.apiDataset]: {
|
[DatasetTypeEnum.apiDataset]: {
|
||||||
icon: 'core/dataset/externalDatasetOutline',
|
icon: 'core/dataset/externalDatasetOutline',
|
||||||
label: 'api_file',
|
label: i18nT('dataset:api_file'),
|
||||||
collectionLabel: 'common.File'
|
collectionLabel: i18nT('common:common.File')
|
||||||
},
|
},
|
||||||
[DatasetTypeEnum.feishu]: {
|
[DatasetTypeEnum.feishu]: {
|
||||||
icon: 'core/dataset/feishuDatasetOutline',
|
icon: 'core/dataset/feishuDatasetOutline',
|
||||||
label: 'feishu_dataset',
|
label: i18nT('dataset:feishu_dataset'),
|
||||||
collectionLabel: 'common.File'
|
collectionLabel: i18nT('common:common.File')
|
||||||
},
|
},
|
||||||
[DatasetTypeEnum.yuque]: {
|
[DatasetTypeEnum.yuque]: {
|
||||||
icon: 'core/dataset/yuqueDatasetOutline',
|
icon: 'core/dataset/yuqueDatasetOutline',
|
||||||
label: 'yuque_dataset',
|
label: i18nT('dataset:yuque_dataset'),
|
||||||
collectionLabel: 'common.File'
|
collectionLabel: i18nT('common:common.File')
|
||||||
}
|
}
|
||||||
};
|
};
|
||||||
|
|
||||||
@@ -129,6 +129,16 @@ export const DatasetCollectionDataProcessModeMap = {
|
|||||||
}
|
}
|
||||||
};
|
};
|
||||||
|
|
||||||
|
export enum ChunkSettingModeEnum {
|
||||||
|
auto = 'auto',
|
||||||
|
custom = 'custom'
|
||||||
|
}
|
||||||
|
|
||||||
|
export enum DataChunkSplitModeEnum {
|
||||||
|
size = 'size',
|
||||||
|
char = 'char'
|
||||||
|
}
|
||||||
|
|
||||||
/* ------------ data -------------- */
|
/* ------------ data -------------- */
|
||||||
|
|
||||||
/* ------------ training -------------- */
|
/* ------------ training -------------- */
|
||||||
@@ -185,7 +195,7 @@ export enum SearchScoreTypeEnum {
|
|||||||
}
|
}
|
||||||
export const SearchScoreTypeMap = {
|
export const SearchScoreTypeMap = {
|
||||||
[SearchScoreTypeEnum.embedding]: {
|
[SearchScoreTypeEnum.embedding]: {
|
||||||
label: i18nT('common:core.dataset.search.score.embedding'),
|
label: i18nT('common:core.dataset.search.mode.embedding'),
|
||||||
desc: i18nT('common:core.dataset.search.score.embedding desc'),
|
desc: i18nT('common:core.dataset.search.score.embedding desc'),
|
||||||
showScore: true
|
showScore: true
|
||||||
},
|
},
|
||||||
|
|||||||
1
packages/global/core/dataset/controller.d.ts
vendored
@@ -13,6 +13,7 @@ export type CreateDatasetDataProps = {
|
|||||||
|
|
||||||
export type UpdateDatasetDataProps = {
|
export type UpdateDatasetDataProps = {
|
||||||
dataId: string;
|
dataId: string;
|
||||||
|
|
||||||
q?: string;
|
q?: string;
|
||||||
a?: string;
|
a?: string;
|
||||||
indexes?: (Omit<DatasetDataIndexItemType, 'dataId'> & {
|
indexes?: (Omit<DatasetDataIndexItemType, 'dataId'> & {
|
||||||
|
|||||||
@@ -16,23 +16,23 @@ export const DatasetDataIndexMap: Record<
|
|||||||
}
|
}
|
||||||
> = {
|
> = {
|
||||||
[DatasetDataIndexTypeEnum.default]: {
|
[DatasetDataIndexTypeEnum.default]: {
|
||||||
label: i18nT('dataset:data_index_default'),
|
label: i18nT('common:data_index_default'),
|
||||||
color: 'gray'
|
color: 'gray'
|
||||||
},
|
},
|
||||||
[DatasetDataIndexTypeEnum.custom]: {
|
[DatasetDataIndexTypeEnum.custom]: {
|
||||||
label: i18nT('dataset:data_index_custom'),
|
label: i18nT('common:data_index_custom'),
|
||||||
color: 'blue'
|
color: 'blue'
|
||||||
},
|
},
|
||||||
[DatasetDataIndexTypeEnum.summary]: {
|
[DatasetDataIndexTypeEnum.summary]: {
|
||||||
label: i18nT('dataset:data_index_summary'),
|
label: i18nT('common:data_index_summary'),
|
||||||
color: 'green'
|
color: 'green'
|
||||||
},
|
},
|
||||||
[DatasetDataIndexTypeEnum.question]: {
|
[DatasetDataIndexTypeEnum.question]: {
|
||||||
label: i18nT('dataset:data_index_question'),
|
label: i18nT('common:data_index_question'),
|
||||||
color: 'red'
|
color: 'red'
|
||||||
},
|
},
|
||||||
[DatasetDataIndexTypeEnum.image]: {
|
[DatasetDataIndexTypeEnum.image]: {
|
||||||
label: i18nT('dataset:data_index_image'),
|
label: i18nT('common:data_index_image'),
|
||||||
color: 'purple'
|
color: 'purple'
|
||||||
}
|
}
|
||||||
};
|
};
|
||||||
|
|||||||
@@ -15,6 +15,8 @@ export type PushDataToTrainingQueueProps = {
|
|||||||
vectorModel: string;
|
vectorModel: string;
|
||||||
vlmModel?: string;
|
vlmModel?: string;
|
||||||
|
|
||||||
|
indexSize?: number;
|
||||||
|
|
||||||
billId?: string;
|
billId?: string;
|
||||||
session?: ClientSession;
|
session?: ClientSession;
|
||||||
};
|
};
|
||||||
|
|||||||
136
packages/global/core/dataset/training/utils.ts
Normal file
@@ -0,0 +1,136 @@
|
|||||||
|
import { EmbeddingModelItemType, LLMModelItemType } from '../../../core/ai/model.d';
|
||||||
|
import {
|
||||||
|
ChunkSettingModeEnum,
|
||||||
|
DataChunkSplitModeEnum,
|
||||||
|
DatasetCollectionDataProcessModeEnum
|
||||||
|
} from '../constants';
|
||||||
|
|
||||||
|
export const minChunkSize = 64; // min index and chunk size
|
||||||
|
|
||||||
|
// Chunk size
|
||||||
|
export const chunkAutoChunkSize = 1500;
|
||||||
|
export const getMaxChunkSize = (model: LLMModelItemType) => {
|
||||||
|
return Math.max(model.maxContext - model.maxResponse, 2000);
|
||||||
|
};
|
||||||
|
|
||||||
|
// QA
|
||||||
|
export const defaultMaxChunkSize = 8000;
|
||||||
|
export const getLLMDefaultChunkSize = (model?: LLMModelItemType) => {
|
||||||
|
if (!model) return defaultMaxChunkSize;
|
||||||
|
return Math.max(Math.min(model.maxContext - model.maxResponse, defaultMaxChunkSize), 2000);
|
||||||
|
};
|
||||||
|
|
||||||
|
export const getLLMMaxChunkSize = (model?: LLMModelItemType) => {
|
||||||
|
if (!model) return 8000;
|
||||||
|
return Math.max(model.maxContext - model.maxResponse, 2000);
|
||||||
|
};
|
||||||
|
|
||||||
|
// Index size
|
||||||
|
export const getMaxIndexSize = (model?: EmbeddingModelItemType) => {
|
||||||
|
return model?.maxToken || 512;
|
||||||
|
};
|
||||||
|
export const getAutoIndexSize = (model?: EmbeddingModelItemType) => {
|
||||||
|
return model?.defaultToken || 512;
|
||||||
|
};
|
||||||
|
|
||||||
|
const indexSizeSelectList = [
|
||||||
|
{
|
||||||
|
label: '64',
|
||||||
|
value: 64
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '128',
|
||||||
|
value: 128
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '256',
|
||||||
|
value: 256
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '512',
|
||||||
|
value: 512
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '768',
|
||||||
|
value: 768
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '1024',
|
||||||
|
value: 1024
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '1536',
|
||||||
|
value: 1536
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '2048',
|
||||||
|
value: 2048
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '3072',
|
||||||
|
value: 3072
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '4096',
|
||||||
|
value: 4096
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '5120',
|
||||||
|
value: 5120
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '6144',
|
||||||
|
value: 6144
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '7168',
|
||||||
|
value: 7168
|
||||||
|
},
|
||||||
|
{
|
||||||
|
label: '8192',
|
||||||
|
value: 8192
|
||||||
|
}
|
||||||
|
];
|
||||||
|
export const getIndexSizeSelectList = (max = 512) => {
|
||||||
|
return indexSizeSelectList.filter((item) => item.value <= max);
|
||||||
|
};
|
||||||
|
|
||||||
|
// Compute
|
||||||
|
export const computeChunkSize = (params: {
|
||||||
|
trainingType: DatasetCollectionDataProcessModeEnum;
|
||||||
|
chunkSettingMode?: ChunkSettingModeEnum;
|
||||||
|
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||||
|
llmModel?: LLMModelItemType;
|
||||||
|
chunkSize?: number;
|
||||||
|
}) => {
|
||||||
|
if (params.trainingType === DatasetCollectionDataProcessModeEnum.qa) {
|
||||||
|
if (params.chunkSettingMode === ChunkSettingModeEnum.auto) {
|
||||||
|
return getLLMDefaultChunkSize(params.llmModel);
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
// chunk
|
||||||
|
if (params.chunkSettingMode === ChunkSettingModeEnum.auto) {
|
||||||
|
return chunkAutoChunkSize;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if (params.chunkSplitMode === DataChunkSplitModeEnum.char) {
|
||||||
|
return getLLMMaxChunkSize(params.llmModel);
|
||||||
|
}
|
||||||
|
|
||||||
|
return Math.min(params.chunkSize || chunkAutoChunkSize, getLLMMaxChunkSize(params.llmModel));
|
||||||
|
};
|
||||||
|
|
||||||
|
export const computeChunkSplitter = (params: {
|
||||||
|
chunkSettingMode?: ChunkSettingModeEnum;
|
||||||
|
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||||
|
chunkSplitter?: string;
|
||||||
|
}) => {
|
||||||
|
if (params.chunkSettingMode === ChunkSettingModeEnum.auto) {
|
||||||
|
return undefined;
|
||||||
|
}
|
||||||
|
if (params.chunkSplitMode === DataChunkSplitModeEnum.size) {
|
||||||
|
return undefined;
|
||||||
|
}
|
||||||
|
return params.chunkSplitter;
|
||||||
|
};
|
||||||
16
packages/global/core/dataset/type.d.ts
vendored
@@ -2,6 +2,7 @@ import type { LLMModelItemType, EmbeddingModelItemType } from '../../core/ai/mod
|
|||||||
import { PermissionTypeEnum } from '../../support/permission/constant';
|
import { PermissionTypeEnum } from '../../support/permission/constant';
|
||||||
import { PushDatasetDataChunkProps } from './api';
|
import { PushDatasetDataChunkProps } from './api';
|
||||||
import {
|
import {
|
||||||
|
DataChunkSplitModeEnum,
|
||||||
DatasetCollectionDataProcessModeEnum,
|
DatasetCollectionDataProcessModeEnum,
|
||||||
DatasetCollectionTypeEnum,
|
DatasetCollectionTypeEnum,
|
||||||
DatasetStatusEnum,
|
DatasetStatusEnum,
|
||||||
@@ -14,6 +15,7 @@ import { Permission } from '../../support/permission/controller';
|
|||||||
import { APIFileServer, FeishuServer, YuqueServer } from './apiDataset';
|
import { APIFileServer, FeishuServer, YuqueServer } from './apiDataset';
|
||||||
import { SourceMemberType } from 'support/user/type';
|
import { SourceMemberType } from 'support/user/type';
|
||||||
import { DatasetDataIndexTypeEnum } from './data/constants';
|
import { DatasetDataIndexTypeEnum } from './data/constants';
|
||||||
|
import { ChunkSettingModeEnum } from './constants';
|
||||||
|
|
||||||
export type DatasetSchemaType = {
|
export type DatasetSchemaType = {
|
||||||
_id: string;
|
_id: string;
|
||||||
@@ -88,7 +90,12 @@ export type DatasetCollectionSchemaType = {
|
|||||||
autoIndexes?: boolean;
|
autoIndexes?: boolean;
|
||||||
imageIndex?: boolean;
|
imageIndex?: boolean;
|
||||||
trainingType: DatasetCollectionDataProcessModeEnum;
|
trainingType: DatasetCollectionDataProcessModeEnum;
|
||||||
chunkSize: number;
|
|
||||||
|
chunkSettingMode?: ChunkSettingModeEnum;
|
||||||
|
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||||
|
|
||||||
|
chunkSize?: number;
|
||||||
|
indexSize?: number;
|
||||||
chunkSplitter?: string;
|
chunkSplitter?: string;
|
||||||
qaPrompt?: string;
|
qaPrompt?: string;
|
||||||
};
|
};
|
||||||
@@ -112,12 +119,15 @@ export type DatasetDataSchemaType = {
|
|||||||
tmbId: string;
|
tmbId: string;
|
||||||
datasetId: string;
|
datasetId: string;
|
||||||
collectionId: string;
|
collectionId: string;
|
||||||
datasetId: string;
|
|
||||||
collectionId: string;
|
|
||||||
chunkIndex: number;
|
chunkIndex: number;
|
||||||
updateTime: Date;
|
updateTime: Date;
|
||||||
q: string; // large chunks or question
|
q: string; // large chunks or question
|
||||||
a: string; // answer or custom content
|
a: string; // answer or custom content
|
||||||
|
history?: {
|
||||||
|
q: string;
|
||||||
|
a: string;
|
||||||
|
updateTime: Date;
|
||||||
|
}[];
|
||||||
forbid?: boolean;
|
forbid?: boolean;
|
||||||
fullTextToken: string;
|
fullTextToken: string;
|
||||||
indexes: DatasetDataIndexItemType[];
|
indexes: DatasetDataIndexItemType[];
|
||||||
|
|||||||
@@ -1,7 +1,6 @@
|
|||||||
import { TrainingModeEnum, DatasetCollectionTypeEnum } from './constants';
|
import { TrainingModeEnum, DatasetCollectionTypeEnum } from './constants';
|
||||||
import { getFileIcon } from '../../common/file/icon';
|
import { getFileIcon } from '../../common/file/icon';
|
||||||
import { strIsLink } from '../../common/string/tools';
|
import { strIsLink } from '../../common/string/tools';
|
||||||
import { DatasetDataIndexTypeEnum } from './data/constants';
|
|
||||||
|
|
||||||
export function getCollectionIcon(
|
export function getCollectionIcon(
|
||||||
type: DatasetCollectionTypeEnum = DatasetCollectionTypeEnum.file,
|
type: DatasetCollectionTypeEnum = DatasetCollectionTypeEnum.file,
|
||||||
@@ -38,26 +37,6 @@ export function getSourceNameIcon({
|
|||||||
return 'file/fill/file';
|
return 'file/fill/file';
|
||||||
}
|
}
|
||||||
|
|
||||||
/* get dataset data default index */
|
|
||||||
export function getDefaultIndex(props?: { q?: string; a?: string }) {
|
|
||||||
const { q = '', a } = props || {};
|
|
||||||
|
|
||||||
return [
|
|
||||||
{
|
|
||||||
text: q,
|
|
||||||
type: DatasetDataIndexTypeEnum.default
|
|
||||||
},
|
|
||||||
...(a
|
|
||||||
? [
|
|
||||||
{
|
|
||||||
text: a,
|
|
||||||
type: DatasetDataIndexTypeEnum.default
|
|
||||||
}
|
|
||||||
]
|
|
||||||
: [])
|
|
||||||
];
|
|
||||||
}
|
|
||||||
|
|
||||||
export const predictDataLimitLength = (mode: TrainingModeEnum, data: any[]) => {
|
export const predictDataLimitLength = (mode: TrainingModeEnum, data: any[]) => {
|
||||||
if (mode === TrainingModeEnum.qa) return data.length * 20;
|
if (mode === TrainingModeEnum.qa) return data.length * 20;
|
||||||
if (mode === TrainingModeEnum.auto) return data.length * 5;
|
if (mode === TrainingModeEnum.auto) return data.length * 5;
|
||||||
|
|||||||
2
packages/global/core/plugin/type.d.ts
vendored
@@ -41,6 +41,8 @@ export type PluginTemplateType = PluginRuntimeType & {
|
|||||||
export type PluginRuntimeType = {
|
export type PluginRuntimeType = {
|
||||||
id: string;
|
id: string;
|
||||||
teamId?: string;
|
teamId?: string;
|
||||||
|
tmbId?: string;
|
||||||
|
|
||||||
name: string;
|
name: string;
|
||||||
avatar: string;
|
avatar: string;
|
||||||
showStatus?: boolean;
|
showStatus?: boolean;
|
||||||
|
|||||||
7
packages/global/core/workflow/api.d.ts
vendored
@@ -1,7 +1,12 @@
|
|||||||
import { EmbeddingModelItemType } from '../ai/model.d';
|
import { EmbeddingModelItemType } from '../ai/model.d';
|
||||||
import { NodeInputKeyEnum } from './constants';
|
import { NodeInputKeyEnum } from './constants';
|
||||||
|
|
||||||
export type SelectedDatasetType = { datasetId: string }[];
|
export type SelectedDatasetType = {
|
||||||
|
datasetId: string;
|
||||||
|
avatar: string;
|
||||||
|
name: string;
|
||||||
|
vectorModel: EmbeddingModelItemType;
|
||||||
|
}[];
|
||||||
|
|
||||||
export type HttpBodyType<T = Record<string, any>> = {
|
export type HttpBodyType<T = Record<string, any>> = {
|
||||||
// [NodeInputKeyEnum.addInputParam]: Record<string, any>;
|
// [NodeInputKeyEnum.addInputParam]: Record<string, any>;
|
||||||
|
|||||||
@@ -20,6 +20,7 @@ export enum WorkflowIOValueTypeEnum {
|
|||||||
number = 'number',
|
number = 'number',
|
||||||
boolean = 'boolean',
|
boolean = 'boolean',
|
||||||
object = 'object',
|
object = 'object',
|
||||||
|
|
||||||
arrayString = 'arrayString',
|
arrayString = 'arrayString',
|
||||||
arrayNumber = 'arrayNumber',
|
arrayNumber = 'arrayNumber',
|
||||||
arrayBoolean = 'arrayBoolean',
|
arrayBoolean = 'arrayBoolean',
|
||||||
@@ -154,7 +155,12 @@ export enum NodeInputKeyEnum {
|
|||||||
datasetSimilarity = 'similarity',
|
datasetSimilarity = 'similarity',
|
||||||
datasetMaxTokens = 'limit',
|
datasetMaxTokens = 'limit',
|
||||||
datasetSearchMode = 'searchMode',
|
datasetSearchMode = 'searchMode',
|
||||||
|
datasetSearchEmbeddingWeight = 'embeddingWeight',
|
||||||
|
|
||||||
datasetSearchUsingReRank = 'usingReRank',
|
datasetSearchUsingReRank = 'usingReRank',
|
||||||
|
datasetSearchRerankWeight = 'rerankWeight',
|
||||||
|
datasetSearchRerankModel = 'rerankModel',
|
||||||
|
|
||||||
datasetSearchUsingExtensionQuery = 'datasetSearchUsingExtensionQuery',
|
datasetSearchUsingExtensionQuery = 'datasetSearchUsingExtensionQuery',
|
||||||
datasetSearchExtensionModel = 'datasetSearchExtensionModel',
|
datasetSearchExtensionModel = 'datasetSearchExtensionModel',
|
||||||
datasetSearchExtensionBg = 'datasetSearchExtensionBg',
|
datasetSearchExtensionBg = 'datasetSearchExtensionBg',
|
||||||
|
|||||||
@@ -133,6 +133,9 @@ export type DispatchNodeResponseType = {
|
|||||||
similarity?: number;
|
similarity?: number;
|
||||||
limit?: number;
|
limit?: number;
|
||||||
searchMode?: `${DatasetSearchModeEnum}`;
|
searchMode?: `${DatasetSearchModeEnum}`;
|
||||||
|
embeddingWeight?: number;
|
||||||
|
rerankModel?: string;
|
||||||
|
rerankWeight?: number;
|
||||||
searchUsingReRank?: boolean;
|
searchUsingReRank?: boolean;
|
||||||
queryExtensionResult?: {
|
queryExtensionResult?: {
|
||||||
model: string;
|
model: string;
|
||||||
|
|||||||
@@ -76,16 +76,9 @@ export const Input_Template_Text_Quote: FlowNodeInputItemType = {
|
|||||||
valueType: WorkflowIOValueTypeEnum.string
|
valueType: WorkflowIOValueTypeEnum.string
|
||||||
};
|
};
|
||||||
|
|
||||||
export const Input_Template_File_Link_Prompt: FlowNodeInputItemType = {
|
|
||||||
key: NodeInputKeyEnum.fileUrlList,
|
|
||||||
renderTypeList: [FlowNodeInputTypeEnum.reference, FlowNodeInputTypeEnum.input],
|
|
||||||
label: i18nT('app:file_quote_link'),
|
|
||||||
debugLabel: i18nT('app:file_quote_link'),
|
|
||||||
valueType: WorkflowIOValueTypeEnum.arrayString
|
|
||||||
};
|
|
||||||
export const Input_Template_File_Link: FlowNodeInputItemType = {
|
export const Input_Template_File_Link: FlowNodeInputItemType = {
|
||||||
key: NodeInputKeyEnum.fileUrlList,
|
key: NodeInputKeyEnum.fileUrlList,
|
||||||
renderTypeList: [FlowNodeInputTypeEnum.reference],
|
renderTypeList: [FlowNodeInputTypeEnum.reference, FlowNodeInputTypeEnum.input],
|
||||||
label: i18nT('app:workflow.user_file_input'),
|
label: i18nT('app:workflow.user_file_input'),
|
||||||
debugLabel: i18nT('app:workflow.user_file_input'),
|
debugLabel: i18nT('app:workflow.user_file_input'),
|
||||||
description: i18nT('app:workflow.user_file_input_desc'),
|
description: i18nT('app:workflow.user_file_input_desc'),
|
||||||
|
|||||||
@@ -17,7 +17,7 @@ import {
|
|||||||
Input_Template_History,
|
Input_Template_History,
|
||||||
Input_Template_System_Prompt,
|
Input_Template_System_Prompt,
|
||||||
Input_Template_UserChatInput,
|
Input_Template_UserChatInput,
|
||||||
Input_Template_File_Link_Prompt
|
Input_Template_File_Link
|
||||||
} from '../../input';
|
} from '../../input';
|
||||||
import { chatNodeSystemPromptTip, systemPromptTip } from '../../tip';
|
import { chatNodeSystemPromptTip, systemPromptTip } from '../../tip';
|
||||||
import { getHandleConfig } from '../../utils';
|
import { getHandleConfig } from '../../utils';
|
||||||
@@ -55,7 +55,7 @@ export const AiChatModule: FlowNodeTemplateType = {
|
|||||||
showStatus: true,
|
showStatus: true,
|
||||||
isTool: true,
|
isTool: true,
|
||||||
courseUrl: '/docs/guide/workbench/workflow/ai_chat/',
|
courseUrl: '/docs/guide/workbench/workflow/ai_chat/',
|
||||||
version: '490',
|
version: '4.9.0',
|
||||||
inputs: [
|
inputs: [
|
||||||
Input_Template_SettingAiModel,
|
Input_Template_SettingAiModel,
|
||||||
// --- settings modal
|
// --- settings modal
|
||||||
@@ -129,7 +129,7 @@ export const AiChatModule: FlowNodeTemplateType = {
|
|||||||
},
|
},
|
||||||
Input_Template_History,
|
Input_Template_History,
|
||||||
Input_Template_Dataset_Quote,
|
Input_Template_Dataset_Quote,
|
||||||
Input_Template_File_Link_Prompt,
|
Input_Template_File_Link,
|
||||||
{ ...Input_Template_UserChatInput, toolDescription: i18nT('workflow:user_question') }
|
{ ...Input_Template_UserChatInput, toolDescription: i18nT('workflow:user_question') }
|
||||||
],
|
],
|
||||||
outputs: [
|
outputs: [
|
||||||
|
|||||||
@@ -30,7 +30,7 @@ export const ClassifyQuestionModule: FlowNodeTemplateType = {
|
|||||||
name: i18nT('workflow:question_classification'),
|
name: i18nT('workflow:question_classification'),
|
||||||
intro: i18nT('workflow:intro_question_classification'),
|
intro: i18nT('workflow:intro_question_classification'),
|
||||||
showStatus: true,
|
showStatus: true,
|
||||||
version: '481',
|
version: '4.9.2',
|
||||||
courseUrl: '/docs/guide/workbench/workflow/question_classify/',
|
courseUrl: '/docs/guide/workbench/workflow/question_classify/',
|
||||||
inputs: [
|
inputs: [
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -27,7 +27,7 @@ export const ContextExtractModule: FlowNodeTemplateType = {
|
|||||||
showStatus: true,
|
showStatus: true,
|
||||||
isTool: true,
|
isTool: true,
|
||||||
courseUrl: '/docs/guide/workbench/workflow/content_extract/',
|
courseUrl: '/docs/guide/workbench/workflow/content_extract/',
|
||||||
version: '481',
|
version: '4.9.2',
|
||||||
inputs: [
|
inputs: [
|
||||||
{
|
{
|
||||||
...Input_Template_SelectAIModel,
|
...Input_Template_SelectAIModel,
|
||||||
|
|||||||
@@ -4,7 +4,10 @@ export type ContextExtractAgentItemType = {
|
|||||||
valueType:
|
valueType:
|
||||||
| WorkflowIOValueTypeEnum.string
|
| WorkflowIOValueTypeEnum.string
|
||||||
| WorkflowIOValueTypeEnum.number
|
| WorkflowIOValueTypeEnum.number
|
||||||
| WorkflowIOValueTypeEnum.boolean;
|
| WorkflowIOValueTypeEnum.boolean
|
||||||
|
| WorkflowIOValueTypeEnum.arrayString
|
||||||
|
| WorkflowIOValueTypeEnum.arrayNumber
|
||||||
|
| WorkflowIOValueTypeEnum.arrayBoolean;
|
||||||
desc: string;
|
desc: string;
|
||||||
key: string;
|
key: string;
|
||||||
required: boolean;
|
required: boolean;
|
||||||
|
|||||||
@@ -31,7 +31,7 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
|||||||
showStatus: true,
|
showStatus: true,
|
||||||
isTool: true,
|
isTool: true,
|
||||||
courseUrl: '/docs/guide/workbench/workflow/dataset_search/',
|
courseUrl: '/docs/guide/workbench/workflow/dataset_search/',
|
||||||
version: '481',
|
version: '4.9.2',
|
||||||
inputs: [
|
inputs: [
|
||||||
{
|
{
|
||||||
key: NodeInputKeyEnum.datasetSelectList,
|
key: NodeInputKeyEnum.datasetSelectList,
|
||||||
@@ -64,6 +64,14 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
|||||||
valueType: WorkflowIOValueTypeEnum.string,
|
valueType: WorkflowIOValueTypeEnum.string,
|
||||||
value: DatasetSearchModeEnum.embedding
|
value: DatasetSearchModeEnum.embedding
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
key: NodeInputKeyEnum.datasetSearchEmbeddingWeight,
|
||||||
|
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||||
|
label: '',
|
||||||
|
valueType: WorkflowIOValueTypeEnum.number,
|
||||||
|
value: 0.5
|
||||||
|
},
|
||||||
|
// Rerank
|
||||||
{
|
{
|
||||||
key: NodeInputKeyEnum.datasetSearchUsingReRank,
|
key: NodeInputKeyEnum.datasetSearchUsingReRank,
|
||||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||||
@@ -71,6 +79,20 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
|||||||
valueType: WorkflowIOValueTypeEnum.boolean,
|
valueType: WorkflowIOValueTypeEnum.boolean,
|
||||||
value: false
|
value: false
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
key: NodeInputKeyEnum.datasetSearchRerankModel,
|
||||||
|
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||||
|
label: '',
|
||||||
|
valueType: WorkflowIOValueTypeEnum.string
|
||||||
|
},
|
||||||
|
{
|
||||||
|
key: NodeInputKeyEnum.datasetSearchRerankWeight,
|
||||||
|
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||||
|
label: '',
|
||||||
|
valueType: WorkflowIOValueTypeEnum.number,
|
||||||
|
value: 0.5
|
||||||
|
},
|
||||||
|
// Query Extension
|
||||||
{
|
{
|
||||||
key: NodeInputKeyEnum.datasetSearchUsingExtensionQuery,
|
key: NodeInputKeyEnum.datasetSearchUsingExtensionQuery,
|
||||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||||
@@ -91,6 +113,7 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
|||||||
valueType: WorkflowIOValueTypeEnum.string,
|
valueType: WorkflowIOValueTypeEnum.string,
|
||||||
value: ''
|
value: ''
|
||||||
},
|
},
|
||||||
|
|
||||||
{
|
{
|
||||||
key: NodeInputKeyEnum.authTmbId,
|
key: NodeInputKeyEnum.authTmbId,
|
||||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||||
|
|||||||
@@ -23,7 +23,7 @@ export const ReadFilesNode: FlowNodeTemplateType = {
|
|||||||
name: i18nT('app:workflow.read_files'),
|
name: i18nT('app:workflow.read_files'),
|
||||||
intro: i18nT('app:workflow.read_files_tip'),
|
intro: i18nT('app:workflow.read_files_tip'),
|
||||||
showStatus: true,
|
showStatus: true,
|
||||||
version: '4812',
|
version: '4.9.2',
|
||||||
isTool: false,
|
isTool: false,
|
||||||
courseUrl: '/docs/guide/course/fileinput/',
|
courseUrl: '/docs/guide/course/fileinput/',
|
||||||
inputs: [
|
inputs: [
|
||||||
|
|||||||
@@ -20,7 +20,7 @@ import { chatNodeSystemPromptTip, systemPromptTip } from '../tip';
|
|||||||
import { LLMModelTypeEnum } from '../../../ai/constants';
|
import { LLMModelTypeEnum } from '../../../ai/constants';
|
||||||
import { getHandleConfig } from '../utils';
|
import { getHandleConfig } from '../utils';
|
||||||
import { i18nT } from '../../../../../web/i18n/utils';
|
import { i18nT } from '../../../../../web/i18n/utils';
|
||||||
import { Input_Template_File_Link_Prompt } from '../input';
|
import { Input_Template_File_Link } from '../input';
|
||||||
|
|
||||||
export const ToolModule: FlowNodeTemplateType = {
|
export const ToolModule: FlowNodeTemplateType = {
|
||||||
id: FlowNodeTypeEnum.tools,
|
id: FlowNodeTypeEnum.tools,
|
||||||
@@ -33,7 +33,7 @@ export const ToolModule: FlowNodeTemplateType = {
|
|||||||
intro: i18nT('workflow:template.tool_call_intro'),
|
intro: i18nT('workflow:template.tool_call_intro'),
|
||||||
showStatus: true,
|
showStatus: true,
|
||||||
courseUrl: '/docs/guide/workbench/workflow/tool/',
|
courseUrl: '/docs/guide/workbench/workflow/tool/',
|
||||||
version: '4813',
|
version: '4.9.2',
|
||||||
inputs: [
|
inputs: [
|
||||||
{
|
{
|
||||||
...Input_Template_SettingAiModel,
|
...Input_Template_SettingAiModel,
|
||||||
@@ -97,7 +97,7 @@ export const ToolModule: FlowNodeTemplateType = {
|
|||||||
placeholder: chatNodeSystemPromptTip
|
placeholder: chatNodeSystemPromptTip
|
||||||
},
|
},
|
||||||
Input_Template_History,
|
Input_Template_History,
|
||||||
Input_Template_File_Link_Prompt,
|
Input_Template_File_Link,
|
||||||
Input_Template_UserChatInput
|
Input_Template_UserChatInput
|
||||||
],
|
],
|
||||||
outputs: [
|
outputs: [
|
||||||
|
|||||||
@@ -3,14 +3,14 @@
|
|||||||
"version": "1.0.0",
|
"version": "1.0.0",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"@apidevtools/swagger-parser": "^10.1.0",
|
"@apidevtools/swagger-parser": "^10.1.0",
|
||||||
"axios": "^1.5.1",
|
"axios": "^1.8.2",
|
||||||
"cron-parser": "^4.9.0",
|
"cron-parser": "^4.9.0",
|
||||||
"dayjs": "^1.11.7",
|
"dayjs": "^1.11.7",
|
||||||
"encoding": "^0.1.13",
|
"encoding": "^0.1.13",
|
||||||
"js-yaml": "^4.1.0",
|
"js-yaml": "^4.1.0",
|
||||||
"jschardet": "3.1.1",
|
"jschardet": "3.1.1",
|
||||||
"nanoid": "^4.0.1",
|
"nanoid": "^5.1.3",
|
||||||
"next": "14.2.5",
|
"next": "14.2.25",
|
||||||
"openai": "4.61.0",
|
"openai": "4.61.0",
|
||||||
"openapi-types": "^12.1.3",
|
"openapi-types": "^12.1.3",
|
||||||
"json5": "^2.2.3",
|
"json5": "^2.2.3",
|
||||||
|
|||||||
3
packages/global/support/outLink/type.d.ts
vendored
@@ -63,6 +63,8 @@ export type OutLinkSchema<T extends OutlinkAppType = undefined> = {
|
|||||||
responseDetail: boolean;
|
responseDetail: boolean;
|
||||||
// whether to hide the node status
|
// whether to hide the node status
|
||||||
showNodeStatus?: boolean;
|
showNodeStatus?: boolean;
|
||||||
|
// wheter to show the full text reader
|
||||||
|
// showFullText?: boolean;
|
||||||
// whether to show the complete quote
|
// whether to show the complete quote
|
||||||
showRawSource?: boolean;
|
showRawSource?: boolean;
|
||||||
|
|
||||||
@@ -89,6 +91,7 @@ export type OutLinkEditType<T = undefined> = {
|
|||||||
name: string;
|
name: string;
|
||||||
responseDetail?: OutLinkSchema<T>['responseDetail'];
|
responseDetail?: OutLinkSchema<T>['responseDetail'];
|
||||||
showNodeStatus?: OutLinkSchema<T>['showNodeStatus'];
|
showNodeStatus?: OutLinkSchema<T>['showNodeStatus'];
|
||||||
|
// showFullText?: OutLinkSchema<T>['showFullText'];
|
||||||
showRawSource?: OutLinkSchema<T>['showRawSource'];
|
showRawSource?: OutLinkSchema<T>['showRawSource'];
|
||||||
// response when request
|
// response when request
|
||||||
immediateResponse?: string;
|
immediateResponse?: string;
|
||||||
|
|||||||
4
packages/global/support/permission/memberGroup/api.d.ts
vendored
Normal file
@@ -0,0 +1,4 @@
|
|||||||
|
export type GetGroupListBody = {
|
||||||
|
searchKey?: string;
|
||||||
|
withMembers?: boolean;
|
||||||
|
};
|
||||||
@@ -1,6 +1,7 @@
|
|||||||
import { TeamMemberItemType } from 'support/user/team/type';
|
import { TeamMemberItemType } from 'support/user/team/type';
|
||||||
import { TeamPermission } from '../user/controller';
|
import { TeamPermission } from '../user/controller';
|
||||||
import { GroupMemberRole } from './constant';
|
import { GroupMemberRole } from './constant';
|
||||||
|
import { Permission } from '../controller';
|
||||||
|
|
||||||
type MemberGroupSchemaType = {
|
type MemberGroupSchemaType = {
|
||||||
_id: string;
|
_id: string;
|
||||||
@@ -16,12 +17,28 @@ type GroupMemberSchemaType = {
|
|||||||
role: `${GroupMemberRole}`;
|
role: `${GroupMemberRole}`;
|
||||||
};
|
};
|
||||||
|
|
||||||
type MemberGroupType = MemberGroupSchemaType & {
|
type MemberGroupListItemType<T extends boolean | undefined> = MemberGroupSchemaType & {
|
||||||
members: {
|
members: T extends true
|
||||||
tmbId: string;
|
? {
|
||||||
role: `${GroupMemberRole}`;
|
tmbId: string;
|
||||||
}[]; // we can get tmb's info from other api. there is no need but only need to get tmb's id
|
name: string;
|
||||||
permission: TeamPermission;
|
avatar: string;
|
||||||
|
}[]
|
||||||
|
: undefined;
|
||||||
|
count: T extends true ? number : undefined;
|
||||||
|
owner?: T extends true
|
||||||
|
? {
|
||||||
|
tmbId: string;
|
||||||
|
name: string;
|
||||||
|
avatar: string;
|
||||||
|
}
|
||||||
|
: undefined;
|
||||||
|
permission: T extends true ? Permission : undefined;
|
||||||
};
|
};
|
||||||
|
|
||||||
type MemberGroupListType = MemberGroupType[];
|
type GroupMemberItemType = {
|
||||||
|
tmbId: string;
|
||||||
|
name: string;
|
||||||
|
avatar: string;
|
||||||
|
role: `${GroupMemberRole}`;
|
||||||
|
};
|
||||||
|
|||||||
7
packages/global/support/user/api.d.ts
vendored
@@ -1,4 +1,7 @@
|
|||||||
import { MemberGroupSchemaType, MemberGroupType } from 'support/permission/memberGroup/type';
|
import {
|
||||||
|
MemberGroupSchemaType,
|
||||||
|
MemberGroupListItemType
|
||||||
|
} from 'support/permission/memberGroup/type';
|
||||||
import { OAuthEnum } from './constant';
|
import { OAuthEnum } from './constant';
|
||||||
import { TrackRegisterParams } from './login/api';
|
import { TrackRegisterParams } from './login/api';
|
||||||
import { TeamMemberStatusEnum } from './team/constant';
|
import { TeamMemberStatusEnum } from './team/constant';
|
||||||
@@ -12,8 +15,8 @@ export type PostLoginProps = {
|
|||||||
|
|
||||||
export type OauthLoginProps = {
|
export type OauthLoginProps = {
|
||||||
type: `${OAuthEnum}`;
|
type: `${OAuthEnum}`;
|
||||||
code: string;
|
|
||||||
callbackUrl: string;
|
callbackUrl: string;
|
||||||
|
props: Record<string, string>;
|
||||||
} & TrackRegisterParams;
|
} & TrackRegisterParams;
|
||||||
|
|
||||||
export type WxLoginProps = {
|
export type WxLoginProps = {
|
||||||
|
|||||||
@@ -16,7 +16,5 @@ export enum OAuthEnum {
|
|||||||
google = 'google',
|
google = 'google',
|
||||||
wechat = 'wechat',
|
wechat = 'wechat',
|
||||||
microsoft = 'microsoft',
|
microsoft = 'microsoft',
|
||||||
dingtalk = 'dingtalk',
|
|
||||||
wecom = 'wecom',
|
|
||||||
sso = 'sso'
|
sso = 'sso'
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -14,29 +14,28 @@ export const TeamMemberRoleMap = {
|
|||||||
};
|
};
|
||||||
|
|
||||||
export enum TeamMemberStatusEnum {
|
export enum TeamMemberStatusEnum {
|
||||||
waiting = 'waiting',
|
|
||||||
active = 'active',
|
active = 'active',
|
||||||
reject = 'reject',
|
leave = 'leave',
|
||||||
leave = 'leave'
|
forbidden = 'forbidden'
|
||||||
}
|
}
|
||||||
|
|
||||||
export const TeamMemberStatusMap = {
|
export const TeamMemberStatusMap = {
|
||||||
[TeamMemberStatusEnum.waiting]: {
|
|
||||||
label: 'user.team.member.waiting',
|
|
||||||
color: 'orange.600'
|
|
||||||
},
|
|
||||||
[TeamMemberStatusEnum.active]: {
|
[TeamMemberStatusEnum.active]: {
|
||||||
label: 'user.team.member.active',
|
label: 'user.team.member.active',
|
||||||
color: 'green.600'
|
color: 'green.600'
|
||||||
},
|
},
|
||||||
[TeamMemberStatusEnum.reject]: {
|
|
||||||
label: 'user.team.member.reject',
|
|
||||||
color: 'red.600'
|
|
||||||
},
|
|
||||||
[TeamMemberStatusEnum.leave]: {
|
[TeamMemberStatusEnum.leave]: {
|
||||||
label: 'user.team.member.leave',
|
label: 'user.team.member.leave',
|
||||||
color: 'red.600'
|
color: 'red.600'
|
||||||
|
},
|
||||||
|
[TeamMemberStatusEnum.forbidden]: {
|
||||||
|
label: 'user.team.member.forbidden',
|
||||||
|
color: 'red.600'
|
||||||
}
|
}
|
||||||
};
|
};
|
||||||
|
|
||||||
export const notLeaveStatus = { $ne: TeamMemberStatusEnum.leave };
|
export const notLeaveStatus = {
|
||||||
|
$not: {
|
||||||
|
$in: [TeamMemberStatusEnum.leave, TeamMemberStatusEnum.forbidden]
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|||||||
@@ -10,7 +10,6 @@ export type AuthTeamRoleProps = {
|
|||||||
export type CreateTeamProps = {
|
export type CreateTeamProps = {
|
||||||
name: string;
|
name: string;
|
||||||
avatar?: string;
|
avatar?: string;
|
||||||
defaultTeam?: boolean;
|
|
||||||
memberName?: string;
|
memberName?: string;
|
||||||
memberAvatar?: string;
|
memberAvatar?: string;
|
||||||
notificationAccount?: string;
|
notificationAccount?: string;
|
||||||
@@ -41,11 +40,6 @@ export type UpdateInviteProps = {
|
|||||||
status: TeamMemberSchema['status'];
|
status: TeamMemberSchema['status'];
|
||||||
};
|
};
|
||||||
|
|
||||||
export type UpdateStatusProps = {
|
|
||||||
tmbId: string;
|
|
||||||
status: TeamMemberSchema['status'];
|
|
||||||
};
|
|
||||||
|
|
||||||
export type InviteMemberResponse = Record<
|
export type InviteMemberResponse = Record<
|
||||||
'invite' | 'inValid' | 'inTeam',
|
'invite' | 'inValid' | 'inTeam',
|
||||||
{ username: string; userId: string }[]
|
{ username: string; userId: string }[]
|
||||||
|
|||||||