Compare commits
55 Commits
v4.9.0-alp
...
v4.9.1-fix
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
2210c6809f | ||
|
|
7f13eb4642 | ||
|
|
9a1fff74fd | ||
|
|
de87639fce | ||
|
|
f9cecfd49a | ||
|
|
70563d2bcb | ||
|
|
4ca99a6361 | ||
|
|
8f70e436cf | ||
|
|
e75d81d05a | ||
|
|
56793114d8 | ||
|
|
a7b09461be | ||
|
|
cd2cb3f6ea | ||
|
|
56f77b58c9 | ||
|
|
1d697f97d7 | ||
|
|
bb30ca4859 | ||
|
|
139e934345 | ||
|
|
bf69aa6e3d | ||
|
|
3a730a23cb | ||
|
|
75cb46796a | ||
|
|
effdb5884b | ||
|
|
9523ba92f3 | ||
|
|
2f522aff90 | ||
|
|
0dccfd176d | ||
|
|
867e8acf27 | ||
|
|
36da8c862f | ||
|
|
b50cf49cc7 | ||
|
|
2270e149eb | ||
|
|
4957bdcba1 | ||
|
|
bca5cf738a | ||
|
|
c35bb5841c | ||
|
|
6e045093b1 | ||
|
|
a1b114e426 | ||
|
|
54fde7630c | ||
|
|
467c408ad7 | ||
|
|
c005a94454 | ||
|
|
c8a35822d6 | ||
|
|
d05259dedd | ||
|
|
8980664b8a | ||
|
|
43f30b3790 | ||
|
|
3ddbb37612 | ||
|
|
7c419a26b3 | ||
|
|
e131465d25 | ||
|
|
a345e56508 | ||
|
|
32ce032995 | ||
|
|
0bc075aa4e | ||
|
|
3e3f2165db | ||
|
|
e1aa068858 | ||
|
|
e98d6f1d30 | ||
|
|
54eb5c0547 | ||
|
|
adf5377ebe | ||
|
|
08b6f594df | ||
|
|
90d13ee3df | ||
|
|
5c718abd50 | ||
|
|
2d351c3654 | ||
|
|
662a4a4671 |
2
.github/workflows/docs-deploy-kubeconfig.yml
vendored
2
.github/workflows/docs-deploy-kubeconfig.yml
vendored
@@ -6,8 +6,6 @@ on:
|
||||
- 'docSite/**'
|
||||
branches:
|
||||
- 'main'
|
||||
tags:
|
||||
- 'v*.*.*'
|
||||
|
||||
jobs:
|
||||
build-fastgpt-docs-images:
|
||||
|
||||
2
.github/workflows/docs-deploy-vercel.yml
vendored
2
.github/workflows/docs-deploy-vercel.yml
vendored
@@ -7,8 +7,6 @@ on:
|
||||
- 'docSite/**'
|
||||
branches:
|
||||
- 'main'
|
||||
tags:
|
||||
- 'v*.*.*'
|
||||
|
||||
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
|
||||
jobs:
|
||||
|
||||
2
.github/workflows/docs-preview.yml
vendored
2
.github/workflows/docs-preview.yml
vendored
@@ -4,8 +4,6 @@ on:
|
||||
pull_request_target:
|
||||
paths:
|
||||
- 'docSite/**'
|
||||
branches:
|
||||
- 'main'
|
||||
workflow_dispatch:
|
||||
|
||||
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
|
||||
|
||||
3
.github/workflows/fastgpt-preview-image.yml
vendored
3
.github/workflows/fastgpt-preview-image.yml
vendored
@@ -1,9 +1,6 @@
|
||||
name: Preview FastGPT images
|
||||
on:
|
||||
pull_request_target:
|
||||
paths:
|
||||
- 'projects/app/**'
|
||||
- 'packages/**'
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
|
||||
29
.github/workflows/fastgpt-test.yaml
vendored
Normal file
29
.github/workflows/fastgpt-test.yaml
vendored
Normal file
@@ -0,0 +1,29 @@
|
||||
name: 'FastGPT-Test'
|
||||
on:
|
||||
pull_request:
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
test:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
permissions:
|
||||
# Required to checkout the code
|
||||
contents: read
|
||||
# Required to put a comment into the pull-request
|
||||
pull-requests: write
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- uses: pnpm/action-setup@v4
|
||||
with:
|
||||
version: 10
|
||||
- name: 'Install Deps'
|
||||
run: pnpm install
|
||||
- name: 'Test'
|
||||
run: pnpm run test
|
||||
- name: 'Report Coverage'
|
||||
# Set if: always() to also generate the report if tests are failing
|
||||
# Only works if you set `reportOnFailure: true` in your vite config as specified above
|
||||
if: always()
|
||||
uses: davelosert/vitest-coverage-report-action@v2
|
||||
1
.gitignore
vendored
1
.gitignore
vendored
@@ -44,3 +44,4 @@ files/helm/fastgpt/fastgpt-0.1.0.tgz
|
||||
files/helm/fastgpt/charts/*.tgz
|
||||
|
||||
tmp/
|
||||
coverage
|
||||
|
||||
@@ -5,4 +5,6 @@ node_modules
|
||||
docSite/
|
||||
*.md
|
||||
|
||||
cl100l_base.ts
|
||||
pnpm-lock.yaml
|
||||
cl100l_base.ts
|
||||
dict.json
|
||||
7
.vscode/i18n-ally-custom-framework.yml
vendored
7
.vscode/i18n-ally-custom-framework.yml
vendored
@@ -17,15 +17,8 @@ usageMatchRegex:
|
||||
# you can ignore it and use your own matching rules as well
|
||||
- "[^\\w\\d]t\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]commonT\\(['\"`]({key})['\"`]"
|
||||
# 支持 appT("your.i18n.keys")
|
||||
- "[^\\w\\d]appT\\(['\"`]({key})['\"`]"
|
||||
# 支持 datasetT("your.i18n.keys")
|
||||
- "[^\\w\\d]datasetT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]fileT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]publishT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]workflowT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]userT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]chatT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]i18nT\\(['\"`]({key})['\"`]"
|
||||
|
||||
# A RegEx to set a custom scope range. This scope will be used as a prefix when detecting keys
|
||||
|
||||
@@ -129,7 +129,8 @@ https://github.com/labring/FastGPT/assets/15308462/7d3a38df-eb0e-4388-9250-2409b
|
||||
</a>
|
||||
|
||||
## 🌿 第三方生态
|
||||
|
||||
- [PPIO 派欧云:一键调用高性价比的开源模型 API 和 GPU 容器](https://ppinfra.com/user/register?invited_by=VITYVU&utm_source=github_fastgpt)
|
||||
- [AI Proxy:国内模型聚合服务](https://sealos.run/aiproxy/?k=fastgpt-github/)
|
||||
- [SiliconCloud (硅基流动) —— 开源模型在线体验平台](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
||||
- [COW 个人微信/企微机器人](https://doc.tryfastgpt.ai/docs/use-cases/external-integration/onwechat/)
|
||||
|
||||
|
||||
@@ -69,7 +69,7 @@ Project tech stack: NextJs + TS + ChakraUI + MongoDB + PostgreSQL (PG Vector plu
|
||||
|
||||
> When using [Sealos](https://sealos.io) services, there is no need to purchase servers or domain names. It supports high concurrency and dynamic scaling, and the database application uses the kubeblocks database, which far exceeds the simple Docker container deployment in terms of IO performance.
|
||||
<div align="center">
|
||||
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt)
|
||||
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt&uid=fnWRt09fZP)
|
||||
</div>
|
||||
|
||||
Give it a 2-4 minute wait after deployment as it sets up the database. Initially, it might be a too slow since we're using the basic settings.
|
||||
|
||||
@@ -94,7 +94,7 @@ https://github.com/labring/FastGPT/assets/15308462/7d3a38df-eb0e-4388-9250-2409b
|
||||
|
||||
- **⚡ デプロイ**
|
||||
|
||||
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt)
|
||||
[](https://cloud.sealos.io/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt&uid=fnWRt09fZP)
|
||||
|
||||
デプロイ 後、データベースをセットアップするので、2~4分待 ってください。基本設定 を 使 っているので、最初 は 少 し 遅 いかもしれません。
|
||||
|
||||
|
||||
@@ -100,7 +100,7 @@ services:
|
||||
exec docker-entrypoint.sh "$$@" &
|
||||
|
||||
# 等待MongoDB服务启动
|
||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
|
||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
|
||||
echo "Waiting for MongoDB to start..."
|
||||
sleep 2
|
||||
done
|
||||
@@ -114,15 +114,15 @@ services:
|
||||
# fastgpt
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.8.23-fix # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.23-fix # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.8.23-fix # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.23-fix # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -175,14 +175,13 @@ services:
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: 'ghcr.io/labring/sealos-aiproxy-service:latest'
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
aiproxy_pg:
|
||||
condition: service_healthy
|
||||
ports:
|
||||
- '3002:3000'
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
@@ -193,7 +192,7 @@ services:
|
||||
# 数据库连接地址
|
||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||
# 最大重试次数
|
||||
- RetryTimes=3
|
||||
- RETRY_TIMES=3
|
||||
# 不需要计费
|
||||
- BILLING_ENABLED=false
|
||||
# 不需要严格检测模型
|
||||
@@ -204,8 +203,8 @@ services:
|
||||
timeout: 5s
|
||||
retries: 10
|
||||
aiproxy_pg:
|
||||
# image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
restart: unless-stopped
|
||||
container_name: aiproxy_pg
|
||||
volumes:
|
||||
|
||||
@@ -28,8 +28,8 @@ services:
|
||||
# image: mongo:4.4.29 # cpu不支持AVX时候使用
|
||||
container_name: mongo
|
||||
restart: always
|
||||
ports:
|
||||
- 27017:27017
|
||||
# ports:
|
||||
# - 27017:27017
|
||||
networks:
|
||||
- fastgpt
|
||||
command: mongod --keyFile /data/mongodb.key --replSet rs0
|
||||
@@ -58,7 +58,7 @@ services:
|
||||
exec docker-entrypoint.sh "$$@" &
|
||||
|
||||
# 等待MongoDB服务启动
|
||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
|
||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
|
||||
echo "Waiting for MongoDB to start..."
|
||||
sleep 2
|
||||
done
|
||||
@@ -72,15 +72,15 @@ services:
|
||||
# fastgpt
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.8.23-fix # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.23-fix # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.8.23-fix # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.23-fix # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -132,14 +132,13 @@ services:
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: 'ghcr.io/labring/sealos-aiproxy-service:latest'
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
aiproxy_pg:
|
||||
condition: service_healthy
|
||||
ports:
|
||||
- '3002:3000'
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
@@ -150,7 +149,7 @@ services:
|
||||
# 数据库连接地址
|
||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||
# 最大重试次数
|
||||
- RetryTimes=3
|
||||
- RETRY_TIMES=3
|
||||
# 不需要计费
|
||||
- BILLING_ENABLED=false
|
||||
# 不需要严格检测模型
|
||||
@@ -161,8 +160,8 @@ services:
|
||||
timeout: 5s
|
||||
retries: 10
|
||||
aiproxy_pg:
|
||||
# image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
restart: unless-stopped
|
||||
container_name: aiproxy_pg
|
||||
volumes:
|
||||
|
||||
@@ -41,7 +41,7 @@ services:
|
||||
exec docker-entrypoint.sh "$$@" &
|
||||
|
||||
# 等待MongoDB服务启动
|
||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
|
||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
|
||||
echo "Waiting for MongoDB to start..."
|
||||
sleep 2
|
||||
done
|
||||
@@ -53,15 +53,15 @@ services:
|
||||
wait $$!
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.8.23-fix # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.23-fix # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.8.23-fix # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.23-fix # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -113,14 +113,13 @@ services:
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: 'ghcr.io/labring/sealos-aiproxy-service:latest'
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
aiproxy_pg:
|
||||
condition: service_healthy
|
||||
ports:
|
||||
- '3002:3000'
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
@@ -131,7 +130,7 @@ services:
|
||||
# 数据库连接地址
|
||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||
# 最大重试次数
|
||||
- RetryTimes=3
|
||||
- RETRY_TIMES=3
|
||||
# 不需要计费
|
||||
- BILLING_ENABLED=false
|
||||
# 不需要严格检测模型
|
||||
@@ -142,8 +141,8 @@ services:
|
||||
timeout: 5s
|
||||
retries: 10
|
||||
aiproxy_pg:
|
||||
# image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
restart: unless-stopped
|
||||
container_name: aiproxy_pg
|
||||
volumes:
|
||||
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 170 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 102 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 70 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 89 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 87 KiB |
@@ -44,7 +44,7 @@ weight: 707
|
||||
|
||||
#### 1. 申请 Sealos AI proxy API Key
|
||||
|
||||
[点击打开 Sealos Pdf parser 官网](https://cloud.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy),并进行对应 API Key 的申请。
|
||||
[点击打开 Sealos Pdf parser 官网](https://hzh.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy),并进行对应 API Key 的申请。
|
||||
|
||||
#### 2. 修改 FastGPT 配置文件
|
||||
|
||||
|
||||
@@ -24,10 +24,9 @@ PDF 是一个相对复杂的文件格式,在 FastGPT 内置的 pdf 解析器
|
||||
这里介绍快速 Docker 安装的方法:
|
||||
|
||||
```dockerfile
|
||||
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:latest
|
||||
docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:latest
|
||||
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
|
||||
docker run --gpus all -itd -p 7231:7232 --name model_pdf_v2 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
|
||||
```
|
||||
|
||||
### 2. 添加 FastGPT 文件配置
|
||||
|
||||
```json
|
||||
@@ -36,7 +35,7 @@ docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 crpi-h3snc261q1dosro
|
||||
"systemEnv": {
|
||||
xxx
|
||||
"customPdfParse": {
|
||||
"url": "http://xxxx.com/v1/parse/file", // 自定义 PDF 解析服务地址
|
||||
"url": "http://xxxx.com/v2/parse/file", // 自定义 PDF 解析服务地址 marker v0.2
|
||||
"key": "", // 自定义 PDF 解析服务密钥
|
||||
"doc2xKey": "", // doc2x 服务密钥
|
||||
"price": 0 // PDF 解析服务价格
|
||||
@@ -80,4 +79,25 @@ docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 crpi-h3snc261q1dosro
|
||||
|
||||
上图是分块后的结果,下图是 pdf 原文。整体图片、公式、表格都可以提取出来,效果还是杠杠的。
|
||||
|
||||
不过要注意的是,[Marker](https://github.com/VikParuchuri/marker) 的协议是`GPL-3.0 license`,请在遵守协议的前提下使用。
|
||||
不过要注意的是,[Marker](https://github.com/VikParuchuri/marker) 的协议是`GPL-3.0 license`,请在遵守协议的前提下使用。
|
||||
|
||||
## 旧版 Marker 使用方法
|
||||
|
||||
FastGPT V4.9.0 版本之前,可以用以下方式,试用 Marker 解析服务。
|
||||
|
||||
安装和运行 Marker 服务:
|
||||
|
||||
```dockerfile
|
||||
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
|
||||
docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
|
||||
```
|
||||
|
||||
并修改 FastGPT 环境变量:
|
||||
|
||||
```
|
||||
CUSTOM_READ_FILE_URL=http://xxxx.com/v1/parse/file
|
||||
CUSTOM_READ_FILE_EXTENSION=pdf
|
||||
```
|
||||
|
||||
* CUSTOM_READ_FILE_URL - 自定义解析服务的地址, host改成解析服务的访问地址,path 不能变动。
|
||||
* CUSTOM_READ_FILE_EXTENSION - 支持的文件后缀,多个文件类型,可用逗号隔开。
|
||||
@@ -56,7 +56,7 @@ weight: 707
|
||||
|
||||
### zilliz cloud版本
|
||||
|
||||
Milvus 的全托管服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||||
Zilliz Cloud 由 Milvus 原厂打造,是全托管的 SaaS 向量数据库服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||||
|
||||
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
|
||||
|
||||
|
||||
@@ -29,7 +29,7 @@ weight: 744
|
||||
|
||||
{{% alert icon=" " context="info" %}}
|
||||
- [SiliconCloud(硅基流动)](https://cloud.siliconflow.cn/i/TR9Ym0c4): 提供开源模型调用的平台。
|
||||
- [Sealos AIProxy](https://cloud.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy): 提供国内各家模型代理,无需逐一申请 api。
|
||||
- [Sealos AIProxy](https://hzh.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy): 提供国内各家模型代理,无需逐一申请 api。
|
||||
{{% /alert %}}
|
||||
|
||||
在 OneAPI 配置好模型后,你就可以打开 FastGPT 页面,启用对应模型了。
|
||||
|
||||
@@ -23,7 +23,7 @@ FastGPT 目前采用模型分离的部署方案,FastGPT 中只兼容 OpenAI
|
||||
### Sealos 版本
|
||||
|
||||
* 北京区: [点击部署 OneAPI](https://hzh.sealos.run/?openapp=system-template%3FtemplateName%3Done-api)
|
||||
* 新加坡区(可用 GPT) [点击部署 OneAPI](https://cloud.sealos.io/?openapp=system-template%3FtemplateName%3Done-api)
|
||||
* 新加坡区(可用 GPT) [点击部署 OneAPI](https://cloud.sealos.io/?openapp=system-template%3FtemplateName%3Done-api&uid=fnWRt09fZP)
|
||||
|
||||

|
||||
|
||||
|
||||
100
docSite/content/zh-cn/docs/development/modelConfig/ppio.md
Normal file
100
docSite/content/zh-cn/docs/development/modelConfig/ppio.md
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
title: '通过 PPIO LLM API 接入模型'
|
||||
description: '通过 PPIO LLM API 接入模型'
|
||||
icon: 'api'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 747
|
||||
---
|
||||
|
||||
FastGPT 还可以通过 PPIO LLM API 接入模型。
|
||||
{{% alert context="warning" %}}
|
||||
以下内容搬运自 [FastGPT 接入 PPIO LLM API](https://ppinfra.com/docs/third-party/fastgpt-use),可能会有更新不及时的情况。
|
||||
{{% /alert %}}
|
||||
|
||||
FastGPT 是一个将 AI 开发、部署和使用全流程简化为可视化操作的平台。它使开发者不需要深入研究算法,
|
||||
用户也不需要掌握复杂技术,通过一站式服务将人工智能技术变成易于使用的工具。
|
||||
|
||||
PPIO 派欧云提供简单易用的 API 接口,让开发者能够轻松调用 DeepSeek 等模型。
|
||||
|
||||
- 对开发者:无需重构架构,3 个接口完成从文本生成到决策推理的全场景接入,像搭积木一样设计 AI 工作流;
|
||||
- 对生态:自动适配从中小应用到企业级系统的资源需求,让智能随业务自然生长。
|
||||
|
||||
下方教程提供完整接入方案(含密钥配置),帮助您快速将 FastGPT 与 PPIO API 连接起来。
|
||||
|
||||
## 1. 配置前置条件
|
||||
|
||||
(1) 获取 API 接口地址
|
||||
|
||||
固定为: `https://api.ppinfra.com/v3/openai/chat/completions`。
|
||||
|
||||
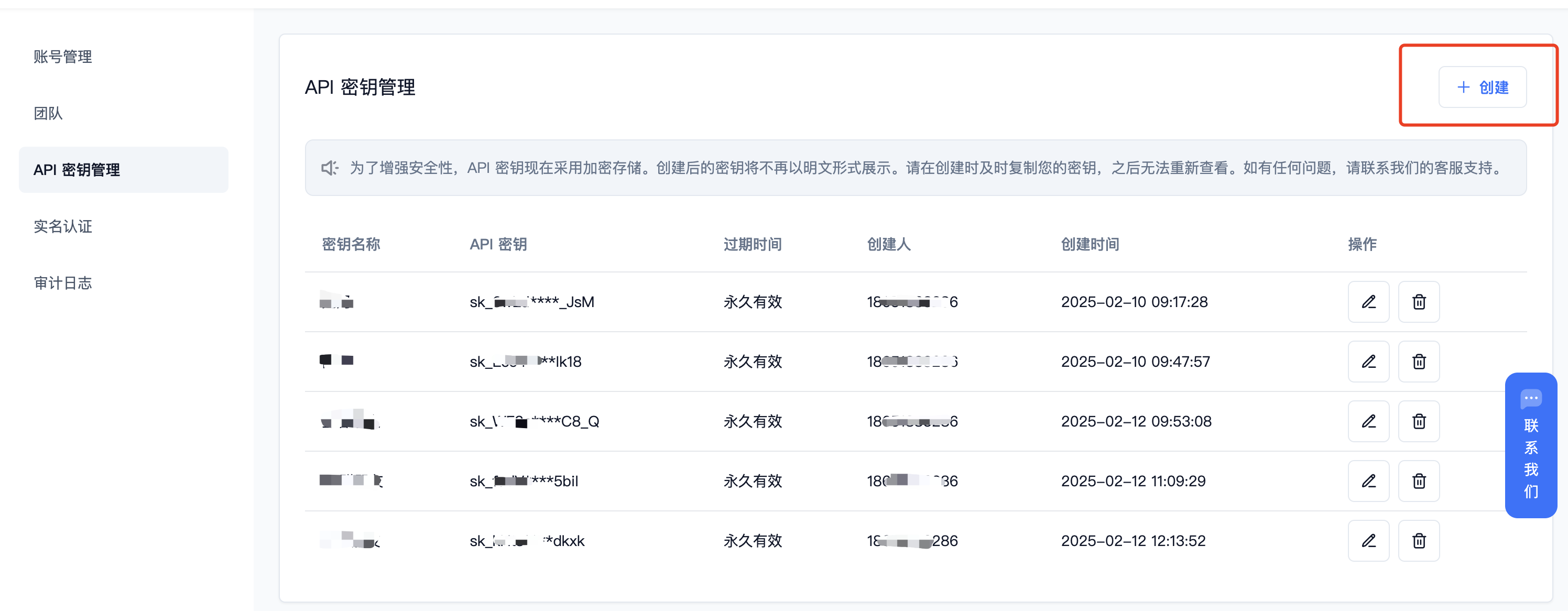
(2) 获取 【API 密钥】
|
||||
|
||||
登录派欧云控制台 [API 秘钥管理](https://www.ppinfra.com/settings/key-management) 页面,点击创建按钮。
|
||||
注册账号填写邀请码【VOJL20】得 50 代金券
|
||||
|
||||
|
||||
|
||||
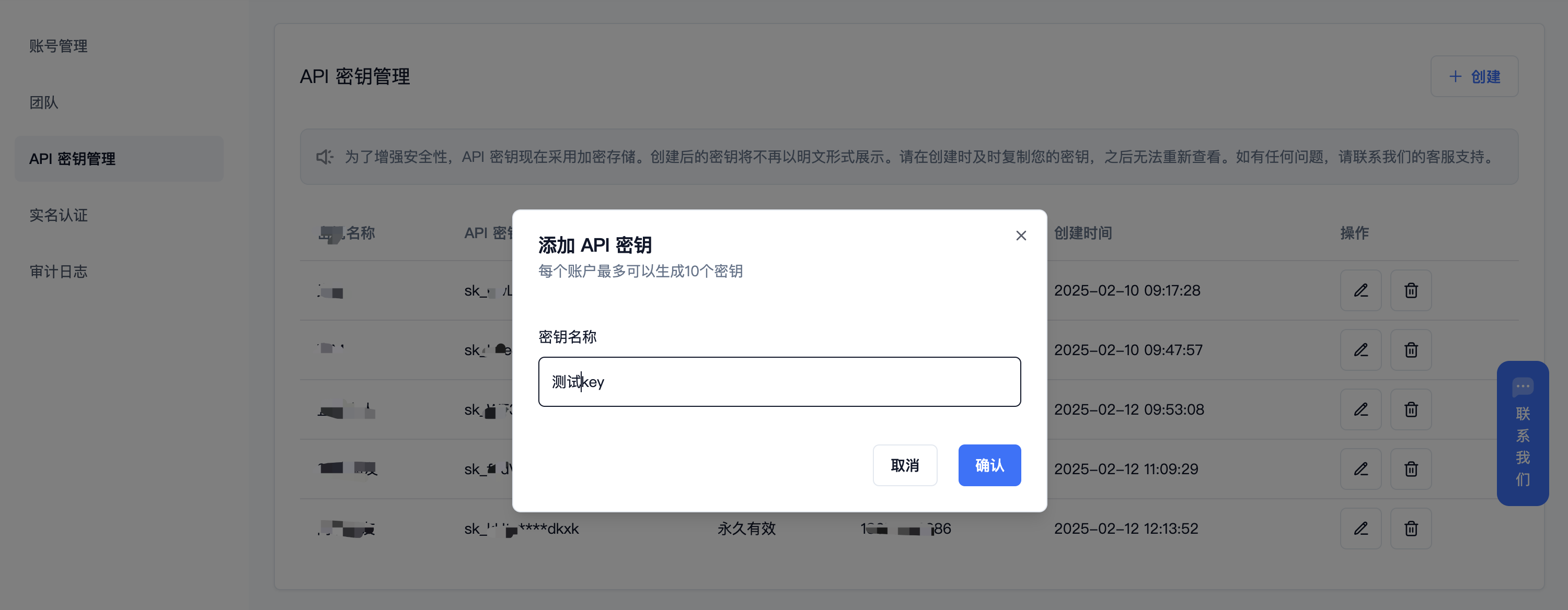
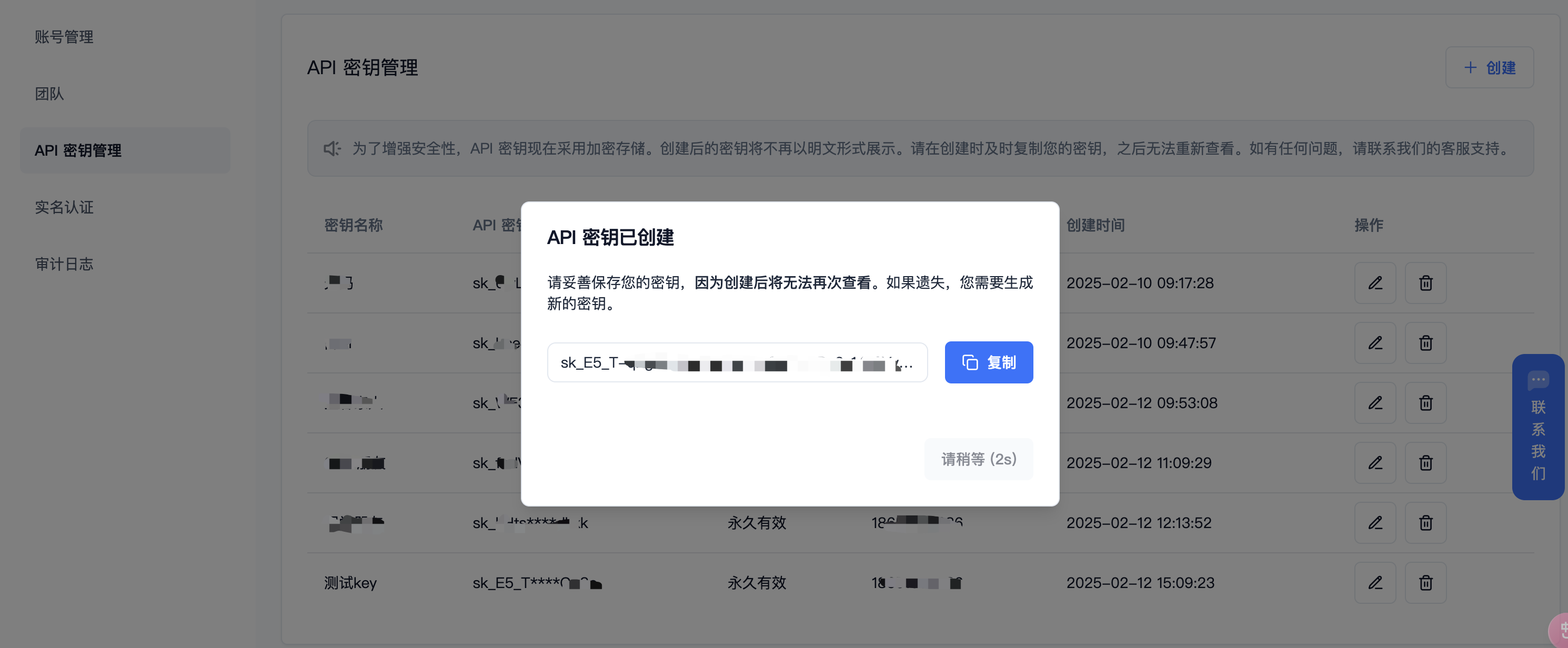
(3) 生成并保存 【API 密钥】
|
||||
{{% alert context="warning" %}}
|
||||
秘钥在服务端是加密存储,请在生成时保存好秘钥;若遗失可以在控制台上删除并创建一个新的秘钥。
|
||||
{{% /alert %}}
|
||||
|
||||
|
||||
|
||||
|
||||
(4) 获取需要使用的模型 ID
|
||||
|
||||
deepseek 系列:
|
||||
|
||||
- DeepSeek R1:deepseek/deepseek-r1/community
|
||||
|
||||
- DeepSeek V3:deepseek/deepseek-v3/community
|
||||
|
||||
其他模型 ID、最大上下文及价格可参考:[模型列表](https://ppinfra.com/model-api/pricing)
|
||||
|
||||
## 2. 部署最新版 FastGPT 到本地环境
|
||||
{{% alert context="warning" %}}
|
||||
请使用 v4.8.22 以上版本,部署参考: https://doc.tryfastgpt.ai/docs/development/intro/
|
||||
{{% /alert %}}
|
||||
|
||||
## 3. 模型配置(下面两种方式二选其一)
|
||||
|
||||
(1)通过 OneAPI 接入模型 PPIO 模型: 参考 OneAPI 使用文档,修改 FastGPT 的环境变量 在 One API 生成令牌后,FastGPT 可以通过修改 baseurl 和 key 去请求到 One API,再由 One API 去请求不同的模型。修改下面两个环境变量: 务必写上 v1。如果在同一个网络内,可改成内网地址。
|
||||
|
||||
OPENAI_BASE_URL= http://OneAPI-IP:OneAPI-PORT/v1
|
||||
|
||||
下面的 key 是由 One API 提供的令牌 CHAT_API_KEY=sk-UyVQcpQWMU7ChTVl74B562C28e3c46Fe8f16E6D8AeF8736e
|
||||
|
||||
- 修改后重启 FastGPT,按下图在模型提供商中选择派欧云
|
||||
|
||||
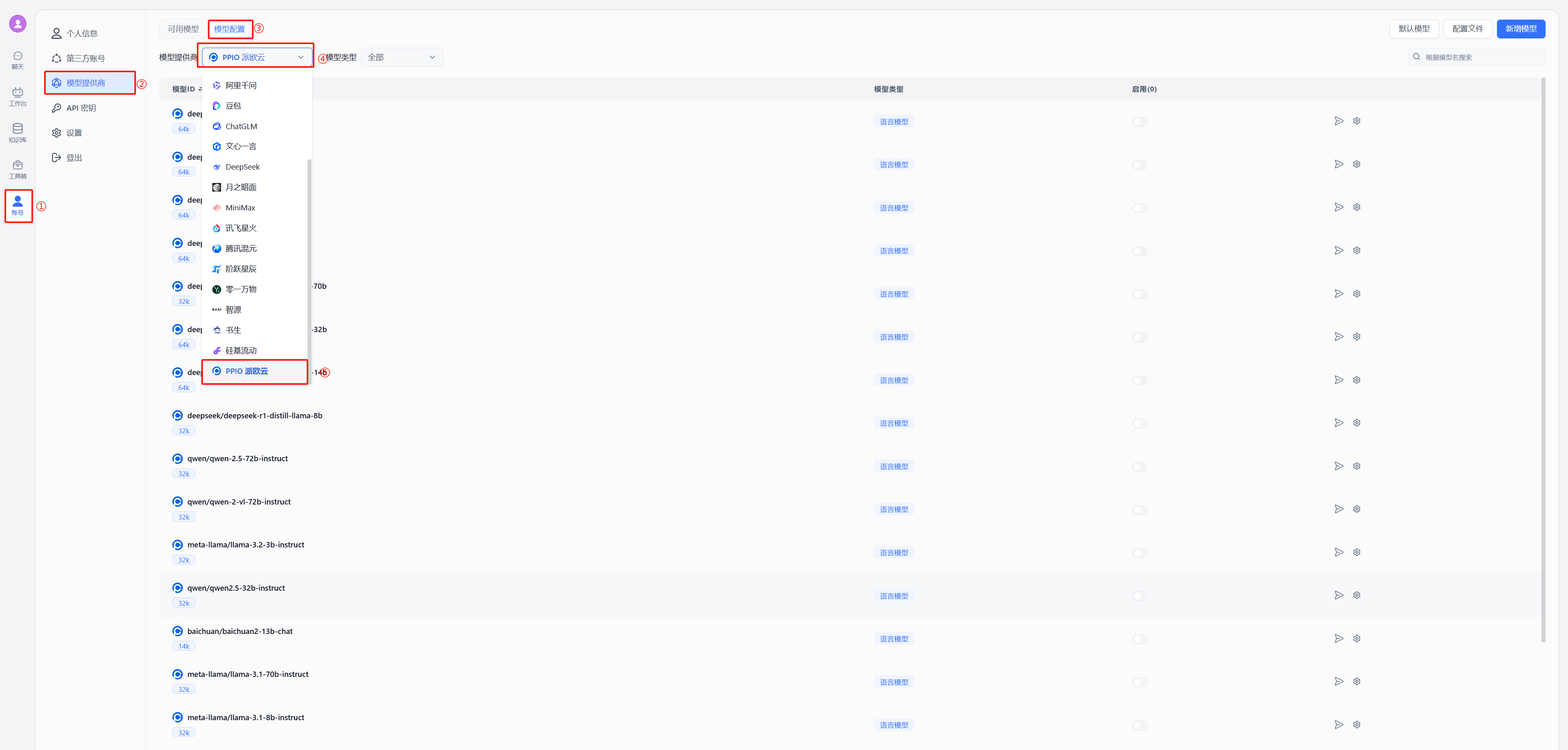
|
||||
|
||||
- 测试连通性
|
||||
以 deepseek 为例,在模型中选择使用 deepseek/deepseek-r1/community,点击图中②的位置进行连通性测试,出现图中绿色的的成功显示证明连通成功,可以进行后续的配置对话了
|
||||
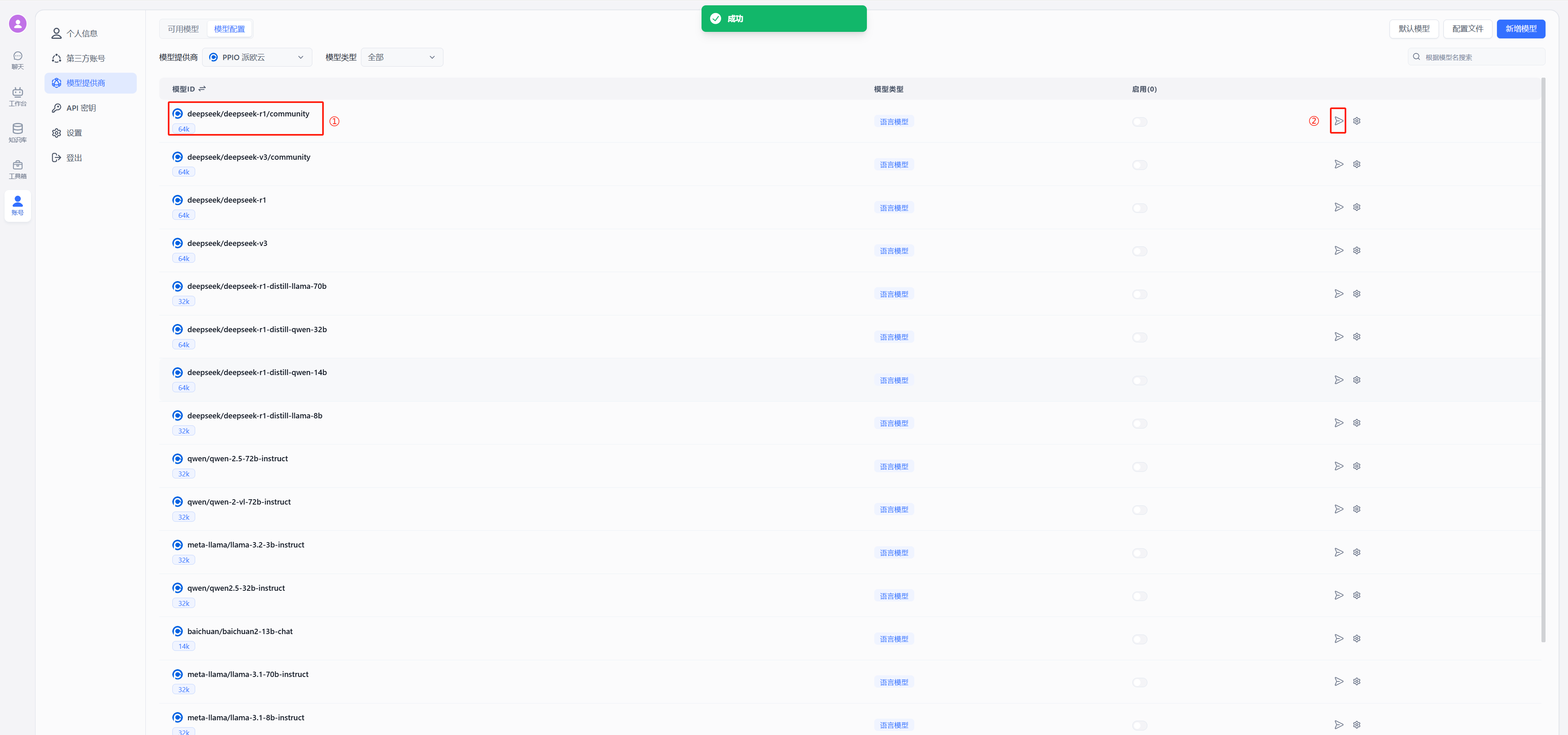
|
||||
|
||||
(2)不使用 OneAPI 接入 PPIO 模型
|
||||
|
||||
按照下图在模型提供商中选择派欧云
|
||||
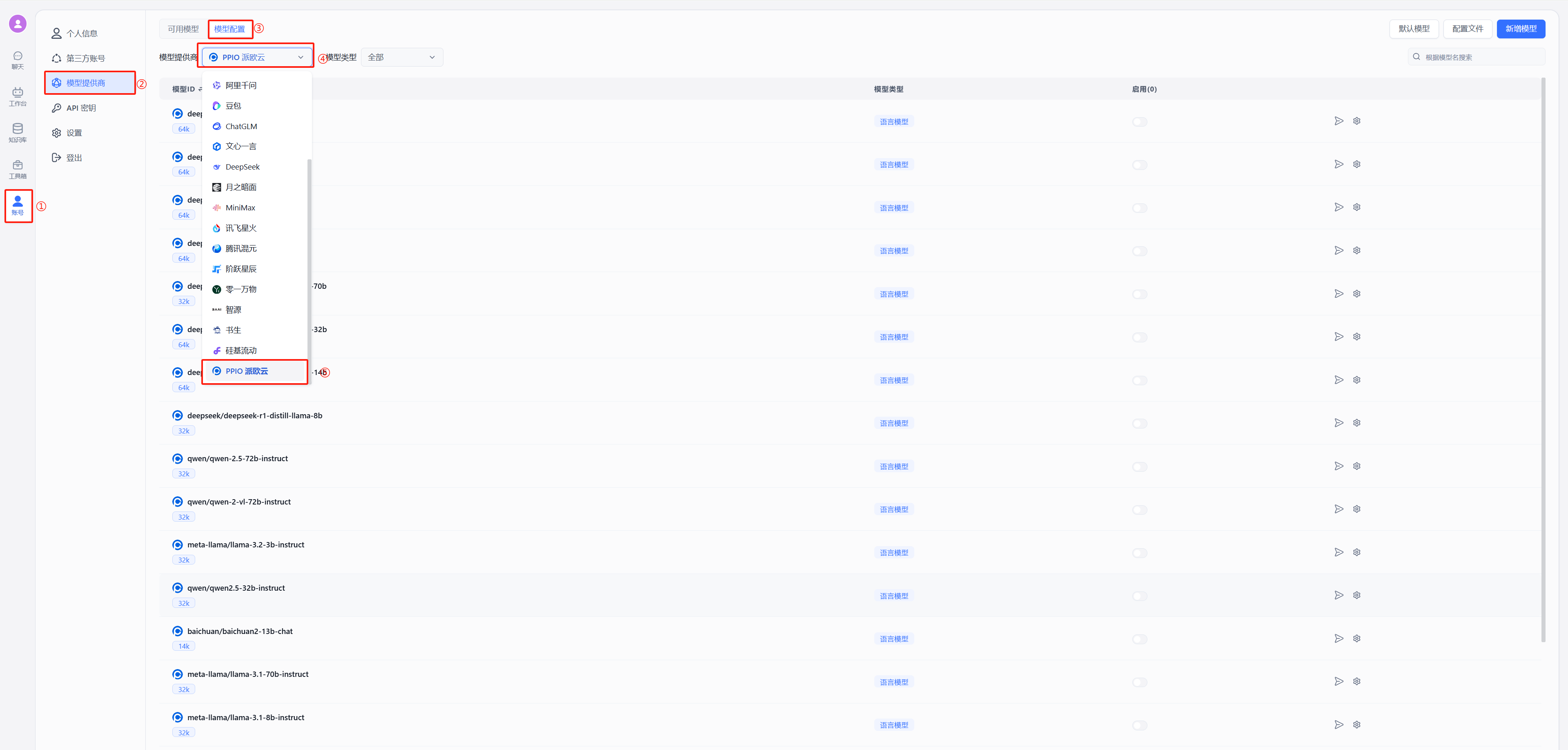
|
||||
|
||||
- 配置模型 自定义请求地址中输入:`https://api.ppinfra.com/v3/openai/chat/completions`
|
||||
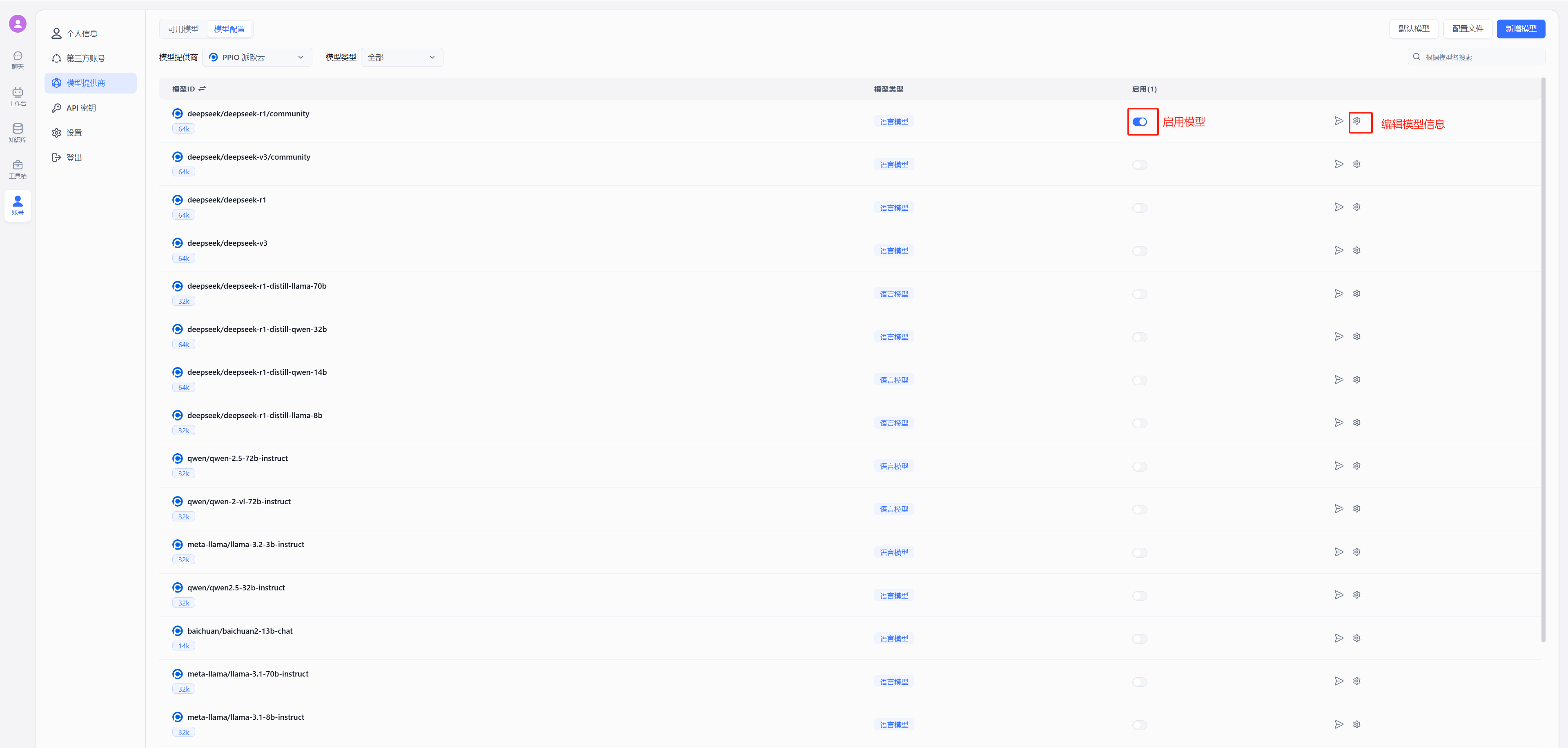
|
||||
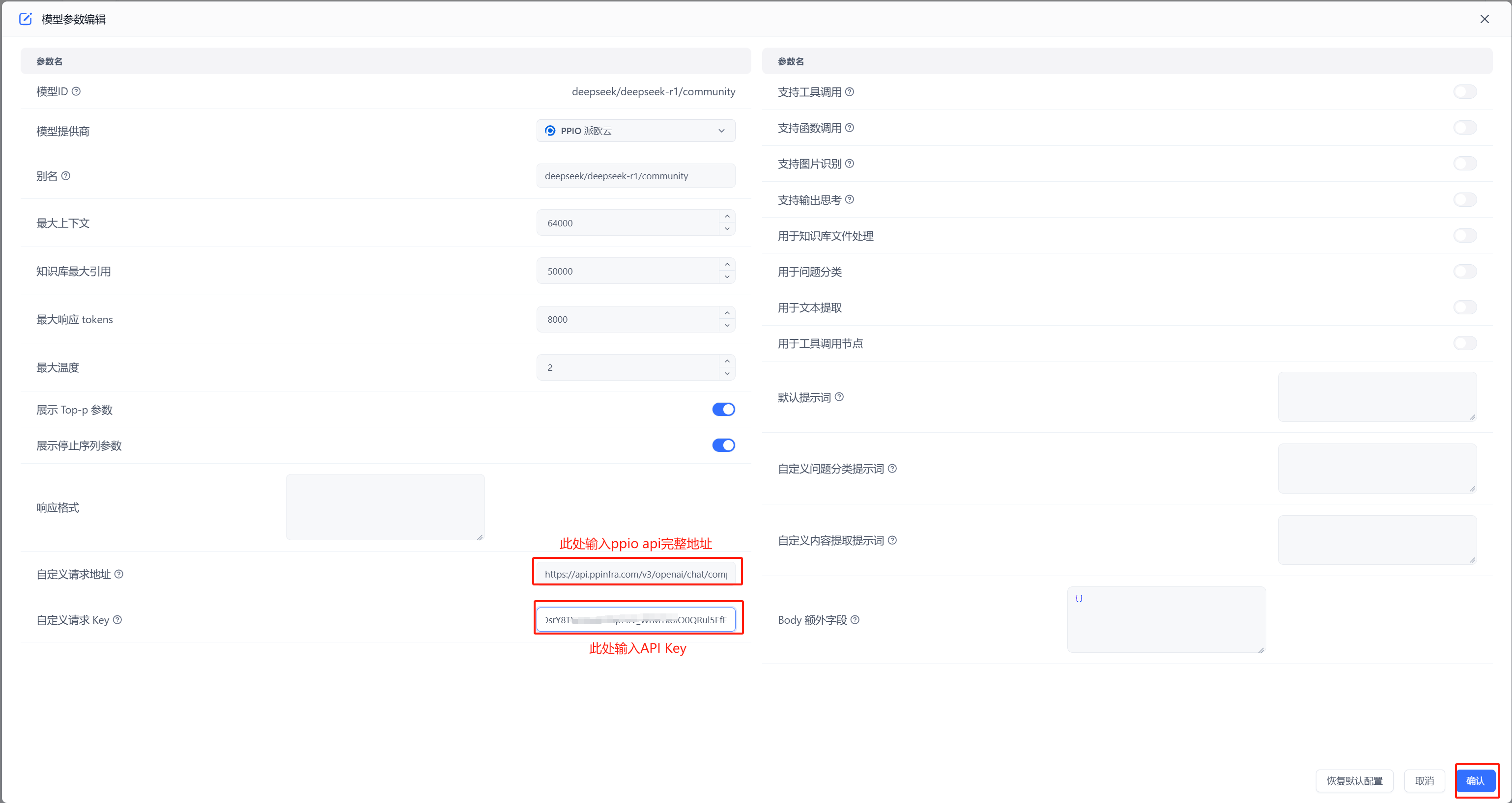
|
||||
|
||||
- 测试连通性
|
||||
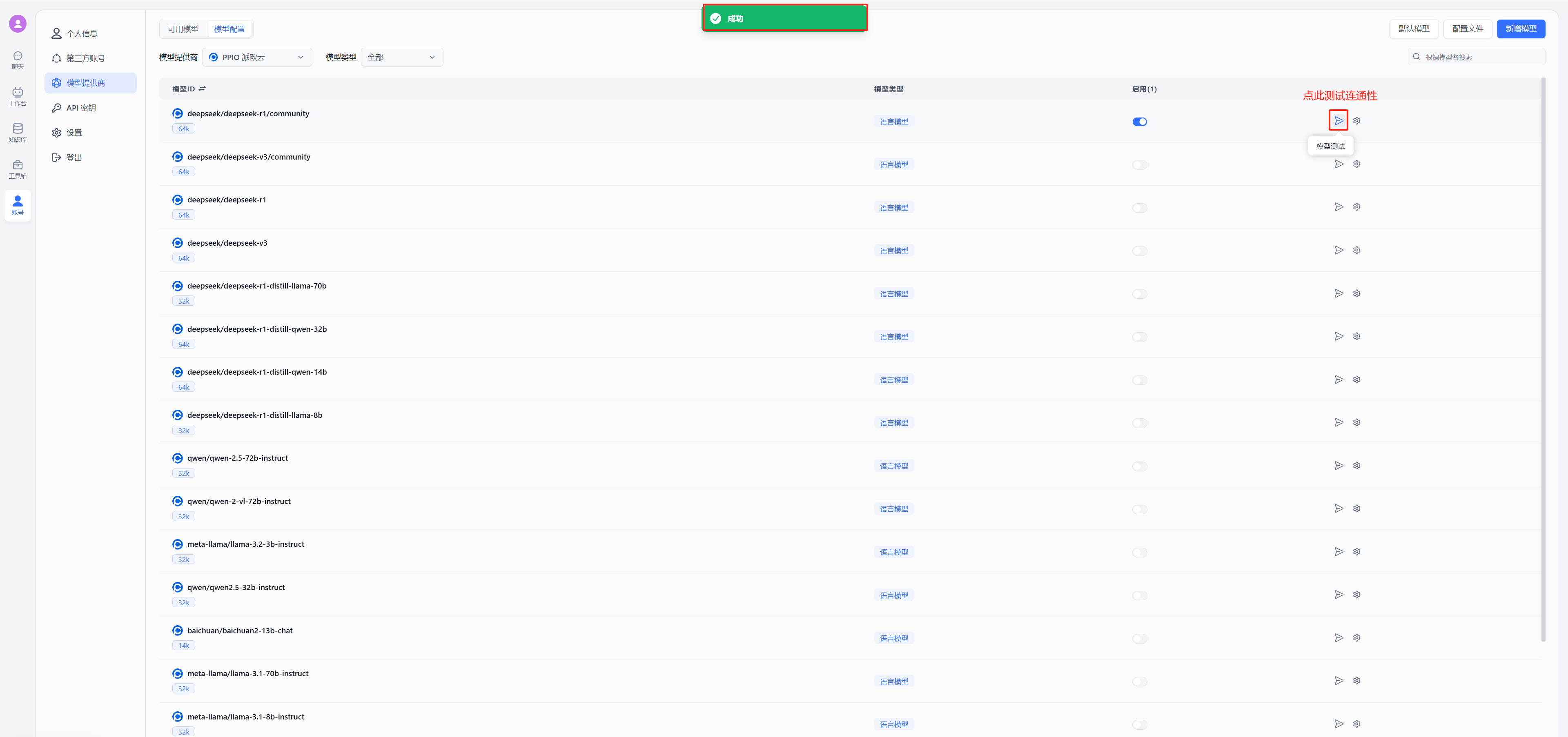
|
||||
|
||||
出现图中绿色的的成功显示证明连通成功,可以进行对话配置
|
||||
|
||||
## 4. 配置对话
|
||||
(1)新建工作台
|
||||
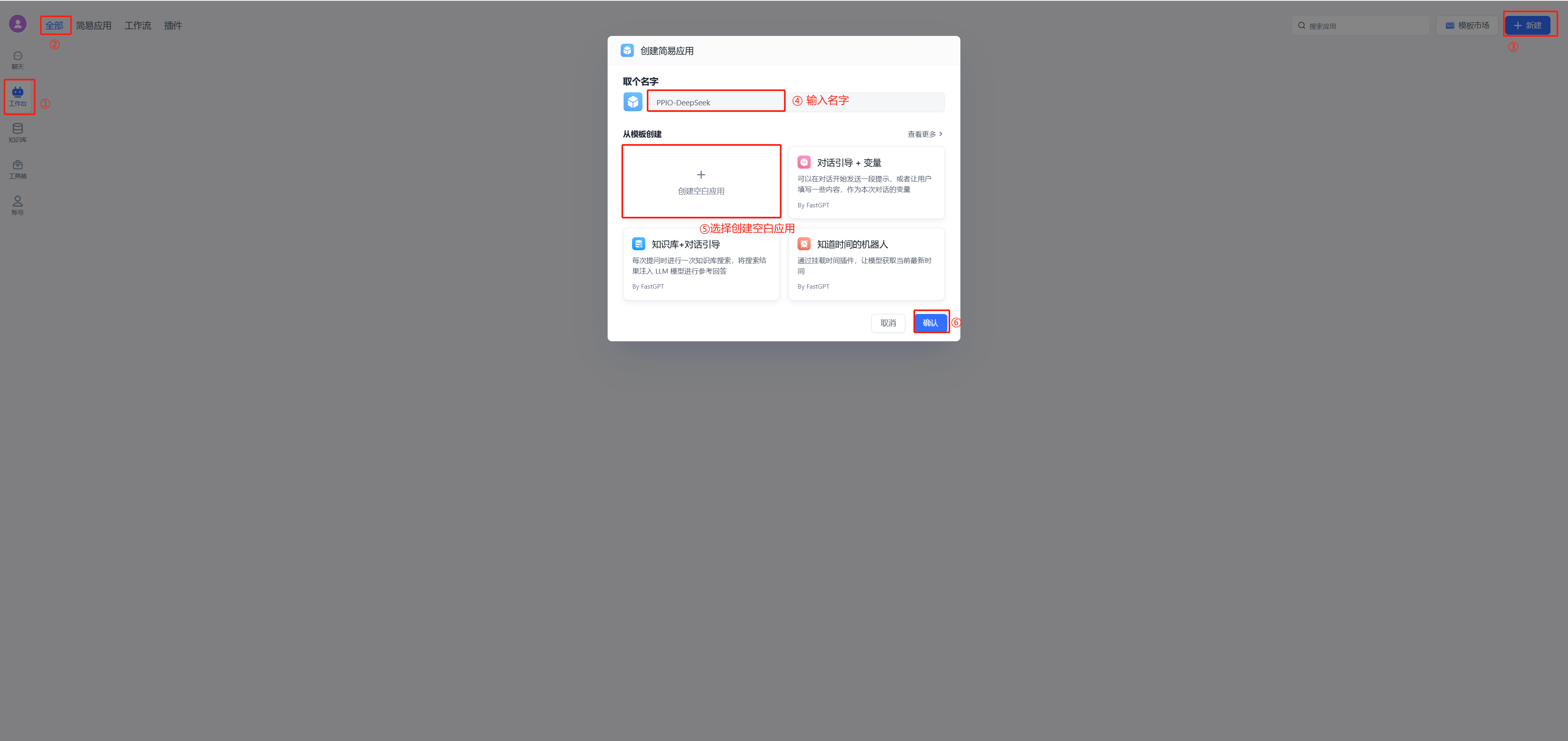
|
||||
(2)开始聊天
|
||||
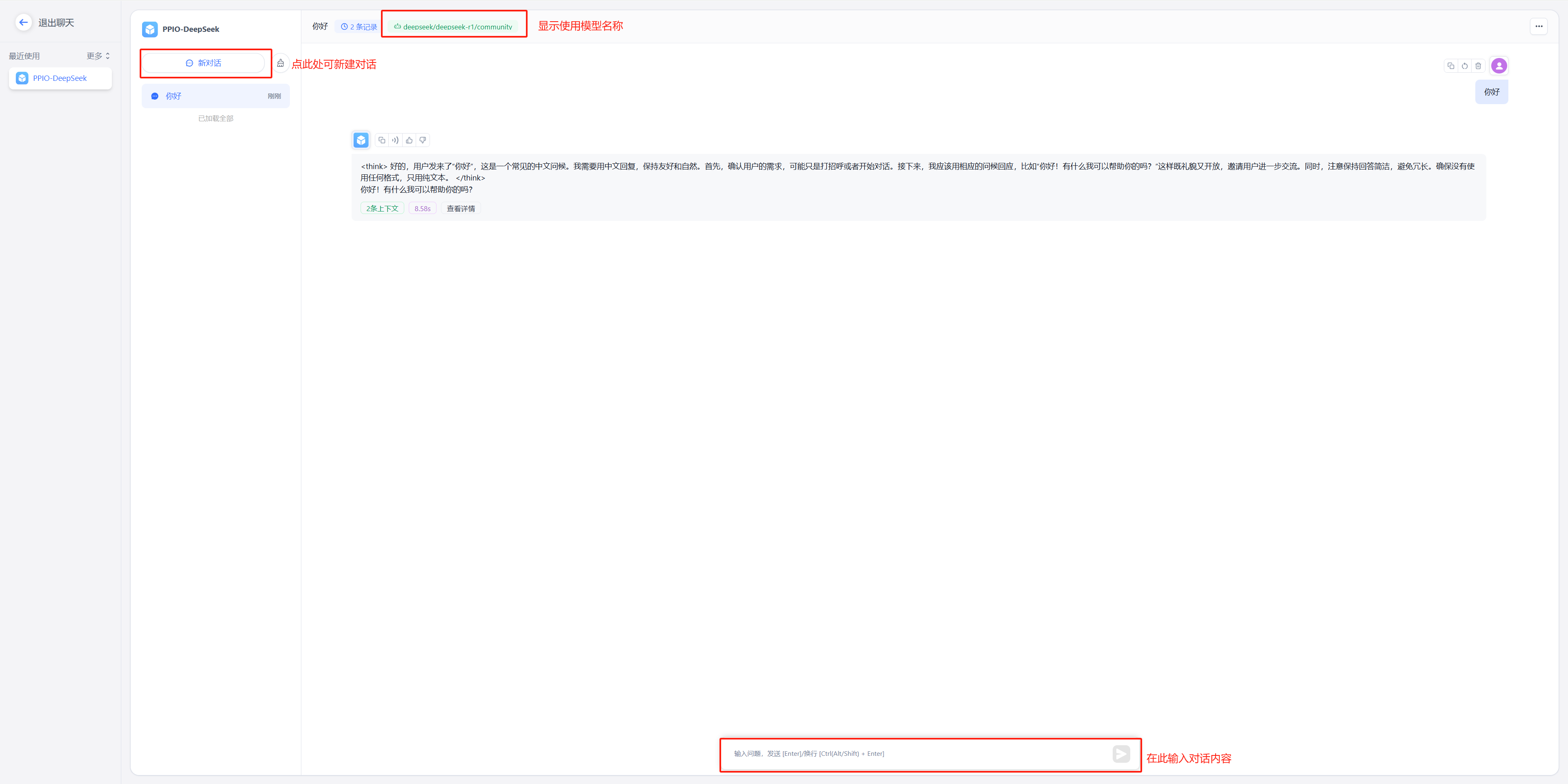
|
||||
|
||||
## PPIO 全新福利重磅来袭 🔥
|
||||
顺利完成教程配置步骤后,您将解锁两大权益:1. 畅享 PPIO 高速通道与 FastGPT 的效能组合;2.立即激活 **「新用户邀请奖励」** ————通过专属邀请码邀好友注册,您与好友可各领 50 元代金券,硬核福利助力 AI 工具效率倍增!
|
||||
|
||||
🎁 新手专享:立即使用邀请码【VOJL20】完成注册,50 元代金券奖励即刻到账!
|
||||
@@ -1063,10 +1063,12 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/collect
|
||||
|
||||
| 字段 | 类型 | 说明 | 必填 |
|
||||
| --- | --- | --- | --- |
|
||||
| defaultIndex | Boolean | 是否为默认索引 | ✅ |
|
||||
| dataId | String | 关联的向量ID | ✅ |
|
||||
| type | String | 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 | |
|
||||
| dataId | String | 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 | |
|
||||
| text | String | 文本内容 | ✅ |
|
||||
|
||||
`type` 不填则默认为 `custom` 索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。
|
||||
|
||||
### 为集合批量添加添加数据
|
||||
|
||||
注意,每次最多推送 200 组数据。
|
||||
@@ -1298,8 +1300,7 @@ curl --location --request GET 'http://localhost:3000/api/core/dataset/data/detai
|
||||
"chunkIndex": 0,
|
||||
"indexes": [
|
||||
{
|
||||
"defaultIndex": true,
|
||||
"type": "chunk",
|
||||
"type": "default",
|
||||
"dataId": "3720083",
|
||||
"text": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
|
||||
"_id": "65abd4b29d1448617cba61dc"
|
||||
@@ -1335,12 +1336,18 @@ curl --location --request PUT 'http://localhost:3000/api/core/dataset/data/updat
|
||||
"a":"sss",
|
||||
"indexes":[
|
||||
{
|
||||
"dataId": "xxx",
|
||||
"defaultIndex":false,
|
||||
"text":"自定义索引1"
|
||||
"dataId": "xxxx",
|
||||
"type": "default",
|
||||
"text": "默认索引"
|
||||
},
|
||||
{
|
||||
"text":"修改后的自定义索引2。(会删除原来的自定义索引2,并插入新的自定义索引2)"
|
||||
"dataId": "xxx",
|
||||
"type": "custom",
|
||||
"text": "旧的自定义索引1"
|
||||
},
|
||||
{
|
||||
"type":"custom",
|
||||
"text":"新增的自定义索引"
|
||||
}
|
||||
]
|
||||
}'
|
||||
|
||||
@@ -9,7 +9,7 @@ weight: 951
|
||||
|
||||
## 登录 Sealos
|
||||
|
||||
[Sealos](https://cloud.sealos.io/)
|
||||
[Sealos](https://cloud.sealos.io?uid=fnWRt09fZP)
|
||||
|
||||
## 创建应用
|
||||
|
||||
|
||||
@@ -26,13 +26,13 @@ FastGPT 使用了 one-api 项目来管理模型池,其可以兼容 OpenAI 、A
|
||||
|
||||
新加披区的服务器在国外,可以直接访问 OpenAI,但国内用户需要梯子才可以正常访问新加坡区。国际区价格稍贵,点击下面按键即可部署👇
|
||||
|
||||
<a href="https://template.cloud.sealos.io/deploy?templateName=fastgpt" rel="external" target="_blank"><img src="https://cdn.jsdelivr.net/gh/labring-actions/templates@main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||||
<a href="https://template.cloud.sealos.io/deploy?templateName=fastgpt&uid=fnWRt09fZP" rel="external" target="_blank"><img src="https://cdn.jsdelivr.net/gh/labring-actions/templates@main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||||
|
||||
### 北京区
|
||||
|
||||
北京区服务提供商为火山云,国内用户可以稳定访问,但无法访问 OpenAI 等境外服务,价格约为新加坡区的 1/4。点击下面按键即可部署👇
|
||||
|
||||
<a href="https://bja.sealos.run/?openapp=system-template%3FtemplateName%3Dfastgpt" rel="external" target="_blank"><img src="https://raw.githubusercontent.com/labring-actions/templates/main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||||
<a href="https://bja.sealos.run/?openapp=system-template%3FtemplateName%3Dfastgpt&uid=fnWRt09fZP" rel="external" target="_blank"><img src="https://raw.githubusercontent.com/labring-actions/templates/main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||||
|
||||
### 1. 开始部署
|
||||
|
||||
|
||||
@@ -13,7 +13,7 @@ FastGPT V4.5 引入 PgVector0.5 版本的 HNSW 索引,极大的提高了知识
|
||||
|
||||
## PgVector升级:Sealos 部署方案
|
||||
|
||||
1. 点击[Sealos桌面](https://cloud.sealos.io)的数据库应用。
|
||||
1. 点击[Sealos桌面](https://cloud.sealos.io?uid=fnWRt09fZP)的数据库应用。
|
||||
2. 点击【pg】数据库的详情。
|
||||
3. 点击右上角的重启,等待重启完成。
|
||||
4. 点击左侧的一键链接,等待打开 Terminal。
|
||||
|
||||
@@ -35,7 +35,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv4820' \
|
||||
|
||||
## 完整更新内容
|
||||
|
||||
1. 新增 - 可视化模型参数配置,取代原配置文件配置模型。预设超过 100 个模型配置。同时支持所有类型模型的一键测试。(预计下个版本会完全支持在页面上配置渠道)。
|
||||
1. 新增 - 可视化模型参数配置,取代原配置文件配置模型。预设超过 100 个模型配置。同时支持所有类型模型的一键测试。(预计下个版本会完全支持在页面上配置渠道)。[点击查看模型配置方案](/docs/development/modelconfig/intro/)
|
||||
2. 新增 - DeepSeek resoner 模型支持输出思考过程。
|
||||
3. 新增 - 使用记录导出和仪表盘。
|
||||
4. 新增 - markdown 语法扩展,支持音视频(代码块 audio 和 video)。
|
||||
|
||||
@@ -4,7 +4,7 @@ description: 'FastGPT V4.8.23 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 802
|
||||
weight: 801
|
||||
---
|
||||
|
||||
## 更新指南
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
---
|
||||
title: 'V4.9.0(进行中)'
|
||||
title: 'V4.9.0(包含升级脚本)'
|
||||
description: 'FastGPT V4.9.0 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 801
|
||||
weight: 800
|
||||
---
|
||||
|
||||
|
||||
@@ -12,9 +12,141 @@ weight: 801
|
||||
|
||||
### 1. 做好数据库备份
|
||||
|
||||
### 2. 更新镜像
|
||||
### 2. 更新镜像和 PG 容器
|
||||
|
||||
### 3. 运行升级脚本
|
||||
- 更新 FastGPT 镜像 tag: v4.9.0
|
||||
- 更新 FastGPT 商业版镜像 tag: v4.9.0
|
||||
- Sandbox 镜像,可以不更新
|
||||
- 更新 PG 容器为 v0.8.0-pg15, 可以查看[最新的 yml](https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml)
|
||||
|
||||
### 3. 替换 OneAPI(可选)
|
||||
|
||||
如果需要使用 [AI Proxy](https://github.com/labring/aiproxy) 替换 OneAPI 的用户可执行该步骤。
|
||||
|
||||
#### 1. 修改 yml 文件
|
||||
|
||||
参考[最新的 yml](https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml) 文件。里面已移除 OneAPI 并添加了 AIProxy配置。包含一个服务和一个 PgSQL 数据库。将 `aiproxy` 的配置`追加`到 OneAPI 的配置后面(先不要删除 OneAPI,有一个初始化会自动同步 OneAPI 的配置)
|
||||
|
||||
{{% details title="AI Proxy Yml 配置" closed="true" %}}
|
||||
|
||||
```
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: 'ghcr.io/labring/aiproxy:latest'
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
aiproxy_pg:
|
||||
condition: service_healthy
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
# 对应 fastgpt 里的AIPROXY_API_TOKEN
|
||||
- ADMIN_KEY=aiproxy
|
||||
# 错误日志详情保存时间(小时)
|
||||
- LOG_DETAIL_STORAGE_HOURS=1
|
||||
# 数据库连接地址
|
||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||
# 最大重试次数
|
||||
- RETRY_TIMES=3
|
||||
# 不需要计费
|
||||
- BILLING_ENABLED=false
|
||||
# 不需要严格检测模型
|
||||
- DISABLE_MODEL_CONFIG=true
|
||||
healthcheck:
|
||||
test: ['CMD', 'curl', '-f', 'http://localhost:3000/api/status']
|
||||
interval: 5s
|
||||
timeout: 5s
|
||||
retries: 10
|
||||
aiproxy_pg:
|
||||
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
restart: unless-stopped
|
||||
container_name: aiproxy_pg
|
||||
volumes:
|
||||
- ./aiproxy_pg:/var/lib/postgresql/data
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
POSTGRES_USER: postgres
|
||||
POSTGRES_DB: aiproxy
|
||||
POSTGRES_PASSWORD: aiproxy
|
||||
healthcheck:
|
||||
test: ['CMD', 'pg_isready', '-U', 'postgres', '-d', 'aiproxy']
|
||||
interval: 5s
|
||||
timeout: 5s
|
||||
retries: 10
|
||||
```
|
||||
|
||||
{{% /details %}}
|
||||
|
||||
#### 2. 增加 FastGPT 环境变量:
|
||||
|
||||
修改 yml 文件中,fastgpt 容器的环境变量:
|
||||
|
||||
```
|
||||
# AI Proxy 的地址,如果配了该地址,优先使用
|
||||
- AIPROXY_API_ENDPOINT=http://aiproxy:3000
|
||||
# AI Proxy 的 Admin Token,与 AI Proxy 中的环境变量 ADMIN_KEY
|
||||
- AIPROXY_API_TOKEN=aiproxy
|
||||
```
|
||||
|
||||
#### 3. 重载服务
|
||||
|
||||
`docker-compose down` 停止服务,然后 `docker-compose up -d` 启动服务,此时会追加 `aiproxy` 服务,并修改 FastGPT 的配置。
|
||||
|
||||
#### 4. 执行OneAPI迁移AI proxy脚本
|
||||
|
||||
- 可联网方案:
|
||||
|
||||
```bash
|
||||
# 进入 aiproxy 容器
|
||||
docker exec -it aiproxy sh
|
||||
# 安装 curl
|
||||
apk add curl
|
||||
# 执行脚本
|
||||
curl --location --request POST 'http://localhost:3000/api/channels/import/oneapi' \
|
||||
--header 'Authorization: Bearer aiproxy' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{
|
||||
"dsn": "mysql://root:oneapimmysql@tcp(mysql:3306)/oneapi"
|
||||
}'
|
||||
# 返回 {"data":[],"success":true} 代表成功
|
||||
```
|
||||
|
||||
- 无法联网时,可打开`aiproxy`的外网暴露端口,然后在本地执行脚本。
|
||||
|
||||
aiProxy 暴露端口:3003:3000,修改后重新 `docker-compose up -d` 启动服务。
|
||||
|
||||
```bash
|
||||
# 在终端执行脚本
|
||||
curl --location --request POST 'http://localhost:3003/api/channels/import/oneapi' \
|
||||
--header 'Authorization: Bearer aiproxy' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{
|
||||
"dsn": "mysql://root:oneapimmysql@tcp(mysql:3306)/oneapi"
|
||||
}'
|
||||
# 返回 {"data":[],"success":true} 代表成功
|
||||
```
|
||||
|
||||
- 如果不熟悉 docker 操作,建议不要走脚本迁移,直接删除 OneAPI 所有内容,然后手动重新添加渠道。
|
||||
|
||||
#### 5. 进入 FastGPT 检查`AI Proxy` 服务是否正常启动。
|
||||
|
||||
登录 root 账号后,在`账号-模型提供商`页面,可以看到多出了`模型渠道`和`调用日志`两个选项,打开模型渠道,可以看到之前 OneAPI 的渠道,说明迁移完成,此时可以手动再检查下渠道是否正常。
|
||||
|
||||
#### 6. 删除 OneAPI 服务
|
||||
|
||||
```bash
|
||||
# 停止服务,或者针对性停止 OneAPI 和其 Mysql
|
||||
docker-compose down
|
||||
# yml 文件中删除 OneAPI 和其 Mysql 依赖
|
||||
# 重启服务
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
### 4. 运行 FastGPT 升级脚本
|
||||
|
||||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||||
|
||||
@@ -28,7 +160,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv490' \
|
||||
|
||||
1. 升级 PG Vector 插件版本
|
||||
2. 全量更新知识库集合字段。
|
||||
3. 全量更新知识库数据中,index 的 type 类型。(时间较长)
|
||||
3. 全量更新知识库数据中,index 的 type 类型。(时间较长,最后可能提示 timeout,可忽略,数据库不崩都会一直增量执行)
|
||||
|
||||
## 兼容 & 弃用
|
||||
|
||||
@@ -42,6 +174,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv490' \
|
||||
1. PDF增强解析交互添加到页面上。同时内嵌 Doc2x 服务,可直接使用 Doc2x 服务解析 PDF 文件。
|
||||
2. 图片自动标注,同时修改知识库文件上传部分数据逻辑和交互。
|
||||
3. pg vector 插件升级 0.8.0 版本,引入迭代搜索,减少部分数据无法被检索的情况。
|
||||
4. 新增 qwen-qwq 系列模型配置。
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
@@ -49,8 +182,9 @@ curl --location --request POST 'https://{{host}}/api/admin/initv490' \
|
||||
2. Markdown 解析,增加链接后中文标点符号检测,增加空格。
|
||||
3. Prompt 模式工具调用,支持思考模型。同时优化其格式检测,减少空输出的概率。
|
||||
4. Mongo 文件读取流合并,减少计算量。同时优化存储 chunks,极大提高大文件读取速度。50M PDF 读取时间提高 3 倍。
|
||||
5. HTTP Body 适配,增加对字符串对象的适配。
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
1. 增加网页抓取安全链接校验。
|
||||
2. 批量运行时,全局变量未进一步传递到下一次运行中,导致最终变量更新错误。
|
||||
2. 批量运行时,全局变量未进一步传递到下一次运行中,导致最终变量更新错误。
|
||||
|
||||
65
docSite/content/zh-cn/docs/development/upgrading/491.md
Normal file
65
docSite/content/zh-cn/docs/development/upgrading/491.md
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: 'V4.9.1'
|
||||
description: 'FastGPT V4.9.1 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 799
|
||||
---
|
||||
|
||||
## 更新指南
|
||||
|
||||
### 1. 做好数据库备份
|
||||
|
||||
### 2. 更新镜像
|
||||
|
||||
- 更新 FastGPT 镜像 tag: v4.9.1-fix2
|
||||
- 更新 FastGPT 商业版镜像 tag: v4.9.1-fix2
|
||||
- Sandbox 镜像,可以不更新
|
||||
- AIProxy 镜像修改为: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3
|
||||
|
||||
### 3. 执行升级脚本
|
||||
|
||||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||
--header 'rootkey: {{rootkey}}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
**脚本功能**
|
||||
|
||||
重新使用最新的 jieba 分词库进行分词处理。时间较长,可以从日志里查看进度。
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
1. 商业版支持单团队模式,更好的管理内部成员。
|
||||
2. 知识库分块阅读器。
|
||||
3. API 知识库支持 PDF 增强解析。
|
||||
4. 邀请团队成员,改为邀请链接模式。
|
||||
5. 支持混合检索权重设置。
|
||||
6. 支持重排模型选择和权重设置,同时调整了知识库搜索权重计算方式,改成 搜索权重 + 重排权重,而不是向量检索权重+全文检索权重+重排权重。
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
1. 知识库数据输入框交互
|
||||
2. 应用拉取绑定知识库数据交由后端处理。
|
||||
3. 增加依赖包安全版本检测,并升级部分依赖包。
|
||||
4. 模型测试代码。
|
||||
5. 优化思考过程解析逻辑:只要配置了模型支持思考,均会解析 <think> 标签,不会因为对话时,关闭思考而不解析。
|
||||
6. 载入最新 jieba 分词库,增强全文检索分词效果。
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
1. 最大响应 tokens 提示显示错误的问题。
|
||||
2. HTTP Node 中,字符串包含换行符时,会解析失败。
|
||||
3. 知识库问题优化中,未传递历史记录。
|
||||
4. 错误提示翻译缺失。
|
||||
5. 内容提取节点,array 类型 schema 错误。
|
||||
6. 模型渠道测试时,实际未指定渠道测试。
|
||||
7. 新增自定义模型时,会把默认模型字段也保存,导致默认模型误判。
|
||||
8. 修复 promp 模式工具调用,未判空思考链,导致 UI 错误展示。
|
||||
9. 编辑应用信息导致头像丢失。
|
||||
10. 分享链接标题会被刷新掉。
|
||||
11. 计算 parentPath 时,存在鉴权失败清空。
|
||||
@@ -30,7 +30,7 @@ FastGPT 升级包括两个步骤:
|
||||
|
||||
## Sealos 修改镜像
|
||||
|
||||
1. 打开 [Sealos Cloud](https://cloud.sealos.io/), 找到桌面上的应用管理
|
||||
1. 打开 [Sealos Cloud](https://cloud.sealos.io?uid=fnWRt09fZP), 找到桌面上的应用管理
|
||||
|
||||

|
||||
|
||||
|
||||
@@ -14,7 +14,7 @@ weight: 303
|
||||
|
||||
这里介绍在 Sealos 中部署 SearXNG 的方法。Docker 部署,可以直接参考 [SearXNG 官方教程](https://github.com/searxng/searxng)。
|
||||
|
||||
点击打开 [Sealos 北京区](https://bja.sealos.run/),点击应用部署,并新建一个应用:
|
||||
点击打开 [Sealos 北京区](https://bja.sealos.run?uid=fnWRt09fZP),点击应用部署,并新建一个应用:
|
||||
|
||||
| 打开应用部署 | 点击新建应用 |
|
||||
| --- | --- |
|
||||
@@ -130,7 +130,7 @@ doi_resolvers:
|
||||
default_doi_resolver: 'oadoi.org'
|
||||
```
|
||||
|
||||
国内目前只有 Bing 引擎可以正常用,所以上面的配置只配置了 bing 引擎。如果在海外部署,可以使用[Sealos 新加坡可用区](https://cloud.sealos.io/),并配置其他搜索引擎,可以参考[SearXNG 默认配置文件](https://github.com/searxng/searxng/blob/master/searx/settings.yml), 从里面复制一些 engine 配置。例如:
|
||||
国内目前只有 Bing 引擎可以正常用,所以上面的配置只配置了 bing 引擎。如果在海外部署,可以使用[Sealos 新加坡可用区](https://cloud.sealos.io?uid=fnWRt09fZP),并配置其他搜索引擎,可以参考[SearXNG 默认配置文件](https://github.com/searxng/searxng/blob/master/searx/settings.yml), 从里面复制一些 engine 配置。例如:
|
||||
|
||||
```
|
||||
- name: duckduckgo
|
||||
|
||||
@@ -0,0 +1,66 @@
|
||||
---
|
||||
title: "邀请链接说明文档"
|
||||
description: "如何使用邀请链接来邀请团队成员"
|
||||
icon: "group"
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 451
|
||||
---
|
||||
|
||||
v4.9.1 团队邀请成员将开始使用「邀请链接」的模式,弃用之前输入用户名进行添加的形式。
|
||||
|
||||
在版本升级后,原收到邀请还未加入团队的成员,将自动清除邀请。请使用邀请链接重新邀请成员。
|
||||
|
||||
## 如何使用
|
||||
|
||||
1. **在团队管理页面,管理员可点击「邀请成员」按钮打开邀请成员弹窗**
|
||||
|
||||

|
||||
|
||||
2. **在邀请成员弹窗中,点击「创建邀请链接」按钮,创建邀请链接。**
|
||||
|
||||

|
||||
|
||||
3. **输入对应内容**
|
||||
|
||||

|
||||
|
||||
链接描述:建议将链接描述为使用场景或用途。链接创建后不支持修改噢。
|
||||
|
||||
有效期:30分钟,7天,1年
|
||||
|
||||
有效人数:1人,无限制
|
||||
|
||||
4. **点击复制链接,并将其发送给想要邀请的人。**
|
||||
|
||||

|
||||
|
||||
5. **用户访问链接后,如果未登录/未注册,则先跳转到登录页面进行登录。在登录后将进入团队页面,处理邀请。**
|
||||
|
||||
> 邀请链接形如:fastgpt.cn/account/team?invitelinkid=xxxx
|
||||
|
||||

|
||||
|
||||
点击接受,则用户将加入团队
|
||||
|
||||
点击忽略,则关闭弹窗,用户下次访问该邀请链接则还可以选择加入。
|
||||
|
||||
## 链接失效和自动清理
|
||||
|
||||
### 链接失效原因
|
||||
|
||||
手动停用链接
|
||||
|
||||
邀请链接到达有效期,自动停用
|
||||
|
||||
有效人数为1人的链接,已有1人通过邀请链接加入团队。
|
||||
|
||||
停用的链接无法访问,也无法再次启用。
|
||||
|
||||
### 链接上限
|
||||
|
||||
一个用户最多可以同时存在 10 个**有效的**邀请链接。
|
||||
|
||||
### 链接自动清理
|
||||
|
||||
失效的链接将在 30 天后自动清理。
|
||||
@@ -89,6 +89,12 @@ weight: 506
|
||||
47.99.59.223
|
||||
112.124.46.5
|
||||
121.40.46.247
|
||||
120.26.145.73
|
||||
120.26.147.199
|
||||
121.43.125.163
|
||||
121.196.228.45
|
||||
121.43.126.202
|
||||
120.26.144.37
|
||||
```
|
||||
|
||||
## 4. 获取AES Key,选择加密方式
|
||||
|
||||
@@ -27,7 +27,7 @@ weight: 510
|
||||
|
||||
## sealos部署服务
|
||||
|
||||
[访问sealos](https://cloud.sealos.run/) 登录进来之后打开「应用管理」-> 「新建应用」。
|
||||
[访问sealos](https://hzh.sealos.run?uid=fnWRt09fZP) 登录进来之后打开「应用管理」-> 「新建应用」。
|
||||
- 应用名:称随便填写
|
||||
- 镜像名:私人微信填写 aibotk/wechat-assistant 企业微信填写 aibotk/worker-assistant
|
||||
- cpu和内存建议 1c1g
|
||||
|
||||
14
package.json
14
package.json
@@ -11,16 +11,22 @@
|
||||
"initIcon": "node ./scripts/icon/init.js",
|
||||
"previewIcon": "node ./scripts/icon/index.js",
|
||||
"api:gen": "tsc ./scripts/openapi/index.ts && node ./scripts/openapi/index.js && npx @redocly/cli build-docs ./scripts/openapi/openapi.json -o ./projects/app/public/openapi/index.html",
|
||||
"create:i18n": "node ./scripts/i18n/index.js"
|
||||
"create:i18n": "node ./scripts/i18n/index.js",
|
||||
"test": "vitest run --exclude 'test/cases/spec'",
|
||||
"test:all": "vitest run",
|
||||
"test:workflow": "vitest run workflow"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@chakra-ui/cli": "^2.4.1",
|
||||
"@vitest/coverage-v8": "^3.0.2",
|
||||
"husky": "^8.0.3",
|
||||
"i18next": "23.16.8",
|
||||
"lint-staged": "^13.3.0",
|
||||
"i18next": "23.11.5",
|
||||
"next-i18next": "15.3.0",
|
||||
"react-i18next": "14.1.2",
|
||||
"next-i18next": "15.4.2",
|
||||
"prettier": "3.2.4",
|
||||
"react-i18next": "14.1.2",
|
||||
"vitest": "^3.0.2",
|
||||
"vitest-mongodb": "^1.0.1",
|
||||
"zhlint": "^0.7.4"
|
||||
},
|
||||
"lint-staged": {
|
||||
|
||||
@@ -24,7 +24,10 @@ export enum TeamErrEnum {
|
||||
cannotModifyRootOrg = 'cannotModifyRootOrg',
|
||||
cannotDeleteNonEmptyOrg = 'cannotDeleteNonEmptyOrg',
|
||||
cannotDeleteDefaultGroup = 'cannotDeleteDefaultGroup',
|
||||
userNotActive = 'userNotActive'
|
||||
userNotActive = 'userNotActive',
|
||||
invitationLinkInvalid = 'invitationLinkInvalid',
|
||||
youHaveBeenInTheTeam = 'youHaveBeenInTheTeam',
|
||||
tooManyInvitations = 'tooManyInvitations'
|
||||
}
|
||||
|
||||
const teamErr = [
|
||||
@@ -112,6 +115,18 @@ const teamErr = [
|
||||
{
|
||||
statusText: TeamErrEnum.cannotDeleteNonEmptyOrg,
|
||||
message: i18nT('common:code_error.team_error.cannot_delete_non_empty_org')
|
||||
},
|
||||
{
|
||||
statusText: TeamErrEnum.invitationLinkInvalid,
|
||||
message: i18nT('common:code_error.team_error.invitation_link_invalid')
|
||||
},
|
||||
{
|
||||
statusText: TeamErrEnum.youHaveBeenInTheTeam,
|
||||
message: i18nT('common:code_error.team_error.you_have_been_in_the_team')
|
||||
},
|
||||
{
|
||||
statusText: TeamErrEnum.tooManyInvitations,
|
||||
message: i18nT('common:code_error.team_error.too_many_invitations')
|
||||
}
|
||||
];
|
||||
|
||||
|
||||
@@ -1,3 +1,8 @@
|
||||
export type GetPathProps = {
|
||||
sourceId?: ParentIdType;
|
||||
type: 'current' | 'parent';
|
||||
};
|
||||
|
||||
export type ParentTreePathItemType = {
|
||||
parentId: string;
|
||||
parentName: string;
|
||||
|
||||
@@ -168,7 +168,7 @@ export const markdownProcess = async ({
|
||||
return simpleMarkdownText(imageProcess);
|
||||
};
|
||||
|
||||
export const matchMdImgTextAndUpload = (text: string) => {
|
||||
export const matchMdImg = (text: string) => {
|
||||
const base64Regex = /!\[([^\]]*)\]\((data:image\/[^;]+;base64[^)]+)\)/g;
|
||||
const imageList: ImageType[] = [];
|
||||
|
||||
|
||||
@@ -93,7 +93,7 @@ ${mdSplitString}
|
||||
|
||||
/*
|
||||
1. 自定义分隔符:不需要重叠,不需要小块合并
|
||||
2. Markdown 标题:不需要重叠;标题嵌套共享,不需要小块合并
|
||||
2. Markdown 标题:不需要重叠;标题嵌套共享,需要小块合并
|
||||
3. 特殊 markdown 语法:不需要重叠,需要小块合并
|
||||
4. 段落:尽可能保证它是一个完整的段落。
|
||||
5. 标点分割:重叠
|
||||
@@ -227,7 +227,7 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
}): string[] => {
|
||||
const isMarkdownStep = checkIsMarkdownSplit(step);
|
||||
const isCustomStep = checkIsCustomStep(step);
|
||||
const forbidConcat = isMarkdownStep || isCustomStep; // forbid=true时候,lastText肯定为空
|
||||
const forbidConcat = isCustomStep; // forbid=true时候,lastText肯定为空
|
||||
|
||||
// oversize
|
||||
if (step >= stepReges.length) {
|
||||
|
||||
@@ -6,7 +6,7 @@ import type {
|
||||
EmbeddingModelItemType,
|
||||
AudioSpeechModels,
|
||||
STTModelType,
|
||||
ReRankModelItemType
|
||||
RerankModelItemType
|
||||
} from '../../../core/ai/model.d';
|
||||
import { SubTypeEnum } from '../../../support/wallet/sub/constants';
|
||||
|
||||
@@ -35,7 +35,7 @@ export type FastGPTConfigFileType = {
|
||||
// Abandon
|
||||
llmModels?: ChatModelItemType[];
|
||||
vectorModels?: EmbeddingModelItemType[];
|
||||
reRankModels?: ReRankModelItemType[];
|
||||
reRankModels?: RerankModelItemType[];
|
||||
audioSpeechModels?: TTSModelType[];
|
||||
whisperModel?: STTModelType;
|
||||
};
|
||||
|
||||
2
packages/global/core/ai/model.d.ts
vendored
2
packages/global/core/ai/model.d.ts
vendored
@@ -72,7 +72,7 @@ export type EmbeddingModelItemType = PriceType &
|
||||
queryConfig?: Record<string, any>; // Custom parameters for query
|
||||
};
|
||||
|
||||
export type ReRankModelItemType = PriceType &
|
||||
export type RerankModelItemType = PriceType &
|
||||
BaseModelItemType & {
|
||||
type: ModelTypeEnum.rerank;
|
||||
};
|
||||
|
||||
23
packages/global/core/app/type.d.ts
vendored
23
packages/global/core/app/type.d.ts
vendored
@@ -71,6 +71,20 @@ export type AppDetailType = AppSchema & {
|
||||
permission: AppPermission;
|
||||
};
|
||||
|
||||
export type AppDatasetSearchParamsType = {
|
||||
searchMode: `${DatasetSearchModeEnum}`;
|
||||
limit?: number; // limit max tokens
|
||||
similarity?: number;
|
||||
embeddingWeight?: number; // embedding weight, fullText weight = 1 - embeddingWeight
|
||||
|
||||
usingReRank?: boolean;
|
||||
rerankModel?: string;
|
||||
rerankWeight?: number;
|
||||
|
||||
datasetSearchUsingExtensionQuery?: boolean;
|
||||
datasetSearchExtensionModel?: string;
|
||||
datasetSearchExtensionBg?: string;
|
||||
};
|
||||
export type AppSimpleEditFormType = {
|
||||
// templateId: string;
|
||||
aiSettings: {
|
||||
@@ -88,14 +102,7 @@ export type AppSimpleEditFormType = {
|
||||
};
|
||||
dataset: {
|
||||
datasets: SelectedDatasetType;
|
||||
searchMode: `${DatasetSearchModeEnum}`;
|
||||
similarity?: number;
|
||||
limit?: number;
|
||||
usingReRank?: boolean;
|
||||
datasetSearchUsingExtensionQuery?: boolean;
|
||||
datasetSearchExtensionModel?: string;
|
||||
datasetSearchExtensionBg?: string;
|
||||
};
|
||||
} & AppDatasetSearchParamsType;
|
||||
selectedTools: FlowNodeTemplateType[];
|
||||
chatConfig: AppChatConfigType;
|
||||
};
|
||||
|
||||
@@ -24,9 +24,11 @@ export const getDefaultAppForm = (): AppSimpleEditFormType => {
|
||||
dataset: {
|
||||
datasets: [],
|
||||
similarity: 0.4,
|
||||
limit: 1500,
|
||||
limit: 3000,
|
||||
searchMode: DatasetSearchModeEnum.embedding,
|
||||
usingReRank: false,
|
||||
rerankModel: '',
|
||||
rerankWeight: 0.5,
|
||||
datasetSearchUsingExtensionQuery: true,
|
||||
datasetSearchExtensionBg: ''
|
||||
},
|
||||
@@ -70,6 +72,26 @@ export const appWorkflow2Form = ({
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.history
|
||||
);
|
||||
defaultAppForm.aiSettings.aiChatReasoning = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.aiChatReasoning
|
||||
);
|
||||
defaultAppForm.aiSettings.aiChatTopP = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.aiChatTopP
|
||||
);
|
||||
defaultAppForm.aiSettings.aiChatStopSign = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.aiChatStopSign
|
||||
);
|
||||
defaultAppForm.aiSettings.aiChatResponseFormat = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.aiChatResponseFormat
|
||||
);
|
||||
defaultAppForm.aiSettings.aiChatJsonSchema = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.aiChatJsonSchema
|
||||
);
|
||||
} else if (node.flowNodeType === FlowNodeTypeEnum.datasetSearchNode) {
|
||||
defaultAppForm.dataset.datasets = findInputValueByKey(
|
||||
node.inputs,
|
||||
@@ -86,10 +108,24 @@ export const appWorkflow2Form = ({
|
||||
defaultAppForm.dataset.searchMode =
|
||||
findInputValueByKey(node.inputs, NodeInputKeyEnum.datasetSearchMode) ||
|
||||
DatasetSearchModeEnum.embedding;
|
||||
defaultAppForm.dataset.embeddingWeight = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchEmbeddingWeight
|
||||
);
|
||||
// Rerank
|
||||
defaultAppForm.dataset.usingReRank = !!findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchUsingReRank
|
||||
);
|
||||
defaultAppForm.dataset.rerankModel = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchRerankModel
|
||||
);
|
||||
defaultAppForm.dataset.rerankWeight = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchRerankWeight
|
||||
);
|
||||
// Query extension
|
||||
defaultAppForm.dataset.datasetSearchUsingExtensionQuery = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchUsingExtensionQuery
|
||||
|
||||
@@ -256,7 +256,7 @@ export const GPTMessages2Chats = (
|
||||
) {
|
||||
const value: AIChatItemValueItemType[] = [];
|
||||
|
||||
if (typeof item.reasoning_text === 'string') {
|
||||
if (typeof item.reasoning_text === 'string' && item.reasoning_text) {
|
||||
value.push({
|
||||
type: ChatItemValueTypeEnum.reasoning,
|
||||
reasoning: {
|
||||
@@ -323,7 +323,7 @@ export const GPTMessages2Chats = (
|
||||
interactive: item.interactive
|
||||
});
|
||||
}
|
||||
if (typeof item.content === 'string') {
|
||||
if (typeof item.content === 'string' && item.content) {
|
||||
const lastValue = value[value.length - 1];
|
||||
if (lastValue && lastValue.type === ChatItemValueTypeEnum.text && lastValue.text) {
|
||||
lastValue.text.content += item.content;
|
||||
|
||||
1
packages/global/core/chat/type.d.ts
vendored
1
packages/global/core/chat/type.d.ts
vendored
@@ -134,6 +134,7 @@ export type ChatItemType = (UserChatItemType | SystemChatItemType | AIChatItemTy
|
||||
|
||||
// Frontend type
|
||||
export type ChatSiteItemType = (UserChatItemType | SystemChatItemType | AIChatItemType) & {
|
||||
_id?: string;
|
||||
dataId: string;
|
||||
status: `${ChatStatusEnum}`;
|
||||
moduleName?: string;
|
||||
|
||||
@@ -185,7 +185,7 @@ export enum SearchScoreTypeEnum {
|
||||
}
|
||||
export const SearchScoreTypeMap = {
|
||||
[SearchScoreTypeEnum.embedding]: {
|
||||
label: i18nT('common:core.dataset.search.score.embedding'),
|
||||
label: i18nT('common:core.dataset.search.mode.embedding'),
|
||||
desc: i18nT('common:core.dataset.search.score.embedding desc'),
|
||||
showScore: true
|
||||
},
|
||||
|
||||
@@ -16,23 +16,23 @@ export const DatasetDataIndexMap: Record<
|
||||
}
|
||||
> = {
|
||||
[DatasetDataIndexTypeEnum.default]: {
|
||||
label: i18nT('dataset:data_index_default'),
|
||||
label: i18nT('common:data_index_default'),
|
||||
color: 'gray'
|
||||
},
|
||||
[DatasetDataIndexTypeEnum.custom]: {
|
||||
label: i18nT('dataset:data_index_custom'),
|
||||
label: i18nT('common:data_index_custom'),
|
||||
color: 'blue'
|
||||
},
|
||||
[DatasetDataIndexTypeEnum.summary]: {
|
||||
label: i18nT('dataset:data_index_summary'),
|
||||
label: i18nT('common:data_index_summary'),
|
||||
color: 'green'
|
||||
},
|
||||
[DatasetDataIndexTypeEnum.question]: {
|
||||
label: i18nT('dataset:data_index_question'),
|
||||
label: i18nT('common:data_index_question'),
|
||||
color: 'red'
|
||||
},
|
||||
[DatasetDataIndexTypeEnum.image]: {
|
||||
label: i18nT('dataset:data_index_image'),
|
||||
label: i18nT('common:data_index_image'),
|
||||
color: 'purple'
|
||||
}
|
||||
};
|
||||
|
||||
7
packages/global/core/dataset/type.d.ts
vendored
7
packages/global/core/dataset/type.d.ts
vendored
@@ -112,12 +112,15 @@ export type DatasetDataSchemaType = {
|
||||
tmbId: string;
|
||||
datasetId: string;
|
||||
collectionId: string;
|
||||
datasetId: string;
|
||||
collectionId: string;
|
||||
chunkIndex: number;
|
||||
updateTime: Date;
|
||||
q: string; // large chunks or question
|
||||
a: string; // answer or custom content
|
||||
history?: {
|
||||
q: string;
|
||||
a: string;
|
||||
updateTime: Date;
|
||||
}[];
|
||||
forbid?: boolean;
|
||||
fullTextToken: string;
|
||||
indexes: DatasetDataIndexItemType[];
|
||||
|
||||
7
packages/global/core/workflow/api.d.ts
vendored
7
packages/global/core/workflow/api.d.ts
vendored
@@ -1,7 +1,12 @@
|
||||
import { EmbeddingModelItemType } from '../ai/model.d';
|
||||
import { NodeInputKeyEnum } from './constants';
|
||||
|
||||
export type SelectedDatasetType = { datasetId: string }[];
|
||||
export type SelectedDatasetType = {
|
||||
datasetId: string;
|
||||
avatar: string;
|
||||
name: string;
|
||||
vectorModel: EmbeddingModelItemType;
|
||||
}[];
|
||||
|
||||
export type HttpBodyType<T = Record<string, any>> = {
|
||||
// [NodeInputKeyEnum.addInputParam]: Record<string, any>;
|
||||
|
||||
@@ -154,7 +154,12 @@ export enum NodeInputKeyEnum {
|
||||
datasetSimilarity = 'similarity',
|
||||
datasetMaxTokens = 'limit',
|
||||
datasetSearchMode = 'searchMode',
|
||||
datasetSearchEmbeddingWeight = 'embeddingWeight',
|
||||
|
||||
datasetSearchUsingReRank = 'usingReRank',
|
||||
datasetSearchRerankWeight = 'rerankWeight',
|
||||
datasetSearchRerankModel = 'rerankModel',
|
||||
|
||||
datasetSearchUsingExtensionQuery = 'datasetSearchUsingExtensionQuery',
|
||||
datasetSearchExtensionModel = 'datasetSearchExtensionModel',
|
||||
datasetSearchExtensionBg = 'datasetSearchExtensionBg',
|
||||
|
||||
@@ -133,6 +133,9 @@ export type DispatchNodeResponseType = {
|
||||
similarity?: number;
|
||||
limit?: number;
|
||||
searchMode?: `${DatasetSearchModeEnum}`;
|
||||
embeddingWeight?: number;
|
||||
rerankModel?: string;
|
||||
rerankWeight?: number;
|
||||
searchUsingReRank?: boolean;
|
||||
queryExtensionResult?: {
|
||||
model: string;
|
||||
|
||||
@@ -4,7 +4,10 @@ export type ContextExtractAgentItemType = {
|
||||
valueType:
|
||||
| WorkflowIOValueTypeEnum.string
|
||||
| WorkflowIOValueTypeEnum.number
|
||||
| WorkflowIOValueTypeEnum.boolean;
|
||||
| WorkflowIOValueTypeEnum.boolean
|
||||
| WorkflowIOValueTypeEnum.arrayString
|
||||
| WorkflowIOValueTypeEnum.arrayNumber
|
||||
| WorkflowIOValueTypeEnum.arrayBoolean;
|
||||
desc: string;
|
||||
key: string;
|
||||
required: boolean;
|
||||
|
||||
@@ -64,6 +64,14 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
||||
valueType: WorkflowIOValueTypeEnum.string,
|
||||
value: DatasetSearchModeEnum.embedding
|
||||
},
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchEmbeddingWeight,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
label: '',
|
||||
valueType: WorkflowIOValueTypeEnum.number,
|
||||
value: 0.5
|
||||
},
|
||||
// Rerank
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchUsingReRank,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
@@ -71,6 +79,20 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
||||
valueType: WorkflowIOValueTypeEnum.boolean,
|
||||
value: false
|
||||
},
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchRerankModel,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
label: '',
|
||||
valueType: WorkflowIOValueTypeEnum.string
|
||||
},
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchRerankWeight,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
label: '',
|
||||
valueType: WorkflowIOValueTypeEnum.number,
|
||||
value: 0.5
|
||||
},
|
||||
// Query Extension
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchUsingExtensionQuery,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
@@ -91,6 +113,7 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
||||
valueType: WorkflowIOValueTypeEnum.string,
|
||||
value: ''
|
||||
},
|
||||
|
||||
{
|
||||
key: NodeInputKeyEnum.authTmbId,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
|
||||
@@ -3,14 +3,14 @@
|
||||
"version": "1.0.0",
|
||||
"dependencies": {
|
||||
"@apidevtools/swagger-parser": "^10.1.0",
|
||||
"axios": "^1.5.1",
|
||||
"axios": "^1.8.2",
|
||||
"cron-parser": "^4.9.0",
|
||||
"dayjs": "^1.11.7",
|
||||
"encoding": "^0.1.13",
|
||||
"js-yaml": "^4.1.0",
|
||||
"jschardet": "3.1.1",
|
||||
"nanoid": "^4.0.1",
|
||||
"next": "14.2.5",
|
||||
"nanoid": "^5.1.3",
|
||||
"next": "14.2.24",
|
||||
"openai": "4.61.0",
|
||||
"openapi-types": "^12.1.3",
|
||||
"json5": "^2.2.3",
|
||||
|
||||
3
packages/global/support/outLink/type.d.ts
vendored
3
packages/global/support/outLink/type.d.ts
vendored
@@ -63,6 +63,8 @@ export type OutLinkSchema<T extends OutlinkAppType = undefined> = {
|
||||
responseDetail: boolean;
|
||||
// whether to hide the node status
|
||||
showNodeStatus?: boolean;
|
||||
// wheter to show the full text reader
|
||||
// showFullText?: boolean;
|
||||
// whether to show the complete quote
|
||||
showRawSource?: boolean;
|
||||
|
||||
@@ -89,6 +91,7 @@ export type OutLinkEditType<T = undefined> = {
|
||||
name: string;
|
||||
responseDetail?: OutLinkSchema<T>['responseDetail'];
|
||||
showNodeStatus?: OutLinkSchema<T>['showNodeStatus'];
|
||||
// showFullText?: OutLinkSchema<T>['showFullText'];
|
||||
showRawSource?: OutLinkSchema<T>['showRawSource'];
|
||||
// response when request
|
||||
immediateResponse?: string;
|
||||
|
||||
@@ -14,29 +14,28 @@ export const TeamMemberRoleMap = {
|
||||
};
|
||||
|
||||
export enum TeamMemberStatusEnum {
|
||||
waiting = 'waiting',
|
||||
active = 'active',
|
||||
reject = 'reject',
|
||||
leave = 'leave'
|
||||
leave = 'leave',
|
||||
forbidden = 'forbidden'
|
||||
}
|
||||
|
||||
export const TeamMemberStatusMap = {
|
||||
[TeamMemberStatusEnum.waiting]: {
|
||||
label: 'user.team.member.waiting',
|
||||
color: 'orange.600'
|
||||
},
|
||||
[TeamMemberStatusEnum.active]: {
|
||||
label: 'user.team.member.active',
|
||||
color: 'green.600'
|
||||
},
|
||||
[TeamMemberStatusEnum.reject]: {
|
||||
label: 'user.team.member.reject',
|
||||
color: 'red.600'
|
||||
},
|
||||
[TeamMemberStatusEnum.leave]: {
|
||||
label: 'user.team.member.leave',
|
||||
color: 'red.600'
|
||||
},
|
||||
[TeamMemberStatusEnum.forbidden]: {
|
||||
label: 'user.team.member.forbidden',
|
||||
color: 'red.600'
|
||||
}
|
||||
};
|
||||
|
||||
export const notLeaveStatus = { $ne: TeamMemberStatusEnum.leave };
|
||||
export const notLeaveStatus = {
|
||||
$not: {
|
||||
$in: [TeamMemberStatusEnum.leave, TeamMemberStatusEnum.forbidden]
|
||||
}
|
||||
};
|
||||
|
||||
@@ -10,7 +10,6 @@ export type AuthTeamRoleProps = {
|
||||
export type CreateTeamProps = {
|
||||
name: string;
|
||||
avatar?: string;
|
||||
defaultTeam?: boolean;
|
||||
memberName?: string;
|
||||
memberAvatar?: string;
|
||||
notificationAccount?: string;
|
||||
@@ -41,11 +40,6 @@ export type UpdateInviteProps = {
|
||||
status: TeamMemberSchema['status'];
|
||||
};
|
||||
|
||||
export type UpdateStatusProps = {
|
||||
tmbId: string;
|
||||
status: TeamMemberSchema['status'];
|
||||
};
|
||||
|
||||
export type InviteMemberResponse = Record<
|
||||
'invite' | 'inValid' | 'inTeam',
|
||||
{ username: string; userId: string }[]
|
||||
|
||||
2
packages/global/support/user/team/type.d.ts
vendored
2
packages/global/support/user/team/type.d.ts
vendored
@@ -47,7 +47,6 @@ export type TeamMemberSchema = {
|
||||
role: `${TeamMemberRoleEnum}`;
|
||||
status: `${TeamMemberStatusEnum}`;
|
||||
avatar: string;
|
||||
defaultTeam: boolean;
|
||||
};
|
||||
|
||||
export type TeamMemberWithTeamAndUserSchema = TeamMemberSchema & {
|
||||
@@ -65,7 +64,6 @@ export type TeamTmbItemType = {
|
||||
balance?: number;
|
||||
tmbId: string;
|
||||
teamDomain: string;
|
||||
defaultTeam: boolean;
|
||||
role: `${TeamMemberRoleEnum}`;
|
||||
status: `${TeamMemberStatusEnum}`;
|
||||
notificationAccount?: string;
|
||||
|
||||
@@ -5,7 +5,7 @@
|
||||
"dependencies": {
|
||||
"cheerio": "1.0.0-rc.12",
|
||||
"@types/pg": "^8.6.6",
|
||||
"axios": "^1.5.1",
|
||||
"axios": "^1.8.2",
|
||||
"duck-duck-scrape": "^2.2.5",
|
||||
"echarts": "5.4.1",
|
||||
"expr-eval": "^2.0.2",
|
||||
|
||||
@@ -6,6 +6,7 @@ import { guessBase64ImageType } from '../utils';
|
||||
import { readFromSecondary } from '../../mongo/utils';
|
||||
import { addHours } from 'date-fns';
|
||||
import { imageFileType } from '@fastgpt/global/common/file/constants';
|
||||
import { retryFn } from '@fastgpt/global/common/system/utils';
|
||||
|
||||
export const maxImgSize = 1024 * 1024 * 12;
|
||||
const base64MimeRegex = /data:image\/([^\)]+);base64/;
|
||||
@@ -40,13 +41,15 @@ export async function uploadMongoImg({
|
||||
return Promise.reject(`Invalid image file type: ${mime}`);
|
||||
}
|
||||
|
||||
const { _id } = await MongoImage.create({
|
||||
teamId,
|
||||
binary,
|
||||
metadata: Object.assign({ mime }, metadata),
|
||||
shareId,
|
||||
expiredTime: forever ? undefined : addHours(new Date(), 1)
|
||||
});
|
||||
const { _id } = await retryFn(() =>
|
||||
MongoImage.create({
|
||||
teamId,
|
||||
binary,
|
||||
metadata: Object.assign({ mime }, metadata),
|
||||
shareId,
|
||||
expiredTime: forever ? undefined : addHours(new Date(), 1)
|
||||
})
|
||||
);
|
||||
|
||||
return `${process.env.NEXT_PUBLIC_BASE_URL || ''}${imageBaseUrl}${String(_id)}.${extension}`;
|
||||
}
|
||||
@@ -73,7 +76,7 @@ export const refreshSourceAvatar = async (
|
||||
const newId = getIdFromPath(path);
|
||||
const oldId = getIdFromPath(oldPath);
|
||||
|
||||
if (!newId) return;
|
||||
if (!newId || newId === oldId) return;
|
||||
|
||||
await MongoImage.updateOne({ _id: newId }, { $unset: { expiredTime: 1 } }, { session });
|
||||
|
||||
|
||||
@@ -2,23 +2,30 @@ import axios from 'axios';
|
||||
import { addLog } from '../../system/log';
|
||||
import { serverRequestBaseUrl } from '../../api/serverRequest';
|
||||
import { getFileContentTypeFromHeader, guessBase64ImageType } from '../utils';
|
||||
import { retryFn } from '@fastgpt/global/common/system/utils';
|
||||
|
||||
export const getImageBase64 = async (url: string) => {
|
||||
addLog.debug(`Load image to base64: ${url}`);
|
||||
|
||||
try {
|
||||
const response = await axios.get(url, {
|
||||
baseURL: serverRequestBaseUrl,
|
||||
responseType: 'arraybuffer',
|
||||
proxy: false
|
||||
});
|
||||
const response = await retryFn(() =>
|
||||
axios.get(url, {
|
||||
baseURL: serverRequestBaseUrl,
|
||||
responseType: 'arraybuffer',
|
||||
proxy: false
|
||||
})
|
||||
);
|
||||
|
||||
const base64 = Buffer.from(response.data, 'binary').toString('base64');
|
||||
const imageType =
|
||||
getFileContentTypeFromHeader(response.headers['content-type']) ||
|
||||
guessBase64ImageType(base64);
|
||||
|
||||
return `data:${imageType};base64,${base64}`;
|
||||
return {
|
||||
completeBase64: `data:${imageType};base64,${base64}`,
|
||||
base64,
|
||||
mime: imageType
|
||||
};
|
||||
} catch (error) {
|
||||
addLog.debug(`Load image to base64 failed: ${url}`);
|
||||
console.log(error);
|
||||
|
||||
@@ -6,11 +6,12 @@ import type { ImageType, ReadFileResponse } from '../../../worker/readFile/type'
|
||||
import axios from 'axios';
|
||||
import { addLog } from '../../system/log';
|
||||
import { batchRun } from '@fastgpt/global/common/system/utils';
|
||||
import { htmlTable2Md, matchMdImgTextAndUpload } from '@fastgpt/global/common/string/markdown';
|
||||
import { htmlTable2Md, matchMdImg } from '@fastgpt/global/common/string/markdown';
|
||||
import { createPdfParseUsage } from '../../../support/wallet/usage/controller';
|
||||
import { getErrText } from '@fastgpt/global/common/error/utils';
|
||||
import { delay } from '@fastgpt/global/common/system/utils';
|
||||
import { getNanoid } from '@fastgpt/global/common/string/tools';
|
||||
import { getImageBase64 } from '../image/utils';
|
||||
|
||||
export type readRawTextByLocalFileParams = {
|
||||
teamId: string;
|
||||
@@ -99,7 +100,7 @@ export const readRawContentByFileBuffer = async ({
|
||||
addLog.info(`Custom file parsing is complete, time: ${Date.now() - start}ms`);
|
||||
|
||||
const rawText = response.markdown;
|
||||
const { text, imageList } = matchMdImgTextAndUpload(rawText);
|
||||
const { text, imageList } = matchMdImg(rawText);
|
||||
|
||||
createPdfParseUsage({
|
||||
teamId,
|
||||
@@ -120,8 +121,8 @@ export const readRawContentByFileBuffer = async ({
|
||||
const parseTextImage = async (text: string) => {
|
||||
// Extract image links and convert to base64
|
||||
const imageList: { id: string; url: string }[] = [];
|
||||
const processedText = text.replace(/!\[.*?\]\((http[^)]+)\)/g, (match, url) => {
|
||||
const id = getNanoid();
|
||||
let processedText = text.replace(/!\[.*?\]\((http[^)]+)\)/g, (match, url) => {
|
||||
const id = `IMAGE_${getNanoid()}_IMAGE`;
|
||||
imageList.push({
|
||||
id,
|
||||
url
|
||||
@@ -129,22 +130,24 @@ export const readRawContentByFileBuffer = async ({
|
||||
return ``;
|
||||
});
|
||||
|
||||
// Get base64 from image url
|
||||
let resultImageList: ImageType[] = [];
|
||||
await Promise.all(
|
||||
imageList.map(async (item) => {
|
||||
await batchRun(
|
||||
imageList,
|
||||
async (item) => {
|
||||
try {
|
||||
const response = await axios.get(item.url, { responseType: 'arraybuffer' });
|
||||
const mime = response.headers['content-type'] || 'image/jpeg';
|
||||
const base64 = response.data.toString('base64');
|
||||
const { base64, mime } = await getImageBase64(item.url);
|
||||
resultImageList.push({
|
||||
uuid: item.id,
|
||||
mime,
|
||||
base64
|
||||
});
|
||||
} catch (error) {
|
||||
processedText = processedText.replace(item.id, item.url);
|
||||
addLog.warn(`Failed to get image from ${item.url}: ${getErrText(error)}`);
|
||||
}
|
||||
})
|
||||
},
|
||||
5
|
||||
);
|
||||
|
||||
return {
|
||||
@@ -297,6 +300,9 @@ export const readRawContentByFileBuffer = async ({
|
||||
return systemParse();
|
||||
};
|
||||
|
||||
const start = Date.now();
|
||||
addLog.debug(`Start parse file`, { extension });
|
||||
|
||||
let { rawText, formatText, imageList } = await (async () => {
|
||||
if (extension === 'pdf') {
|
||||
return await pdfParseFn();
|
||||
@@ -304,6 +310,8 @@ export const readRawContentByFileBuffer = async ({
|
||||
return await systemParse();
|
||||
})();
|
||||
|
||||
addLog.debug(`Parse file success, time: ${Date.now() - start}ms. Uploading file image.`);
|
||||
|
||||
// markdown data format
|
||||
if (imageList) {
|
||||
await batchRun(imageList, async (item) => {
|
||||
@@ -312,14 +320,14 @@ export const readRawContentByFileBuffer = async ({
|
||||
return await uploadMongoImg({
|
||||
base64Img: `data:${item.mime};base64,${item.base64}`,
|
||||
teamId,
|
||||
// expiredTime: addHours(new Date(), 1),
|
||||
metadata: {
|
||||
...metadata,
|
||||
mime: item.mime
|
||||
}
|
||||
});
|
||||
} catch (error) {
|
||||
return '';
|
||||
addLog.warn('Upload file image error', { error });
|
||||
return 'Upload load image error';
|
||||
}
|
||||
})();
|
||||
rawText = rawText.replace(item.uuid, src);
|
||||
@@ -338,5 +346,7 @@ export const readRawContentByFileBuffer = async ({
|
||||
}
|
||||
}
|
||||
|
||||
addLog.debug(`Upload file image success, time: ${Date.now() - start}ms`);
|
||||
|
||||
return { rawText, formatText, imageList };
|
||||
};
|
||||
|
||||
@@ -19,7 +19,7 @@ export async function connectMongo(): Promise<Mongoose> {
|
||||
// Remove existing listeners to prevent duplicates
|
||||
connectionMongo.connection.removeAllListeners('error');
|
||||
connectionMongo.connection.removeAllListeners('disconnected');
|
||||
connectionMongo.set('strictQuery', false);
|
||||
connectionMongo.set('strictQuery', 'throw');
|
||||
|
||||
connectionMongo.connection.on('error', async (error) => {
|
||||
console.log('mongo error', error);
|
||||
|
||||
3
packages/service/common/string/jieba/dict.json
Normal file
3
packages/service/common/string/jieba/dict.json
Normal file
File diff suppressed because one or more lines are too long
@@ -1,4 +1,13 @@
|
||||
import { cut } from '@node-rs/jieba';
|
||||
import { Jieba } from '@node-rs/jieba';
|
||||
|
||||
let jieba: Jieba | undefined;
|
||||
|
||||
(async () => {
|
||||
const dictData = await import('./dict.json');
|
||||
// @ts-ignore
|
||||
const dictBuffer = Buffer.from(dictData.dict?.replace(/\\n/g, '\n'), 'utf-8');
|
||||
jieba = Jieba.withDict(dictBuffer);
|
||||
})();
|
||||
|
||||
const stopWords = new Set([
|
||||
'--',
|
||||
@@ -1509,8 +1518,10 @@ const stopWords = new Set([
|
||||
]
|
||||
]);
|
||||
|
||||
export function jiebaSplit({ text }: { text: string }) {
|
||||
const tokens = cut(text, true);
|
||||
export async function jiebaSplit({ text }: { text: string }) {
|
||||
text = text.replace(/[#*`_~>[\](){}|]/g, '').replace(/\S*https?\S*/gi, '');
|
||||
|
||||
const tokens = (await jieba!.cutAsync(text, true)) as string[];
|
||||
|
||||
return (
|
||||
tokens
|
||||
@@ -30,6 +30,8 @@ export const isInternalAddress = (url: string): boolean => {
|
||||
return true;
|
||||
}
|
||||
|
||||
if (process.env.CHECK_INTERNAL_IP !== 'true') return false;
|
||||
|
||||
// For IP addresses, check if they are internal
|
||||
const ipv4Pattern = /^(\d{1,3}\.){3}\d{1,3}$/;
|
||||
if (!ipv4Pattern.test(hostname)) {
|
||||
|
||||
@@ -38,6 +38,27 @@ export class PgVectorCtrl {
|
||||
await PgClient.query(
|
||||
`CREATE INDEX CONCURRENTLY IF NOT EXISTS create_time_index ON ${DatasetVectorTableName} USING btree(createtime);`
|
||||
);
|
||||
// 10w rows
|
||||
// await PgClient.query(`
|
||||
// ALTER TABLE modeldata SET (
|
||||
// autovacuum_vacuum_scale_factor = 0.1,
|
||||
// autovacuum_analyze_scale_factor = 0.05,
|
||||
// autovacuum_vacuum_threshold = 50,
|
||||
// autovacuum_analyze_threshold = 50,
|
||||
// autovacuum_vacuum_cost_delay = 20,
|
||||
// autovacuum_vacuum_cost_limit = 200
|
||||
// );`);
|
||||
|
||||
// 100w rows
|
||||
// await PgClient.query(`
|
||||
// ALTER TABLE modeldata SET (
|
||||
// autovacuum_vacuum_scale_factor = 0.01,
|
||||
// autovacuum_analyze_scale_factor = 0.02,
|
||||
// autovacuum_vacuum_threshold = 1000,
|
||||
// autovacuum_analyze_threshold = 1000,
|
||||
// autovacuum_vacuum_cost_delay = 10,
|
||||
// autovacuum_vacuum_cost_limit = 2000
|
||||
// );`)
|
||||
|
||||
addLog.info('init pg successful');
|
||||
} catch (error) {
|
||||
|
||||
@@ -6,10 +6,12 @@ import { getSTTModel } from '../model';
|
||||
|
||||
export const aiTranscriptions = async ({
|
||||
model,
|
||||
fileStream
|
||||
fileStream,
|
||||
headers
|
||||
}: {
|
||||
model: string;
|
||||
fileStream: fs.ReadStream;
|
||||
headers?: Record<string, string>;
|
||||
}) => {
|
||||
const data = new FormData();
|
||||
data.append('model', model);
|
||||
@@ -30,7 +32,8 @@ export const aiTranscriptions = async ({
|
||||
Authorization: modelData.requestAuth
|
||||
? `Bearer ${modelData.requestAuth}`
|
||||
: aiAxiosConfig.authorization,
|
||||
...data.getHeaders()
|
||||
...data.getHeaders(),
|
||||
...headers
|
||||
},
|
||||
data: data
|
||||
});
|
||||
|
||||
@@ -76,6 +76,10 @@ export const createChatCompletion = async ({
|
||||
timeout: formatTimeout
|
||||
});
|
||||
|
||||
addLog.debug(`Start create chat completion`, {
|
||||
model: body.model
|
||||
});
|
||||
|
||||
const response = await ai.chat.completions.create(body, {
|
||||
...options,
|
||||
...(modelConstantsData.requestUrl ? { path: modelConstantsData.requestUrl } : {}),
|
||||
|
||||
@@ -76,7 +76,7 @@
|
||||
{
|
||||
"model": "qwen-max",
|
||||
"name": "Qwen-max",
|
||||
"maxContext": 8000,
|
||||
"maxContext": 32000,
|
||||
"maxResponse": 4000,
|
||||
"quoteMaxToken": 6000,
|
||||
"maxTemperature": 1,
|
||||
@@ -122,6 +122,56 @@
|
||||
"showTopP": true,
|
||||
"showStopSign": true
|
||||
},
|
||||
{
|
||||
"model": "qwq-plus",
|
||||
"name": "qwq-plus",
|
||||
"maxContext": 128000,
|
||||
"maxResponse": 8000,
|
||||
"quoteMaxToken": 100000,
|
||||
"maxTemperature": null,
|
||||
"vision": false,
|
||||
"reasoning": true,
|
||||
"toolChoice": true,
|
||||
"functionCall": false,
|
||||
"defaultSystemChatPrompt": "",
|
||||
"datasetProcess": false,
|
||||
"usedInClassify": false,
|
||||
"customCQPrompt": "",
|
||||
"usedInExtractFields": false,
|
||||
"usedInQueryExtension": false,
|
||||
"customExtractPrompt": "",
|
||||
"usedInToolCall": true,
|
||||
"defaultConfig": {},
|
||||
"fieldMap": {},
|
||||
"type": "llm",
|
||||
"showTopP": false,
|
||||
"showStopSign": false
|
||||
},
|
||||
{
|
||||
"model": "qwq-32b",
|
||||
"name": "qwq-32b",
|
||||
"maxContext": 128000,
|
||||
"maxResponse": 8000,
|
||||
"quoteMaxToken": 100000,
|
||||
"maxTemperature": null,
|
||||
"vision": false,
|
||||
"reasoning": true,
|
||||
"toolChoice": true,
|
||||
"functionCall": false,
|
||||
"defaultSystemChatPrompt": "",
|
||||
"datasetProcess": false,
|
||||
"usedInClassify": false,
|
||||
"customCQPrompt": "",
|
||||
"usedInExtractFields": false,
|
||||
"usedInQueryExtension": false,
|
||||
"customExtractPrompt": "",
|
||||
"usedInToolCall": true,
|
||||
"defaultConfig": {},
|
||||
"fieldMap": {},
|
||||
"type": "llm",
|
||||
"showTopP": false,
|
||||
"showStopSign": false
|
||||
},
|
||||
{
|
||||
"model": "qwen-coder-turbo",
|
||||
"name": "qwen-coder-turbo",
|
||||
|
||||
@@ -8,7 +8,7 @@ import {
|
||||
EmbeddingModelItemType,
|
||||
TTSModelType,
|
||||
STTModelType,
|
||||
ReRankModelItemType
|
||||
RerankModelItemType
|
||||
} from '@fastgpt/global/core/ai/model.d';
|
||||
import { debounce } from 'lodash';
|
||||
import {
|
||||
@@ -94,7 +94,7 @@ export const loadSystemModels = async (init = false) => {
|
||||
global.embeddingModelMap = new Map<string, EmbeddingModelItemType>();
|
||||
global.ttsModelMap = new Map<string, TTSModelType>();
|
||||
global.sttModelMap = new Map<string, STTModelType>();
|
||||
global.reRankModelMap = new Map<string, ReRankModelItemType>();
|
||||
global.reRankModelMap = new Map<string, RerankModelItemType>();
|
||||
// @ts-ignore
|
||||
global.systemDefaultModel = {};
|
||||
|
||||
|
||||
@@ -8,10 +8,11 @@ type GetVectorProps = {
|
||||
model: EmbeddingModelItemType;
|
||||
input: string;
|
||||
type?: `${EmbeddingTypeEnm}`;
|
||||
headers?: Record<string, string>;
|
||||
};
|
||||
|
||||
// text to vector
|
||||
export async function getVectorsByText({ model, input, type }: GetVectorProps) {
|
||||
export async function getVectorsByText({ model, input, type, headers }: GetVectorProps) {
|
||||
if (!input) {
|
||||
return Promise.reject({
|
||||
code: 500,
|
||||
@@ -35,13 +36,12 @@ export async function getVectorsByText({ model, input, type }: GetVectorProps) {
|
||||
model.requestUrl
|
||||
? {
|
||||
path: model.requestUrl,
|
||||
headers: model.requestAuth
|
||||
? {
|
||||
Authorization: `Bearer ${model.requestAuth}`
|
||||
}
|
||||
: undefined
|
||||
headers: {
|
||||
...(model.requestAuth ? { Authorization: `Bearer ${model.requestAuth}` } : {}),
|
||||
...headers
|
||||
}
|
||||
}
|
||||
: {}
|
||||
: { headers }
|
||||
)
|
||||
.then(async (res) => {
|
||||
if (!res.data) {
|
||||
|
||||
@@ -38,7 +38,7 @@ export function getSTTModel(model?: string) {
|
||||
}
|
||||
|
||||
export const getDefaultRerankModel = () => global?.systemDefaultModel.rerank!;
|
||||
export function getReRankModel(model?: string) {
|
||||
export function getRerankModel(model?: string) {
|
||||
if (!model) return getDefaultRerankModel();
|
||||
return global.reRankModelMap.get(model) || getDefaultRerankModel();
|
||||
}
|
||||
|
||||
@@ -2,7 +2,7 @@ import { addLog } from '../../../common/system/log';
|
||||
import { POST } from '../../../common/api/serverRequest';
|
||||
import { getDefaultRerankModel } from '../model';
|
||||
import { getAxiosConfig } from '../config';
|
||||
import { ReRankModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
import { RerankModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
|
||||
type PostReRankResponse = {
|
||||
id: string;
|
||||
@@ -16,11 +16,13 @@ type ReRankCallResult = { id: string; score?: number }[];
|
||||
export function reRankRecall({
|
||||
model = getDefaultRerankModel(),
|
||||
query,
|
||||
documents
|
||||
documents,
|
||||
headers
|
||||
}: {
|
||||
model?: ReRankModelItemType;
|
||||
model?: RerankModelItemType;
|
||||
query: string;
|
||||
documents: { id: string; text: string }[];
|
||||
headers?: Record<string, string>;
|
||||
}): Promise<ReRankCallResult> {
|
||||
if (!model) {
|
||||
return Promise.reject('no rerank model');
|
||||
@@ -41,7 +43,8 @@ export function reRankRecall({
|
||||
},
|
||||
{
|
||||
headers: {
|
||||
Authorization: model.requestAuth ? `Bearer ${model.requestAuth}` : authorization
|
||||
Authorization: model.requestAuth ? `Bearer ${model.requestAuth}` : authorization,
|
||||
...headers
|
||||
},
|
||||
timeout: 30000
|
||||
}
|
||||
|
||||
8
packages/service/core/ai/type.d.ts
vendored
8
packages/service/core/ai/type.d.ts
vendored
@@ -1,7 +1,7 @@
|
||||
import { ModelTypeEnum } from '@fastgpt/global/core/ai/model';
|
||||
import {
|
||||
STTModelType,
|
||||
ReRankModelItemType,
|
||||
RerankModelItemType,
|
||||
TTSModelType,
|
||||
EmbeddingModelItemType,
|
||||
LLMModelItemType
|
||||
@@ -18,7 +18,7 @@ export type SystemModelItemType =
|
||||
| EmbeddingModelItemType
|
||||
| TTSModelType
|
||||
| STTModelType
|
||||
| ReRankModelItemType;
|
||||
| RerankModelItemType;
|
||||
|
||||
export type SystemDefaultModelType = {
|
||||
[ModelTypeEnum.llm]?: LLMModelItemType;
|
||||
@@ -28,7 +28,7 @@ export type SystemDefaultModelType = {
|
||||
[ModelTypeEnum.embedding]?: EmbeddingModelItemType;
|
||||
[ModelTypeEnum.tts]?: TTSModelType;
|
||||
[ModelTypeEnum.stt]?: STTModelType;
|
||||
[ModelTypeEnum.rerank]?: ReRankModelItemType;
|
||||
[ModelTypeEnum.rerank]?: RerankModelItemType;
|
||||
};
|
||||
|
||||
declare global {
|
||||
@@ -38,7 +38,7 @@ declare global {
|
||||
var embeddingModelMap: Map<string, EmbeddingModelItemType>;
|
||||
var ttsModelMap: Map<string, TTSModelType>;
|
||||
var sttModelMap: Map<string, STTModelType>;
|
||||
var reRankModelMap: Map<string, ReRankModelItemType>;
|
||||
var reRankModelMap: Map<string, RerankModelItemType>;
|
||||
|
||||
var systemActiveModelList: SystemModelItemType[];
|
||||
var systemDefaultModel: SystemDefaultModelType;
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
import '@/pages/api/__mocks__/base';
|
||||
import { parseReasoningStreamContent } from '@fastgpt/service/core/ai/utils';
|
||||
import { parseReasoningStreamContent } from './utils';
|
||||
import { expect, test } from 'vitest';
|
||||
|
||||
test('Parse reasoning stream content test', async () => {
|
||||
const partList = [
|
||||
@@ -132,7 +132,7 @@ export const parseReasoningStreamContent = () => {
|
||||
let endTagBuffer = '';
|
||||
|
||||
/*
|
||||
parseReasoning - 只控制是否主动解析 <think></think>,如果接口已经解析了,仍然会返回 think 内容。
|
||||
parseThinkTag - 只控制是否主动解析 <think></think>,如果接口已经解析了,则不再解析。
|
||||
*/
|
||||
const parsePart = (
|
||||
part: {
|
||||
@@ -143,13 +143,13 @@ export const parseReasoningStreamContent = () => {
|
||||
};
|
||||
}[];
|
||||
},
|
||||
parseReasoning = false
|
||||
parseThinkTag = false
|
||||
): [string, string] => {
|
||||
const content = part.choices?.[0]?.delta?.content || '';
|
||||
|
||||
// @ts-ignore
|
||||
const reasoningContent = part.choices?.[0]?.delta?.reasoning_content || '';
|
||||
if (reasoningContent || !parseReasoning) {
|
||||
if (reasoningContent || !parseThinkTag) {
|
||||
isInThinkTag = false;
|
||||
return [reasoningContent, content];
|
||||
}
|
||||
|
||||
153
packages/service/core/app/utils.ts
Normal file
153
packages/service/core/app/utils.ts
Normal file
@@ -0,0 +1,153 @@
|
||||
import { MongoDataset } from '../dataset/schema';
|
||||
import { getEmbeddingModel } from '../ai/model';
|
||||
import { FlowNodeTypeEnum } from '@fastgpt/global/core/workflow/node/constant';
|
||||
import { NodeInputKeyEnum } from '@fastgpt/global/core/workflow/constants';
|
||||
import type { StoreNodeItemType } from '@fastgpt/global/core/workflow/type/node';
|
||||
|
||||
export async function listAppDatasetDataByTeamIdAndDatasetIds({
|
||||
teamId,
|
||||
datasetIdList
|
||||
}: {
|
||||
teamId?: string;
|
||||
datasetIdList: string[];
|
||||
}) {
|
||||
const myDatasets = await MongoDataset.find({
|
||||
_id: { $in: datasetIdList },
|
||||
...(teamId && { teamId })
|
||||
}).lean();
|
||||
|
||||
return myDatasets.map((item) => ({
|
||||
datasetId: String(item._id),
|
||||
avatar: item.avatar,
|
||||
name: item.name,
|
||||
vectorModel: getEmbeddingModel(item.vectorModel)
|
||||
}));
|
||||
}
|
||||
|
||||
export async function rewriteAppWorkflowToDetail({
|
||||
nodes,
|
||||
teamId,
|
||||
isRoot
|
||||
}: {
|
||||
nodes: StoreNodeItemType[];
|
||||
teamId: string;
|
||||
isRoot: boolean;
|
||||
}) {
|
||||
const datasetIdSet = new Set<string>();
|
||||
|
||||
// Get all dataset ids from nodes
|
||||
nodes.forEach((node) => {
|
||||
if (node.flowNodeType !== FlowNodeTypeEnum.datasetSearchNode) return;
|
||||
|
||||
const input = node.inputs.find((item) => item.key === NodeInputKeyEnum.datasetSelectList);
|
||||
if (!input) return;
|
||||
|
||||
const rawValue = input.value as undefined | { datasetId: string }[] | { datasetId: string };
|
||||
if (!rawValue) return;
|
||||
|
||||
const datasetIds = Array.isArray(rawValue)
|
||||
? rawValue.map((v) => v?.datasetId).filter((id) => !!id && typeof id === 'string')
|
||||
: rawValue?.datasetId
|
||||
? [String(rawValue.datasetId)]
|
||||
: [];
|
||||
|
||||
datasetIds.forEach((id) => datasetIdSet.add(id));
|
||||
});
|
||||
|
||||
if (datasetIdSet.size === 0) return;
|
||||
|
||||
// Load dataset list
|
||||
const datasetList = await listAppDatasetDataByTeamIdAndDatasetIds({
|
||||
teamId: isRoot ? undefined : teamId,
|
||||
datasetIdList: Array.from(datasetIdSet)
|
||||
});
|
||||
const datasetMap = new Map(datasetList.map((ds) => [String(ds.datasetId), ds]));
|
||||
|
||||
// Rewrite dataset ids, add dataset info to nodes
|
||||
if (datasetList.length > 0) {
|
||||
nodes.forEach((node) => {
|
||||
if (node.flowNodeType !== FlowNodeTypeEnum.datasetSearchNode) return;
|
||||
|
||||
node.inputs.forEach((item) => {
|
||||
if (item.key !== NodeInputKeyEnum.datasetSelectList) return;
|
||||
|
||||
const val = item.value as undefined | { datasetId: string }[] | { datasetId: string };
|
||||
|
||||
if (Array.isArray(val)) {
|
||||
item.value = val
|
||||
.map((v) => {
|
||||
const data = datasetMap.get(String(v.datasetId));
|
||||
if (!data)
|
||||
return {
|
||||
datasetId: v.datasetId,
|
||||
avatar: '',
|
||||
name: 'Dataset not found',
|
||||
vectorModel: ''
|
||||
};
|
||||
return {
|
||||
datasetId: data.datasetId,
|
||||
avatar: data.avatar,
|
||||
name: data.name,
|
||||
vectorModel: data.vectorModel
|
||||
};
|
||||
})
|
||||
.filter(Boolean);
|
||||
} else if (typeof val === 'object' && val !== null) {
|
||||
const data = datasetMap.get(String(val.datasetId));
|
||||
if (!data) {
|
||||
item.value = [
|
||||
{
|
||||
datasetId: val.datasetId,
|
||||
avatar: '',
|
||||
name: 'Dataset not found',
|
||||
vectorModel: ''
|
||||
}
|
||||
];
|
||||
} else {
|
||||
item.value = [
|
||||
{
|
||||
datasetId: data.datasetId,
|
||||
avatar: data.avatar,
|
||||
name: data.name,
|
||||
vectorModel: data.vectorModel
|
||||
}
|
||||
];
|
||||
}
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
return nodes;
|
||||
}
|
||||
|
||||
export async function rewriteAppWorkflowToSimple(formatNodes: StoreNodeItemType[]) {
|
||||
formatNodes.forEach((node) => {
|
||||
if (node.flowNodeType !== FlowNodeTypeEnum.datasetSearchNode) return;
|
||||
|
||||
node.inputs.forEach((input) => {
|
||||
if (input.key === NodeInputKeyEnum.datasetSelectList) {
|
||||
const val = input.value as undefined | { datasetId: string }[] | { datasetId: string };
|
||||
if (!val) {
|
||||
input.value = [];
|
||||
} else if (Array.isArray(val)) {
|
||||
// Not rewrite reference value
|
||||
if (val.length === 2 && val.every((item) => typeof item === 'string')) {
|
||||
return;
|
||||
}
|
||||
input.value = val
|
||||
.map((dataset: { datasetId: string }) => ({
|
||||
datasetId: dataset.datasetId
|
||||
}))
|
||||
.filter((item) => !!item.datasetId);
|
||||
} else if (typeof val === 'object' && val !== null) {
|
||||
input.value = [
|
||||
{
|
||||
datasetId: val.datasetId
|
||||
}
|
||||
];
|
||||
}
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
@@ -15,6 +15,7 @@ import { AppChatConfigType } from '@fastgpt/global/core/app/type';
|
||||
import { mergeChatResponseData } from '@fastgpt/global/core/chat/utils';
|
||||
import { pushChatLog } from './pushChatLog';
|
||||
import { FlowNodeTypeEnum } from '@fastgpt/global/core/workflow/node/constant';
|
||||
import { DispatchNodeResponseKeyEnum } from '@fastgpt/global/core/workflow/runtime/constants';
|
||||
|
||||
type Props = {
|
||||
chatId: string;
|
||||
@@ -73,9 +74,44 @@ export async function saveChat({
|
||||
(node) => node.flowNodeType === FlowNodeTypeEnum.pluginInput
|
||||
)?.inputs;
|
||||
|
||||
// Format save chat content: Remove quote q/a
|
||||
const processedContent = content.map((item) => {
|
||||
if (item.obj === ChatRoleEnum.AI) {
|
||||
const nodeResponse = item[DispatchNodeResponseKeyEnum.nodeResponse];
|
||||
|
||||
if (nodeResponse) {
|
||||
return {
|
||||
...item,
|
||||
[DispatchNodeResponseKeyEnum.nodeResponse]: nodeResponse.map((responseItem) => {
|
||||
if (
|
||||
responseItem.moduleType === FlowNodeTypeEnum.datasetSearchNode &&
|
||||
responseItem.quoteList
|
||||
) {
|
||||
return {
|
||||
...responseItem,
|
||||
quoteList: responseItem.quoteList.map((quote: any) => ({
|
||||
id: quote.id,
|
||||
chunkIndex: quote.chunkIndex,
|
||||
datasetId: quote.datasetId,
|
||||
collectionId: quote.collectionId,
|
||||
sourceId: quote.sourceId,
|
||||
sourceName: quote.sourceName,
|
||||
score: quote.score,
|
||||
tokens: quote.tokens
|
||||
}))
|
||||
};
|
||||
}
|
||||
return responseItem;
|
||||
})
|
||||
};
|
||||
}
|
||||
}
|
||||
return item;
|
||||
});
|
||||
|
||||
await mongoSessionRun(async (session) => {
|
||||
const [{ _id: chatItemIdHuman }, { _id: chatItemIdAi }] = await MongoChatItem.insertMany(
|
||||
content.map((item) => ({
|
||||
processedContent.map((item) => ({
|
||||
chatId,
|
||||
teamId,
|
||||
tmbId,
|
||||
|
||||
@@ -165,7 +165,7 @@ export const loadRequestMessages = async ({
|
||||
try {
|
||||
// If imgUrl is a local path, load image from local, and set url to base64
|
||||
if (imgUrl.startsWith('/') || process.env.MULTIPLE_DATA_TO_BASE64 === 'true') {
|
||||
const base64 = await getImageBase64(imgUrl);
|
||||
const { completeBase64: base64 } = await getImageBase64(imgUrl);
|
||||
|
||||
return {
|
||||
...item,
|
||||
|
||||
@@ -111,11 +111,13 @@ export const useApiDatasetRequest = ({ apiServer }: { apiServer: APIFileServer }
|
||||
const getFileContent = async ({
|
||||
teamId,
|
||||
tmbId,
|
||||
apiFileId
|
||||
apiFileId,
|
||||
customPdfParse
|
||||
}: {
|
||||
teamId: string;
|
||||
tmbId: string;
|
||||
apiFileId: string;
|
||||
customPdfParse?: boolean;
|
||||
}) => {
|
||||
const data = await request<APIFileContentResponse>(
|
||||
`/v1/file/content`,
|
||||
@@ -133,7 +135,8 @@ export const useApiDatasetRequest = ({ apiServer }: { apiServer: APIFileServer }
|
||||
teamId,
|
||||
tmbId,
|
||||
url: previewUrl,
|
||||
relatedId: apiFileId
|
||||
relatedId: apiFileId,
|
||||
customPdfParse
|
||||
});
|
||||
return rawText;
|
||||
}
|
||||
|
||||
@@ -41,7 +41,7 @@ try {
|
||||
}
|
||||
);
|
||||
DatasetDataTextSchema.index({ teamId: 1, datasetId: 1, collectionId: 1 });
|
||||
DatasetDataTextSchema.index({ dataId: 1 }, { unique: true });
|
||||
DatasetDataTextSchema.index({ dataId: 'hashed' });
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
}
|
||||
|
||||
@@ -40,6 +40,15 @@ const DatasetDataSchema = new Schema({
|
||||
type: String,
|
||||
default: ''
|
||||
},
|
||||
history: {
|
||||
type: [
|
||||
{
|
||||
q: String,
|
||||
a: String,
|
||||
updateTime: Date
|
||||
}
|
||||
]
|
||||
},
|
||||
indexes: {
|
||||
type: [
|
||||
{
|
||||
@@ -77,7 +86,8 @@ const DatasetDataSchema = new Schema({
|
||||
|
||||
// Abandon
|
||||
fullTextToken: String,
|
||||
initFullText: Boolean
|
||||
initFullText: Boolean,
|
||||
initJieba: Boolean
|
||||
});
|
||||
|
||||
try {
|
||||
@@ -89,15 +99,14 @@ try {
|
||||
chunkIndex: 1,
|
||||
updateTime: -1
|
||||
});
|
||||
// FullText tmp full text index
|
||||
// DatasetDataSchema.index({ teamId: 1, datasetId: 1, fullTextToken: 'text' });
|
||||
// Recall vectors after data matching
|
||||
DatasetDataSchema.index({ teamId: 1, datasetId: 1, collectionId: 1, 'indexes.dataId': 1 });
|
||||
DatasetDataSchema.index({ updateTime: 1 });
|
||||
// rebuild data
|
||||
DatasetDataSchema.index({ rebuilding: 1, teamId: 1, datasetId: 1 });
|
||||
|
||||
DatasetDataSchema.index({ initFullText: 1 });
|
||||
// 为查询 initJieba 字段不存在的数据添加索引
|
||||
DatasetDataSchema.index({ initJieba: 1, updateTime: 1 });
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
}
|
||||
|
||||
@@ -127,7 +127,8 @@ export const readApiServerFileContent = async ({
|
||||
yuqueServer,
|
||||
apiFileId,
|
||||
teamId,
|
||||
tmbId
|
||||
tmbId,
|
||||
customPdfParse
|
||||
}: {
|
||||
apiServer?: APIFileServer;
|
||||
feishuServer?: FeishuServer;
|
||||
@@ -135,9 +136,15 @@ export const readApiServerFileContent = async ({
|
||||
apiFileId: string;
|
||||
teamId: string;
|
||||
tmbId: string;
|
||||
customPdfParse?: boolean;
|
||||
}) => {
|
||||
if (apiServer) {
|
||||
return useApiDatasetRequest({ apiServer }).getFileContent({ teamId, tmbId, apiFileId });
|
||||
return useApiDatasetRequest({ apiServer }).getFileContent({
|
||||
teamId,
|
||||
tmbId,
|
||||
apiFileId,
|
||||
customPdfParse
|
||||
});
|
||||
}
|
||||
|
||||
if (feishuServer || yuqueServer) {
|
||||
|
||||
@@ -16,7 +16,7 @@ import { reRankRecall } from '../../../core/ai/rerank';
|
||||
import { countPromptTokens } from '../../../common/string/tiktoken/index';
|
||||
import { datasetSearchResultConcat } from '@fastgpt/global/core/dataset/search/utils';
|
||||
import { hashStr } from '@fastgpt/global/common/string/tools';
|
||||
import { jiebaSplit } from '../../../common/string/jieba';
|
||||
import { jiebaSplit } from '../../../common/string/jieba/index';
|
||||
import { getCollectionSourceData } from '@fastgpt/global/core/dataset/collection/utils';
|
||||
import { Types } from '../../../common/mongo';
|
||||
import json5 from 'json5';
|
||||
@@ -27,6 +27,7 @@ import { ChatItemType } from '@fastgpt/global/core/chat/type';
|
||||
import { POST } from '../../../common/api/plusRequest';
|
||||
import { NodeInputKeyEnum } from '@fastgpt/global/core/workflow/constants';
|
||||
import { datasetSearchQueryExtension } from './utils';
|
||||
import type { RerankModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
|
||||
export type SearchDatasetDataProps = {
|
||||
histories: ChatItemType[];
|
||||
@@ -39,7 +40,11 @@ export type SearchDatasetDataProps = {
|
||||
[NodeInputKeyEnum.datasetSimilarity]?: number; // min distance
|
||||
[NodeInputKeyEnum.datasetMaxTokens]: number; // max Token limit
|
||||
[NodeInputKeyEnum.datasetSearchMode]?: `${DatasetSearchModeEnum}`;
|
||||
[NodeInputKeyEnum.datasetSearchEmbeddingWeight]?: number;
|
||||
|
||||
[NodeInputKeyEnum.datasetSearchUsingReRank]?: boolean;
|
||||
[NodeInputKeyEnum.datasetSearchRerankModel]?: RerankModelItemType;
|
||||
[NodeInputKeyEnum.datasetSearchRerankWeight]?: number;
|
||||
|
||||
/*
|
||||
{
|
||||
@@ -75,13 +80,16 @@ export type SearchDatasetDataResponse = {
|
||||
};
|
||||
|
||||
export const datasetDataReRank = async ({
|
||||
rerankModel,
|
||||
data,
|
||||
query
|
||||
}: {
|
||||
rerankModel?: RerankModelItemType;
|
||||
data: SearchDataResponseItemType[];
|
||||
query: string;
|
||||
}): Promise<SearchDataResponseItemType[]> => {
|
||||
const results = await reRankRecall({
|
||||
model: rerankModel,
|
||||
query,
|
||||
documents: data.map((item) => ({
|
||||
id: item.id,
|
||||
@@ -154,7 +162,10 @@ export async function searchDatasetData(
|
||||
similarity = 0,
|
||||
limit: maxTokens,
|
||||
searchMode = DatasetSearchModeEnum.embedding,
|
||||
embeddingWeight = 0.5,
|
||||
usingReRank = false,
|
||||
rerankModel,
|
||||
rerankWeight = 0.5,
|
||||
datasetIds = [],
|
||||
collectionFilterMatch
|
||||
} = props;
|
||||
@@ -526,7 +537,7 @@ export async function searchDatasetData(
|
||||
$match: {
|
||||
teamId: new Types.ObjectId(teamId),
|
||||
datasetId: new Types.ObjectId(id),
|
||||
$text: { $search: jiebaSplit({ text: query }) },
|
||||
$text: { $search: await jiebaSplit({ text: query }) },
|
||||
...(filterCollectionIdList
|
||||
? {
|
||||
collectionId: {
|
||||
@@ -711,6 +722,7 @@ export async function searchDatasetData(
|
||||
});
|
||||
try {
|
||||
return await datasetDataReRank({
|
||||
rerankModel,
|
||||
query: reRankQuery,
|
||||
data: filterSameDataResults
|
||||
});
|
||||
@@ -721,11 +733,26 @@ export async function searchDatasetData(
|
||||
})();
|
||||
|
||||
// embedding recall and fullText recall rrf concat
|
||||
const rrfConcatResults = datasetSearchResultConcat([
|
||||
{ k: 60, list: embeddingRecallResults },
|
||||
{ k: 60, list: fullTextRecallResults },
|
||||
{ k: 58, list: reRankResults }
|
||||
const baseK = 120;
|
||||
const embK = Math.round(baseK * (1 - embeddingWeight)); // 搜索结果的 k 值
|
||||
const fullTextK = Math.round(baseK * embeddingWeight); // rerank 结果的 k 值
|
||||
|
||||
const rrfSearchResult = datasetSearchResultConcat([
|
||||
{ k: embK, list: embeddingRecallResults },
|
||||
{ k: fullTextK, list: fullTextRecallResults }
|
||||
]);
|
||||
const rrfConcatResults = (() => {
|
||||
if (reRankResults.length === 0) return rrfSearchResult;
|
||||
if (rerankWeight === 1) return reRankResults;
|
||||
|
||||
const searchK = Math.round(baseK * rerankWeight); // 搜索结果的 k 值
|
||||
const rerankK = Math.round(baseK * (1 - rerankWeight)); // rerank 结果的 k 值
|
||||
|
||||
return datasetSearchResultConcat([
|
||||
{ k: searchK, list: rrfSearchResult },
|
||||
{ k: rerankK, list: reRankResults }
|
||||
]);
|
||||
})();
|
||||
|
||||
// remove same q and a data
|
||||
set = new Set<string>();
|
||||
@@ -787,6 +814,7 @@ export const defaultSearchDatasetData = async ({
|
||||
...props
|
||||
}: DefaultSearchDatasetDataProps): Promise<SearchDatasetDataResponse> => {
|
||||
const query = props.queries[0];
|
||||
const histories = props.histories;
|
||||
|
||||
const extensionModel = datasetSearchUsingExtensionQuery
|
||||
? getLLMModel(datasetSearchExtensionModel)
|
||||
@@ -796,7 +824,8 @@ export const defaultSearchDatasetData = async ({
|
||||
await datasetSearchQueryExtension({
|
||||
query,
|
||||
extensionModel,
|
||||
extensionBg: datasetSearchExtensionBg
|
||||
extensionBg: datasetSearchExtensionBg,
|
||||
histories
|
||||
});
|
||||
|
||||
const result = await searchDatasetData({
|
||||
|
||||
@@ -9,7 +9,11 @@ import {
|
||||
import { ChatItemValueTypeEnum, ChatRoleEnum } from '@fastgpt/global/core/chat/constants';
|
||||
import { createChatCompletion } from '../../../ai/config';
|
||||
import type { ContextExtractAgentItemType } from '@fastgpt/global/core/workflow/template/system/contextExtract/type';
|
||||
import { NodeInputKeyEnum, NodeOutputKeyEnum } from '@fastgpt/global/core/workflow/constants';
|
||||
import {
|
||||
NodeInputKeyEnum,
|
||||
NodeOutputKeyEnum,
|
||||
toolValueTypeList
|
||||
} from '@fastgpt/global/core/workflow/constants';
|
||||
import { DispatchNodeResponseKeyEnum } from '@fastgpt/global/core/workflow/runtime/constants';
|
||||
import type { ModuleDispatchProps } from '@fastgpt/global/core/workflow/runtime/type';
|
||||
import { Prompt_ExtractJson } from '@fastgpt/global/core/ai/prompt/agent';
|
||||
@@ -192,10 +196,13 @@ ${description ? `- ${description}` : ''}
|
||||
}
|
||||
> = {};
|
||||
extractKeys.forEach((item) => {
|
||||
const jsonSchema = (
|
||||
toolValueTypeList.find((type) => type.value === item.valueType) || toolValueTypeList[0]
|
||||
)?.jsonSchema;
|
||||
properties[item.key] = {
|
||||
type: item.valueType || 'string',
|
||||
...jsonSchema,
|
||||
description: item.desc,
|
||||
...(item.enum ? { enum: item.enum.split('\n') } : {})
|
||||
...(item.enum ? { enum: item.enum.split('\n').filter(Boolean) } : {})
|
||||
};
|
||||
});
|
||||
// function body
|
||||
|
||||
@@ -1,11 +1,6 @@
|
||||
import { createChatCompletion } from '../../../../ai/config';
|
||||
import { filterGPTMessageByMaxContext, loadRequestMessages } from '../../../../chat/utils';
|
||||
import {
|
||||
ChatCompletion,
|
||||
StreamChatType,
|
||||
ChatCompletionMessageParam,
|
||||
ChatCompletionAssistantMessageParam
|
||||
} from '@fastgpt/global/core/ai/type';
|
||||
import { StreamChatType, ChatCompletionMessageParam } from '@fastgpt/global/core/ai/type';
|
||||
import { NextApiResponse } from 'next';
|
||||
import { responseWriteController } from '../../../../../common/response';
|
||||
import { SseResponseEventEnum } from '@fastgpt/global/core/workflow/runtime/constants';
|
||||
|
||||
@@ -208,6 +208,7 @@ export const dispatchChatCompletion = async (props: ChatProps): Promise<ChatResp
|
||||
res,
|
||||
stream: response,
|
||||
aiChatReasoning,
|
||||
parseThinkTag: modelConstantsData.reasoning,
|
||||
isResponseAnswerText,
|
||||
workflowStreamResponse
|
||||
});
|
||||
@@ -264,7 +265,7 @@ export const dispatchChatCompletion = async (props: ChatProps): Promise<ChatResp
|
||||
}
|
||||
})();
|
||||
|
||||
if (!answerText) {
|
||||
if (!answerText && !reasoningText) {
|
||||
return Promise.reject(getEmptyResponseTip());
|
||||
}
|
||||
|
||||
@@ -513,12 +514,14 @@ async function streamResponse({
|
||||
stream,
|
||||
workflowStreamResponse,
|
||||
aiChatReasoning,
|
||||
parseThinkTag,
|
||||
isResponseAnswerText
|
||||
}: {
|
||||
res: NextApiResponse;
|
||||
stream: StreamChatType;
|
||||
workflowStreamResponse?: WorkflowResponseType;
|
||||
aiChatReasoning?: boolean;
|
||||
parseThinkTag?: boolean;
|
||||
isResponseAnswerText?: boolean;
|
||||
}) {
|
||||
const write = responseWriteController({
|
||||
@@ -535,7 +538,7 @@ async function streamResponse({
|
||||
break;
|
||||
}
|
||||
|
||||
const [reasoningContent, content] = parsePart(part, aiChatReasoning);
|
||||
const [reasoningContent, content] = parsePart(part, parseThinkTag);
|
||||
answer += content;
|
||||
reasoning += reasoningContent;
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@ import { formatModelChars2Points } from '../../../../support/wallet/usage/utils'
|
||||
import type { SelectedDatasetType } from '@fastgpt/global/core/workflow/api.d';
|
||||
import type { SearchDataResponseItemType } from '@fastgpt/global/core/dataset/type';
|
||||
import type { ModuleDispatchProps } from '@fastgpt/global/core/workflow/runtime/type';
|
||||
import { getEmbeddingModel } from '../../../ai/model';
|
||||
import { getEmbeddingModel, getRerankModel } from '../../../ai/model';
|
||||
import { deepRagSearch, defaultSearchDatasetData } from '../../../dataset/search/controller';
|
||||
import { NodeInputKeyEnum, NodeOutputKeyEnum } from '@fastgpt/global/core/workflow/constants';
|
||||
import { DispatchNodeResponseKeyEnum } from '@fastgpt/global/core/workflow/runtime/constants';
|
||||
@@ -22,9 +22,14 @@ type DatasetSearchProps = ModuleDispatchProps<{
|
||||
[NodeInputKeyEnum.datasetSelectList]: SelectedDatasetType;
|
||||
[NodeInputKeyEnum.datasetSimilarity]: number;
|
||||
[NodeInputKeyEnum.datasetMaxTokens]: number;
|
||||
[NodeInputKeyEnum.datasetSearchMode]: `${DatasetSearchModeEnum}`;
|
||||
[NodeInputKeyEnum.userChatInput]?: string;
|
||||
[NodeInputKeyEnum.datasetSearchMode]: `${DatasetSearchModeEnum}`;
|
||||
[NodeInputKeyEnum.datasetSearchEmbeddingWeight]?: number;
|
||||
|
||||
[NodeInputKeyEnum.datasetSearchUsingReRank]: boolean;
|
||||
[NodeInputKeyEnum.datasetSearchRerankModel]?: string;
|
||||
[NodeInputKeyEnum.datasetSearchRerankWeight]?: number;
|
||||
|
||||
[NodeInputKeyEnum.collectionFilterMatch]: string;
|
||||
[NodeInputKeyEnum.authTmbId]?: boolean;
|
||||
|
||||
@@ -53,11 +58,14 @@ export async function dispatchDatasetSearch(
|
||||
datasets = [],
|
||||
similarity,
|
||||
limit = 1500,
|
||||
usingReRank,
|
||||
searchMode,
|
||||
userChatInput = '',
|
||||
authTmbId = false,
|
||||
collectionFilterMatch,
|
||||
searchMode,
|
||||
embeddingWeight,
|
||||
usingReRank,
|
||||
rerankModel,
|
||||
rerankWeight,
|
||||
|
||||
datasetSearchUsingExtensionQuery,
|
||||
datasetSearchExtensionModel,
|
||||
@@ -122,7 +130,10 @@ export async function dispatchDatasetSearch(
|
||||
limit,
|
||||
datasetIds,
|
||||
searchMode,
|
||||
embeddingWeight,
|
||||
usingReRank: usingReRank && (await checkTeamReRankPermission(teamId)),
|
||||
rerankModel: getRerankModel(rerankModel),
|
||||
rerankWeight,
|
||||
collectionFilterMatch
|
||||
};
|
||||
const {
|
||||
@@ -219,6 +230,9 @@ export async function dispatchDatasetSearch(
|
||||
similarity: usingSimilarityFilter ? similarity : undefined,
|
||||
limit,
|
||||
searchMode,
|
||||
embeddingWeight: searchMode === DatasetSearchModeEnum.mixedRecall ? embeddingWeight : undefined,
|
||||
rerankModel: usingReRank ? getRerankModel(rerankModel)?.name : undefined,
|
||||
rerankWeight: usingReRank ? rerankWeight : undefined,
|
||||
searchUsingReRank: searchUsingReRank,
|
||||
quoteList: searchRes,
|
||||
queryExtensionResult,
|
||||
|
||||
@@ -21,7 +21,7 @@ import {
|
||||
FlowNodeInputTypeEnum,
|
||||
FlowNodeTypeEnum
|
||||
} from '@fastgpt/global/core/workflow/node/constant';
|
||||
import { getNanoid, replaceVariable } from '@fastgpt/global/common/string/tools';
|
||||
import { getNanoid } from '@fastgpt/global/common/string/tools';
|
||||
import { getSystemTime } from '@fastgpt/global/common/time/timezone';
|
||||
|
||||
import { dispatchWorkflowStart } from './init/workflowStart';
|
||||
@@ -426,6 +426,14 @@ export async function dispatchWorkFlow(data: Props): Promise<DispatchFlowRespons
|
||||
})();
|
||||
|
||||
if (!nodeRunResult) return [];
|
||||
if (res?.closed) {
|
||||
addLog.warn('Request is closed', {
|
||||
appId: props.runningAppInfo.id,
|
||||
nodeId: node.nodeId,
|
||||
nodeName: node.name
|
||||
});
|
||||
return [];
|
||||
}
|
||||
|
||||
/*
|
||||
特殊情况:
|
||||
|
||||
@@ -120,27 +120,145 @@ export const dispatchHttp468Request = async (props: HttpRequestProps): Promise<H
|
||||
2. Replace newline strings
|
||||
*/
|
||||
const replaceJsonBodyString = (text: string) => {
|
||||
const valToStr = (val: any) => {
|
||||
// Check if the variable is in quotes
|
||||
const isVariableInQuotes = (text: string, variable: string) => {
|
||||
const index = text.indexOf(variable);
|
||||
if (index === -1) return false;
|
||||
|
||||
// 计算变量前面的引号数量
|
||||
const textBeforeVar = text.substring(0, index);
|
||||
const matches = textBeforeVar.match(/"/g) || [];
|
||||
|
||||
// 如果引号数量为奇数,则变量在引号内
|
||||
return matches.length % 2 === 1;
|
||||
};
|
||||
const valToStr = (val: any, isQuoted = false) => {
|
||||
if (val === undefined) return 'null';
|
||||
if (val === null) return 'null';
|
||||
|
||||
if (typeof val === 'object') return JSON.stringify(val);
|
||||
|
||||
if (typeof val === 'string') {
|
||||
if (isQuoted) {
|
||||
// Replace newlines with escaped newlines
|
||||
return val.replace(/\n/g, '\\n').replace(/(?<!\\)"/g, '\\"');
|
||||
}
|
||||
try {
|
||||
const parsed = JSON.parse(val);
|
||||
if (typeof parsed === 'object') {
|
||||
return JSON.stringify(parsed);
|
||||
}
|
||||
JSON.parse(val);
|
||||
return val;
|
||||
} catch (error) {
|
||||
const str = JSON.stringify(val);
|
||||
|
||||
return str.startsWith('"') && str.endsWith('"') ? str.slice(1, -1) : str;
|
||||
}
|
||||
}
|
||||
|
||||
return String(val);
|
||||
};
|
||||
// Test cases for variable replacement in JSON body
|
||||
// const bodyTest = () => {
|
||||
// const testData = [
|
||||
// // 基本字符串替换
|
||||
// {
|
||||
// body: `{"name":"{{name}}","age":"18"}`,
|
||||
// variables: [{ key: '{{name}}', value: '测试' }],
|
||||
// result: `{"name":"测试","age":"18"}`
|
||||
// },
|
||||
// // 特殊字符处理
|
||||
// {
|
||||
// body: `{"text":"{{text}}"}`,
|
||||
// variables: [{ key: '{{text}}', value: '包含"引号"和\\反斜杠' }],
|
||||
// result: `{"text":"包含\\"引号\\"和\\反斜杠"}`
|
||||
// },
|
||||
// // 数字类型处理
|
||||
// {
|
||||
// body: `{"count":{{count}},"price":{{price}}}`,
|
||||
// variables: [
|
||||
// { key: '{{count}}', value: '42' },
|
||||
// { key: '{{price}}', value: '99.99' }
|
||||
// ],
|
||||
// result: `{"count":42,"price":99.99}`
|
||||
// },
|
||||
// // 布尔值处理
|
||||
// {
|
||||
// body: `{"isActive":{{isActive}},"hasData":{{hasData}}}`,
|
||||
// variables: [
|
||||
// { key: '{{isActive}}', value: 'true' },
|
||||
// { key: '{{hasData}}', value: 'false' }
|
||||
// ],
|
||||
// result: `{"isActive":true,"hasData":false}`
|
||||
// },
|
||||
// // 对象类型处理
|
||||
// {
|
||||
// body: `{"user":{{user}},"user2":"{{user2}}"}`,
|
||||
// variables: [
|
||||
// { key: '{{user}}', value: `{"id":1,"name":"张三"}` },
|
||||
// { key: '{{user2}}', value: `{"id":1,"name":"张三"}` }
|
||||
// ],
|
||||
// result: `{"user":{"id":1,"name":"张三"},"user2":"{\\"id\\":1,\\"name\\":\\"张三\\"}"}`
|
||||
// },
|
||||
// // 数组类型处理
|
||||
// {
|
||||
// body: `{"items":{{items}}}`,
|
||||
// variables: [{ key: '{{items}}', value: '[1, 2, 3]' }],
|
||||
// result: `{"items":[1,2,3]}`
|
||||
// },
|
||||
// // null 和 undefined 处理
|
||||
// {
|
||||
// body: `{"nullValue":{{nullValue}},"undefinedValue":{{undefinedValue}}}`,
|
||||
// variables: [
|
||||
// { key: '{{nullValue}}', value: 'null' },
|
||||
// { key: '{{undefinedValue}}', value: 'undefined' }
|
||||
// ],
|
||||
// result: `{"nullValue":null,"undefinedValue":null}`
|
||||
// },
|
||||
// // 嵌套JSON结构
|
||||
// {
|
||||
// body: `{"data":{"nested":{"value":"{{nestedValue}}"}}}`,
|
||||
// variables: [{ key: '{{nestedValue}}', value: '嵌套值' }],
|
||||
// result: `{"data":{"nested":{"value":"嵌套值"}}}`
|
||||
// },
|
||||
// // 多变量替换
|
||||
// {
|
||||
// body: `{"first":"{{first}}","second":"{{second}}","third":{{third}}}`,
|
||||
// variables: [
|
||||
// { key: '{{first}}', value: '第一' },
|
||||
// { key: '{{second}}', value: '第二' },
|
||||
// { key: '{{third}}', value: '3' }
|
||||
// ],
|
||||
// result: `{"first":"第一","second":"第二","third":3}`
|
||||
// },
|
||||
// // JSON字符串作为变量值
|
||||
// {
|
||||
// body: `{"config":{{config}}}`,
|
||||
// variables: [{ key: '{{config}}', value: '{"setting":"enabled","mode":"advanced"}' }],
|
||||
// result: `{"config":{"setting":"enabled","mode":"advanced"}}`
|
||||
// }
|
||||
// ];
|
||||
|
||||
// for (let i = 0; i < testData.length; i++) {
|
||||
// const item = testData[i];
|
||||
// let bodyStr = item.body;
|
||||
// for (const variable of item.variables) {
|
||||
// const isQuote = isVariableInQuotes(bodyStr, variable.key);
|
||||
// bodyStr = bodyStr.replace(variable.key, valToStr(variable.value, isQuote));
|
||||
// }
|
||||
// bodyStr = bodyStr.replace(/(".*?")\s*:\s*undefined\b/g, '$1:null');
|
||||
|
||||
// console.log(bodyStr === item.result, i);
|
||||
// if (bodyStr !== item.result) {
|
||||
// console.log(bodyStr);
|
||||
// console.log(item.result);
|
||||
// } else {
|
||||
// try {
|
||||
// JSON.parse(item.result);
|
||||
// } catch (error) {
|
||||
// console.log('反序列化异常', i, item.result);
|
||||
// }
|
||||
// }
|
||||
// }
|
||||
// };
|
||||
// bodyTest();
|
||||
|
||||
// 1. Replace {{key.key}} variables
|
||||
const regex1 = /\{\{\$([^.]+)\.([^$]+)\$\}\}/g;
|
||||
@@ -148,6 +266,10 @@ export const dispatchHttp468Request = async (props: HttpRequestProps): Promise<H
|
||||
matches1.forEach((match) => {
|
||||
const nodeId = match[1];
|
||||
const id = match[2];
|
||||
const fullMatch = match[0];
|
||||
|
||||
// 检查变量是否在引号内
|
||||
const isInQuotes = isVariableInQuotes(text, fullMatch);
|
||||
|
||||
const variableVal = (() => {
|
||||
if (nodeId === VARIABLE_NODE_ID) {
|
||||
@@ -165,9 +287,9 @@ export const dispatchHttp468Request = async (props: HttpRequestProps): Promise<H
|
||||
return getReferenceVariableValue({ value: input.value, nodes: runtimeNodes, variables });
|
||||
})();
|
||||
|
||||
const formatVal = valToStr(variableVal);
|
||||
const formatVal = valToStr(variableVal, isInQuotes);
|
||||
|
||||
const regex = new RegExp(`\\{\\{\\$(${nodeId}\\.${id})\\$\\}\\}`, 'g');
|
||||
const regex = new RegExp(`\\{\\{\\$(${nodeId}\\.${id})\\$\\}\\}`, '');
|
||||
text = text.replace(regex, () => formatVal);
|
||||
});
|
||||
|
||||
@@ -176,10 +298,16 @@ export const dispatchHttp468Request = async (props: HttpRequestProps): Promise<H
|
||||
const matches2 = text.match(regex2) || [];
|
||||
const uniqueKeys2 = [...new Set(matches2.map((match) => match.slice(2, -2)))];
|
||||
for (const key of uniqueKeys2) {
|
||||
text = text.replace(new RegExp(`{{(${key})}}`, 'g'), () => valToStr(allVariables[key]));
|
||||
const fullMatch = `{{${key}}}`;
|
||||
// 检查变量是否在引号内
|
||||
const isInQuotes = isVariableInQuotes(text, fullMatch);
|
||||
|
||||
text = text.replace(new RegExp(`{{(${key})}}`, ''), () =>
|
||||
valToStr(allVariables[key], isInQuotes)
|
||||
);
|
||||
}
|
||||
|
||||
return text.replace(/(".*?")\s*:\s*undefined\b/g, '$1: null');
|
||||
return text.replace(/(".*?")\s*:\s*undefined\b/g, '$1:null');
|
||||
};
|
||||
|
||||
httpReqUrl = replaceStringVariables(httpReqUrl);
|
||||
|
||||
@@ -3,13 +3,13 @@
|
||||
"version": "1.0.0",
|
||||
"dependencies": {
|
||||
"@fastgpt/global": "workspace:*",
|
||||
"@node-rs/jieba": "1.10.0",
|
||||
"@node-rs/jieba": "2.0.1",
|
||||
"@xmldom/xmldom": "^0.8.10",
|
||||
"@zilliz/milvus2-sdk-node": "2.4.2",
|
||||
"axios": "^1.5.1",
|
||||
"axios": "^1.8.2",
|
||||
"chalk": "^5.3.0",
|
||||
"cheerio": "1.0.0-rc.12",
|
||||
"cookie": "^0.5.0",
|
||||
"cookie": "^0.7.1",
|
||||
"date-fns": "2.30.0",
|
||||
"dayjs": "^1.11.7",
|
||||
"decompress": "^4.2.1",
|
||||
@@ -20,13 +20,13 @@
|
||||
"iconv-lite": "^0.6.3",
|
||||
"joplin-turndown-plugin-gfm": "^1.0.12",
|
||||
"json5": "^2.2.3",
|
||||
"jsonpath-plus": "^10.1.0",
|
||||
"jsonpath-plus": "^10.3.0",
|
||||
"jsonwebtoken": "^9.0.2",
|
||||
"lodash": "^4.17.21",
|
||||
"mammoth": "^1.6.0",
|
||||
"mongoose": "^8.10.1",
|
||||
"multer": "1.4.5-lts.1",
|
||||
"next": "14.2.5",
|
||||
"next": "14.2.24",
|
||||
"nextjs-cors": "^2.2.0",
|
||||
"node-cron": "^3.0.3",
|
||||
"node-xlsx": "^0.24.0",
|
||||
|
||||
@@ -51,6 +51,9 @@ const OutLinkSchema = new Schema({
|
||||
type: Boolean,
|
||||
default: true
|
||||
},
|
||||
// showFullText: {
|
||||
// type: Boolean
|
||||
// },
|
||||
showRawSource: {
|
||||
type: Boolean
|
||||
},
|
||||
|
||||
@@ -43,7 +43,6 @@ async function getTeamMember(match: Record<string, any>): Promise<TeamTmbItemTyp
|
||||
teamDomain: tmb.team?.teamDomain,
|
||||
role: tmb.role,
|
||||
status: tmb.status,
|
||||
defaultTeam: tmb.defaultTeam,
|
||||
permission: new TeamPermission({
|
||||
per: Per ?? TeamDefaultPermissionVal,
|
||||
isOwner: tmb.role === TeamMemberRoleEnum.owner
|
||||
@@ -71,8 +70,7 @@ export async function getUserDefaultTeam({ userId }: { userId: string }) {
|
||||
return Promise.reject('tmbId or userId is required');
|
||||
}
|
||||
return getTeamMember({
|
||||
userId: new Types.ObjectId(userId),
|
||||
defaultTeam: true
|
||||
userId: new Types.ObjectId(userId)
|
||||
});
|
||||
}
|
||||
|
||||
@@ -89,8 +87,7 @@ export async function createDefaultTeam({
|
||||
}) {
|
||||
// auth default team
|
||||
const tmb = await MongoTeamMember.findOne({
|
||||
userId: new Types.ObjectId(userId),
|
||||
defaultTeam: true
|
||||
userId: new Types.ObjectId(userId)
|
||||
});
|
||||
|
||||
if (!tmb) {
|
||||
@@ -115,8 +112,7 @@ export async function createDefaultTeam({
|
||||
name: 'Owner',
|
||||
role: TeamMemberRoleEnum.owner,
|
||||
status: TeamMemberStatusEnum.active,
|
||||
createTime: new Date(),
|
||||
defaultTeam: true
|
||||
createTime: new Date()
|
||||
}
|
||||
],
|
||||
{ session }
|
||||
|
||||
@@ -0,0 +1 @@
|
||||
export const MaxInvitationLinksAmount = 10;
|
||||
49
packages/service/support/user/team/invitationLink/schema.ts
Normal file
49
packages/service/support/user/team/invitationLink/schema.ts
Normal file
@@ -0,0 +1,49 @@
|
||||
import {
|
||||
TeamCollectionName,
|
||||
TeamMemberCollectionName
|
||||
} from '@fastgpt/global/support/user/team/constant';
|
||||
import { connectionMongo, getMongoModel } from '../../../../common/mongo';
|
||||
import { InvitationSchemaType } from './type';
|
||||
import addDays from 'date-fns/esm/fp/addDays/index.js';
|
||||
const { Schema } = connectionMongo;
|
||||
|
||||
export const InvitationCollectionName = 'team_invitation_links';
|
||||
|
||||
const InvitationSchema = new Schema({
|
||||
teamId: {
|
||||
type: Schema.Types.ObjectId,
|
||||
ref: TeamCollectionName,
|
||||
required: true
|
||||
},
|
||||
usedTimesLimit: {
|
||||
type: Number,
|
||||
default: 1,
|
||||
enum: [1, -1]
|
||||
},
|
||||
forbidden: Boolean,
|
||||
expires: Date,
|
||||
description: String,
|
||||
members: {
|
||||
type: [String],
|
||||
default: []
|
||||
}
|
||||
});
|
||||
|
||||
InvitationSchema.virtual('team', {
|
||||
ref: TeamCollectionName,
|
||||
localField: 'teamId',
|
||||
foreignField: '_id',
|
||||
justOne: true
|
||||
});
|
||||
|
||||
try {
|
||||
InvitationSchema.index({ teamId: 1 });
|
||||
InvitationSchema.index({ expires: 1 }, { expireAfterSeconds: 30 * 24 * 60 * 60 });
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
}
|
||||
|
||||
export const MongoInvitationLink = getMongoModel<InvitationSchemaType>(
|
||||
InvitationCollectionName,
|
||||
InvitationSchema
|
||||
);
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user