Compare commits
19 Commits
v4.9.2-alp
...
v4.9.1-alp
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
3e21030536 | ||
|
|
7ec4ba7067 | ||
|
|
2d22af3cce | ||
|
|
4346c5703a | ||
|
|
f71ab0caeb | ||
|
|
c131c2a7dc | ||
|
|
d052d0de53 | ||
|
|
d1ce3e2936 | ||
|
|
c301dafca7 | ||
|
|
1a3613cd2c | ||
|
|
30f83f848d | ||
|
|
ac7091f8d6 | ||
|
|
16832caaf6 | ||
|
|
a3df9ea531 | ||
|
|
bcd0b010a6 | ||
|
|
3f794baf2e | ||
|
|
92b2ecc381 | ||
|
|
4dbe41db0e | ||
|
|
f9dd170895 |
3
.github/workflows/fastgpt-preview-image.yml
vendored
@@ -1,6 +1,9 @@
|
||||
name: Preview FastGPT images
|
||||
on:
|
||||
pull_request_target:
|
||||
paths:
|
||||
- 'projects/app/**'
|
||||
- 'packages/**'
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
|
||||
@@ -6,5 +6,4 @@ docSite/
|
||||
*.md
|
||||
|
||||
pnpm-lock.yaml
|
||||
cl100l_base.ts
|
||||
dict.json
|
||||
cl100l_base.ts
|
||||
7
.vscode/i18n-ally-custom-framework.yml
vendored
@@ -17,8 +17,15 @@ usageMatchRegex:
|
||||
# you can ignore it and use your own matching rules as well
|
||||
- "[^\\w\\d]t\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]commonT\\(['\"`]({key})['\"`]"
|
||||
# 支持 appT("your.i18n.keys")
|
||||
- "[^\\w\\d]appT\\(['\"`]({key})['\"`]"
|
||||
# 支持 datasetT("your.i18n.keys")
|
||||
- "[^\\w\\d]datasetT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]fileT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]publishT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]workflowT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]userT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]chatT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]i18nT\\(['\"`]({key})['\"`]"
|
||||
|
||||
# A RegEx to set a custom scope range. This scope will be used as a prefix when detecting keys
|
||||
|
||||
@@ -129,7 +129,7 @@ https://github.com/labring/FastGPT/assets/15308462/7d3a38df-eb0e-4388-9250-2409b
|
||||
</a>
|
||||
|
||||
## 🌿 第三方生态
|
||||
- [PPIO 派欧云:一键调用高性价比的开源模型 API 和 GPU 容器](https://ppinfra.com/user/register?invited_by=VITYVU&utm_source=github_fastgpt)
|
||||
|
||||
- [AI Proxy:国内模型聚合服务](https://sealos.run/aiproxy/?k=fastgpt-github/)
|
||||
- [SiliconCloud (硅基流动) —— 开源模型在线体验平台](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
||||
- [COW 个人微信/企微机器人](https://doc.tryfastgpt.ai/docs/use-cases/external-integration/onwechat/)
|
||||
|
||||
@@ -114,15 +114,15 @@ services:
|
||||
# fastgpt
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.0 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.0 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -175,8 +175,7 @@ services:
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
image: 'ghcr.io/labring/aiproxy:latest'
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
|
||||
@@ -72,15 +72,15 @@ services:
|
||||
# fastgpt
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.0 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.0 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -132,8 +132,7 @@ services:
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
image: 'ghcr.io/labring/aiproxy:latest'
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
|
||||
@@ -53,15 +53,15 @@ services:
|
||||
wait $$!
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.1-fix2 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.0 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.9.1-fix2 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.1-fix2 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.0 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -113,8 +113,7 @@ services:
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
image: 'ghcr.io/labring/aiproxy:latest'
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 68 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 179 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 20 KiB |
{kind=link}
|
Before Width: | Height: | Size: 138 KiB |
{kind=link}
|
Before Width: | Height: | Size: 122 KiB |
{kind=link}
|
Before Width: | Height: | Size: 124 KiB |
{kind=link}
|
Before Width: | Height: | Size: 94 KiB |
{kind=link}
|
Before Width: | Height: | Size: 57 KiB |
{kind=link}
|
Before Width: | Height: | Size: 76 KiB |
{kind=link}
|
Before Width: | Height: | Size: 26 KiB |
{kind=link}
|
Before Width: | Height: | Size: 170 KiB |
{kind=link}
|
Before Width: | Height: | Size: 102 KiB |
{kind=link}
|
Before Width: | Height: | Size: 70 KiB |
{kind=link}
|
Before Width: | Height: | Size: 89 KiB |
{kind=link}
|
Before Width: | Height: | Size: 87 KiB |
@@ -1,184 +0,0 @@
|
||||
---
|
||||
title: '使用 Ollama 接入本地模型 '
|
||||
description: ' 采用 Ollama 部署自己的模型'
|
||||
icon: 'api'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 950
|
||||
---
|
||||
|
||||
[Ollama](https://ollama.com/) 是一个开源的AI大模型部署工具,专注于简化大语言模型的部署和使用,支持一键下载和运行各种大模型。
|
||||
|
||||
## 安装 Ollama
|
||||
|
||||
Ollama 本身支持多种安装方式,但是推荐使用 Docker 拉取镜像部署。如果是个人设备上安装了 Ollama 后续需要解决如何让 Docker 中 FastGPT 容器访问宿主机 Ollama的问题,较为麻烦。
|
||||
|
||||
### Docker 安装(推荐)
|
||||
|
||||
你可以使用 Ollama 官方的 Docker 镜像来一键安装和启动 Ollama 服务(确保你的机器上已经安装了 Docker),命令如下:
|
||||
|
||||
```bash
|
||||
docker pull ollama/ollama
|
||||
docker run --rm -d --name ollama -p 11434:11434 ollama/ollama
|
||||
```
|
||||
|
||||
如果你的 FastGPT 是在 Docker 中进行部署的,建议在拉取 Ollama 镜像时保证和 FastGPT 镜像处于同一网络,否则可能出现 FastGPT 无法访问的问题,命令如下:
|
||||
|
||||
```bash
|
||||
docker run --rm -d --name ollama --network (你的 Fastgpt 容器所在网络) -p 11434:11434 ollama/ollama
|
||||
```
|
||||
|
||||
### 主机安装
|
||||
|
||||
如果你不想使用 Docker ,也可以采用主机安装,以下是主机安装的一些方式。
|
||||
|
||||
#### MacOS
|
||||
|
||||
如果你使用的是 macOS,且系统中已经安装了 Homebrew 包管理器,可通过以下命令来安装 Ollama:
|
||||
|
||||
```bash
|
||||
brew install ollama
|
||||
ollama serve #安装完成后,使用该命令启动服务
|
||||
```
|
||||
|
||||
#### Linux
|
||||
|
||||
在 Linux 系统上,你可以借助包管理器来安装 Ollama。以 Ubuntu 为例,在终端执行以下命令:
|
||||
|
||||
```bash
|
||||
curl https://ollama.com/install.sh | sh #此命令会从官方网站下载并执行安装脚本。
|
||||
ollama serve #安装完成后,同样启动服务
|
||||
```
|
||||
|
||||
#### Windows
|
||||
|
||||
在 Windows 系统中,你可以从 Ollama 官方网站 下载 Windows 版本的安装程序。下载完成后,运行安装程序,按照安装向导的提示完成安装。安装完成后,在命令提示符或 PowerShell 中启动服务:
|
||||
|
||||
```bash
|
||||
ollama serve #安装完成并启动服务后,你可以在浏览器中访问 http://localhost:11434 来验证 Ollama 是否安装成功。
|
||||
```
|
||||
|
||||
#### 补充说明
|
||||
|
||||
如果你是采用的主机应用 Ollama 而不是镜像,需要确保你的 Ollama 可以监听0.0.0.0。
|
||||
|
||||
##### 1. Linxu 系统
|
||||
|
||||
如果 Ollama 作为 systemd 服务运行,打开终端,编辑 Ollama 的 systemd 服务文件,使用命令sudo systemctl edit ollama.service,在[Service]部分添加Environment="OLLAMA_HOST=0.0.0.0"。保存并退出编辑器,然后执行sudo systemctl daemon - reload和sudo systemctl restart ollama使配置生效。
|
||||
|
||||
##### 2. MacOS 系统
|
||||
|
||||
打开终端,使用launchctl setenv ollama_host "0.0.0.0"命令设置环境变量,然后重启 Ollama 应用程序以使更改生效。
|
||||
|
||||
##### 3. Windows 系统
|
||||
|
||||
通过 “开始” 菜单或搜索栏打开 “编辑系统环境变量”,在 “系统属性” 窗口中点击 “环境变量”,在 “系统变量” 部分点击 “新建”,创建一个名为OLLAMA_HOST的变量,变量值设置为0.0.0.0,点击 “确定” 保存更改,最后从 “开始” 菜单重启 Ollama 应用程序。
|
||||
|
||||
### Ollama 拉取模型镜像
|
||||
|
||||
在安装后 Ollama 后,本地是没有模型镜像的,需要自己去拉取 Ollama 中的模型镜像。命令如下:
|
||||
|
||||
```bash
|
||||
# Docker 部署需要先进容器,命令为: docker exec -it < Ollama 容器名 > /bin/sh
|
||||
ollama pull <模型名>
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
### 测试通信
|
||||
|
||||
在安装完成后,需要进行检测测试,首先进入 FastGPT 所在的容器,尝试访问自己的 Ollama ,命令如下:
|
||||
|
||||
```bash
|
||||
docker exec -it < FastGPT 所在的容器名 > /bin/sh
|
||||
curl http://XXX.XXX.XXX.XXX:11434 #容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||||
```
|
||||
|
||||
看到访问显示自己的 Ollama 服务以及启动,说明可以正常通信。
|
||||
|
||||
## 将 Ollama 接入 FastGPT
|
||||
|
||||
### 1. 查看 Ollama 所拥有的模型
|
||||
|
||||
首先采用下述命令查看 Ollama 中所拥有的模型,
|
||||
|
||||
```bash
|
||||
# Docker 部署 Ollama,需要此命令 docker exec -it < Ollama 容器名 > /bin/sh
|
||||
ollama ls
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 2. AI Proxy 接入
|
||||
|
||||
如果你采用的是 FastGPT 中的默认配置文件部署[这里](/docs/development/docker.md),即默认采用 AI Proxy 进行启动。
|
||||
|
||||

|
||||
|
||||
以及在确保你的 FastGPT 可以直接访问 Ollama 容器的情况下,无法访问,参考上文[点此跳转](#安装-ollama)的安装过程,检测是不是主机不能监测0.0.0.0,或者容器不在同一个网络。
|
||||
|
||||

|
||||
|
||||
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。详细参考[这里](/docs/development/modelConfig/intro.md)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
运行 FastGPT ,在页面中选择账号->模型提供商->模型渠道->新增渠道。之后,在渠道选择中选择 Ollama ,然后加入自己拉取的模型,填入代理地址,如果是容器中安装 Ollama ,代理地址为http://地址:端口,补充:容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||||
|
||||

|
||||
|
||||
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||||
|
||||

|
||||
|
||||
### 3. OneAPI 接入
|
||||
|
||||
如果你想使用 OneAPI ,首先需要拉取 OneAPI 镜像,然后将其在 FastGPT 容器的网络中运行。具体命令如下:
|
||||
|
||||
```bash
|
||||
# 拉取 oneAPI 镜像
|
||||
docker pull intel/oneapi-hpckit
|
||||
|
||||
# 运行容器并指定自定义网络和容器名
|
||||
docker run -it --network < FastGPT 网络 > --name 容器名 intel/oneapi-hpckit /bin/bash
|
||||
```
|
||||
|
||||
进入 OneAPI 页面,添加新的渠道,类型选择 Ollama ,在模型中填入自己 Ollama 中的模型,需要保证添加的模型名称和 Ollama 中一致,再在下方填入自己的 Ollama 代理地址,默认http://地址:端口,不需要填写/v1。添加成功后在 OneAPI 进行渠道测试,测试成功则说明添加成功。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||||
|
||||

|
||||
|
||||
渠道添加成功后,点击令牌,点击添加令牌,填写名称,修改配置。
|
||||
|
||||

|
||||
|
||||
修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,在 OPENAI_BASE_URL 中加入自己的 OneAPI 开放地址,默认是http://地址:端口/v1,v1必须填写。KEY 中填写自己在 OneAPI 的令牌。
|
||||
|
||||

|
||||
|
||||
[直接跳转5](#5-模型添加和使用)添加模型,并使用。
|
||||
|
||||
### 4. 直接接入
|
||||
|
||||
如果你既不想使用 AI Proxy,也不想使用 OneAPI,也可以选择直接接入,修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,采用和 OneAPI 的类似配置。注释掉 AIProxy 相关代码,在OPENAI_BASE_URL中加入自己的 Ollama 开放地址,默认是http://地址:端口/v1,强调:v1必须填写。在KEY中随便填入,因为 Ollama 默认没有鉴权,如果开启鉴权,请自行填写。其他操作和在 OneAPI 中加入 Ollama 一致,只需在 FastGPT 中加入自己的模型即可使用。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||||
|
||||

|
||||
|
||||
完成后[点击这里](#5-模型添加和使用)进行模型添加并使用。
|
||||
|
||||
### 5. 模型添加和使用
|
||||
|
||||
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||||
|
||||

|
||||
|
||||
### 6. 补充
|
||||
上述接入 Ollama 的代理地址中,主机安装 Ollama 的地址为“http://<主机IP>:<端口>”,容器部署 Ollama 地址为“http://<容器名>:<端口>”
|
||||
@@ -56,7 +56,7 @@ weight: 707
|
||||
|
||||
### zilliz cloud版本
|
||||
|
||||
Zilliz Cloud 由 Milvus 原厂打造,是全托管的 SaaS 向量数据库服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||||
Milvus 的全托管服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||||
|
||||
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
|
||||
|
||||
|
||||
@@ -1,100 +0,0 @@
|
||||
---
|
||||
title: '通过 PPIO LLM API 接入模型'
|
||||
description: '通过 PPIO LLM API 接入模型'
|
||||
icon: 'api'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 747
|
||||
---
|
||||
|
||||
FastGPT 还可以通过 PPIO LLM API 接入模型。
|
||||
{{% alert context="warning" %}}
|
||||
以下内容搬运自 [FastGPT 接入 PPIO LLM API](https://ppinfra.com/docs/third-party/fastgpt-use),可能会有更新不及时的情况。
|
||||
{{% /alert %}}
|
||||
|
||||
FastGPT 是一个将 AI 开发、部署和使用全流程简化为可视化操作的平台。它使开发者不需要深入研究算法,
|
||||
用户也不需要掌握复杂技术,通过一站式服务将人工智能技术变成易于使用的工具。
|
||||
|
||||
PPIO 派欧云提供简单易用的 API 接口,让开发者能够轻松调用 DeepSeek 等模型。
|
||||
|
||||
- 对开发者:无需重构架构,3 个接口完成从文本生成到决策推理的全场景接入,像搭积木一样设计 AI 工作流;
|
||||
- 对生态:自动适配从中小应用到企业级系统的资源需求,让智能随业务自然生长。
|
||||
|
||||
下方教程提供完整接入方案(含密钥配置),帮助您快速将 FastGPT 与 PPIO API 连接起来。
|
||||
|
||||
## 1. 配置前置条件
|
||||
|
||||
(1) 获取 API 接口地址
|
||||
|
||||
固定为: `https://api.ppinfra.com/v3/openai/chat/completions`。
|
||||
|
||||
(2) 获取 【API 密钥】
|
||||
|
||||
登录派欧云控制台 [API 秘钥管理](https://www.ppinfra.com/settings/key-management) 页面,点击创建按钮。
|
||||
注册账号填写邀请码【VOJL20】得 50 代金券
|
||||
|
||||
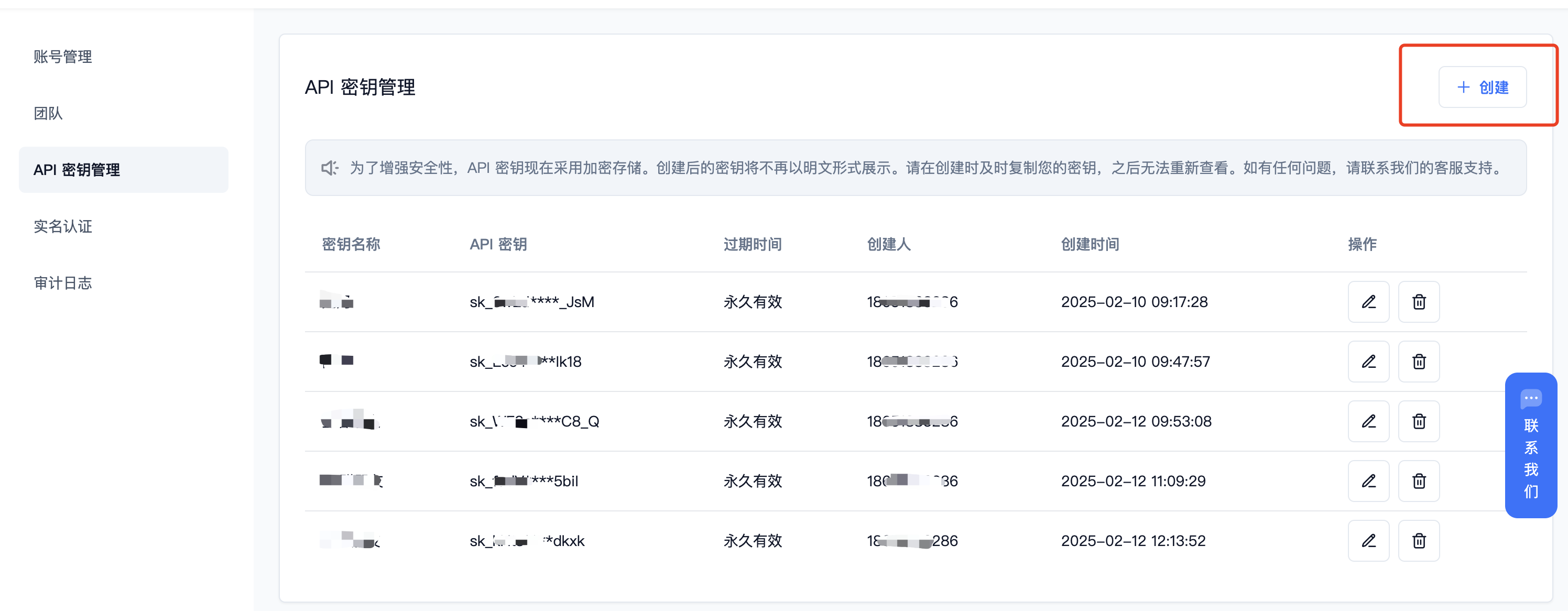
|
||||
|
||||
(3) 生成并保存 【API 密钥】
|
||||
{{% alert context="warning" %}}
|
||||
秘钥在服务端是加密存储,请在生成时保存好秘钥;若遗失可以在控制台上删除并创建一个新的秘钥。
|
||||
{{% /alert %}}
|
||||
|
||||
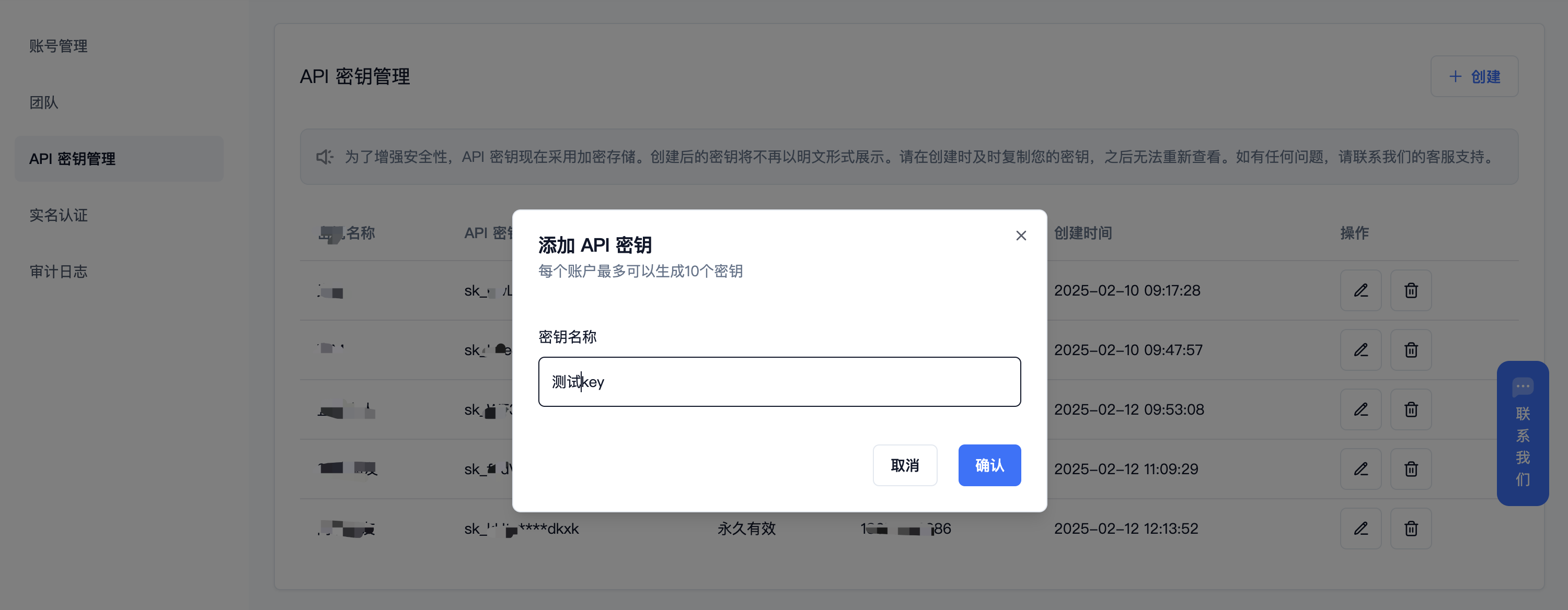
|
||||
|
||||
|
||||
(4) 获取需要使用的模型 ID
|
||||
|
||||
deepseek 系列:
|
||||
|
||||
- DeepSeek R1:deepseek/deepseek-r1/community
|
||||
|
||||
- DeepSeek V3:deepseek/deepseek-v3/community
|
||||
|
||||
其他模型 ID、最大上下文及价格可参考:[模型列表](https://ppinfra.com/model-api/pricing)
|
||||
|
||||
## 2. 部署最新版 FastGPT 到本地环境
|
||||
{{% alert context="warning" %}}
|
||||
请使用 v4.8.22 以上版本,部署参考: https://doc.tryfastgpt.ai/docs/development/intro/
|
||||
{{% /alert %}}
|
||||
|
||||
## 3. 模型配置(下面两种方式二选其一)
|
||||
|
||||
(1)通过 OneAPI 接入模型 PPIO 模型: 参考 OneAPI 使用文档,修改 FastGPT 的环境变量 在 One API 生成令牌后,FastGPT 可以通过修改 baseurl 和 key 去请求到 One API,再由 One API 去请求不同的模型。修改下面两个环境变量: 务必写上 v1。如果在同一个网络内,可改成内网地址。
|
||||
|
||||
OPENAI_BASE_URL= http://OneAPI-IP:OneAPI-PORT/v1
|
||||
|
||||
下面的 key 是由 One API 提供的令牌 CHAT_API_KEY=sk-UyVQcpQWMU7ChTVl74B562C28e3c46Fe8f16E6D8AeF8736e
|
||||
|
||||
- 修改后重启 FastGPT,按下图在模型提供商中选择派欧云
|
||||
|
||||
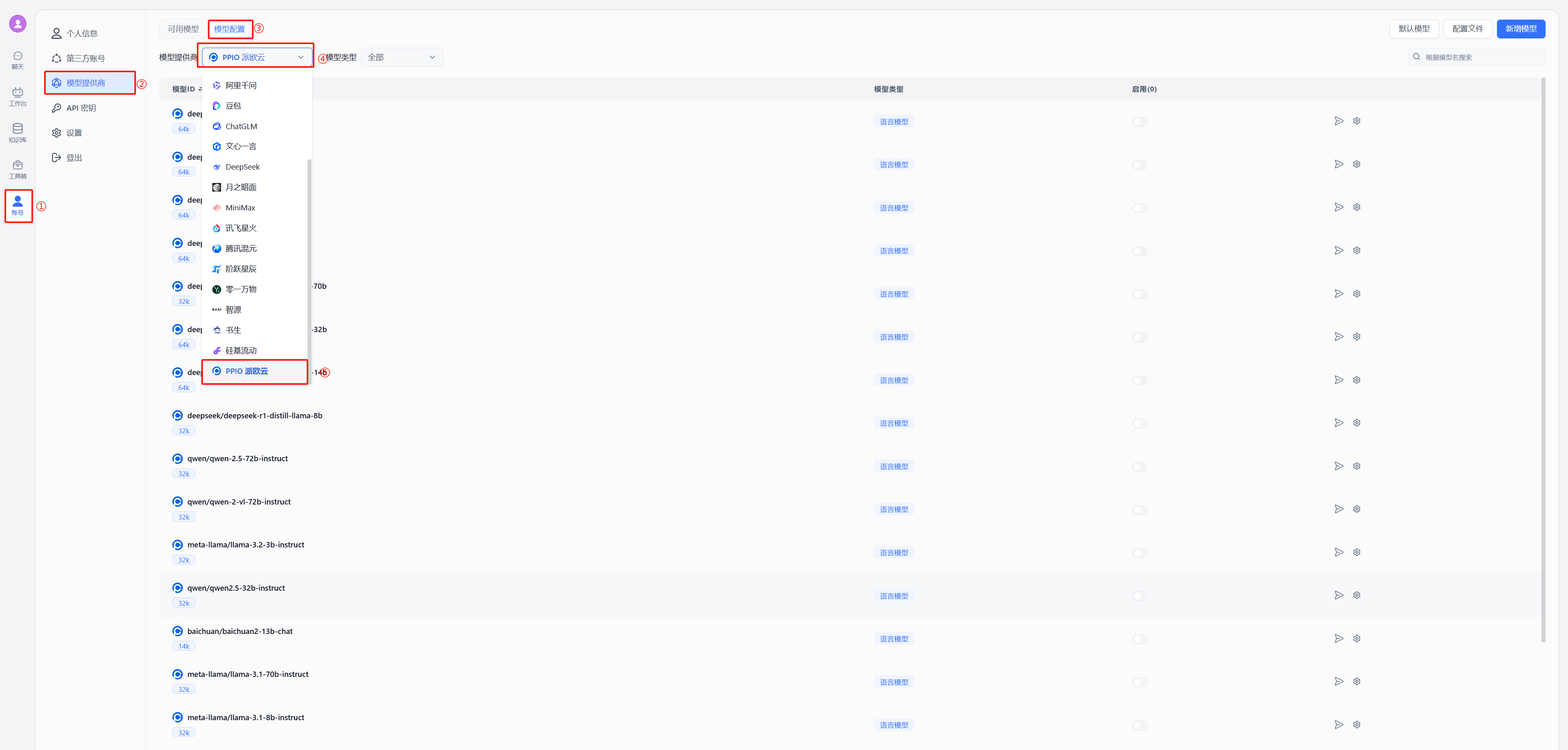
|
||||
|
||||
- 测试连通性
|
||||
以 deepseek 为例,在模型中选择使用 deepseek/deepseek-r1/community,点击图中②的位置进行连通性测试,出现图中绿色的的成功显示证明连通成功,可以进行后续的配置对话了
|
||||
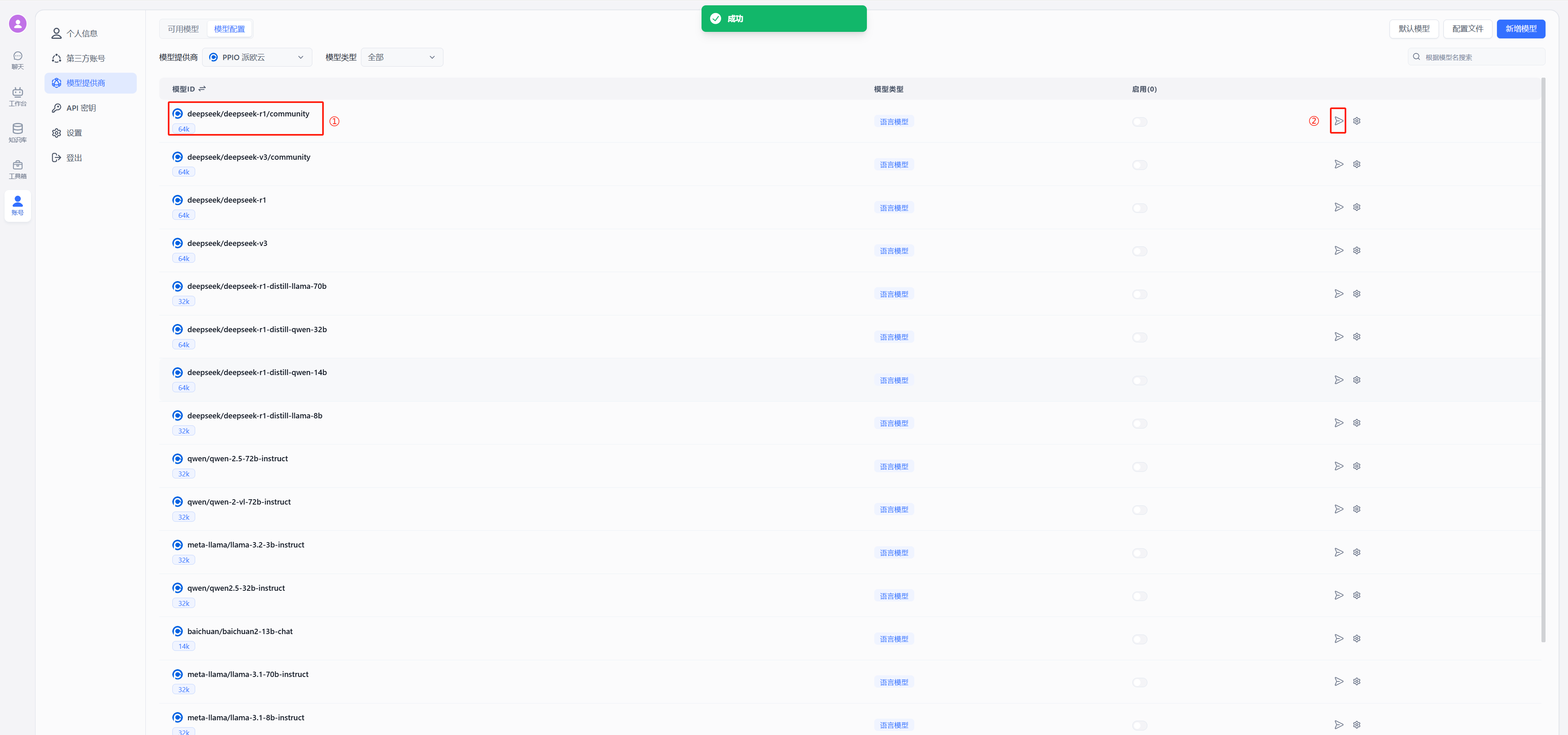
|
||||
|
||||
(2)不使用 OneAPI 接入 PPIO 模型
|
||||
|
||||
按照下图在模型提供商中选择派欧云
|
||||
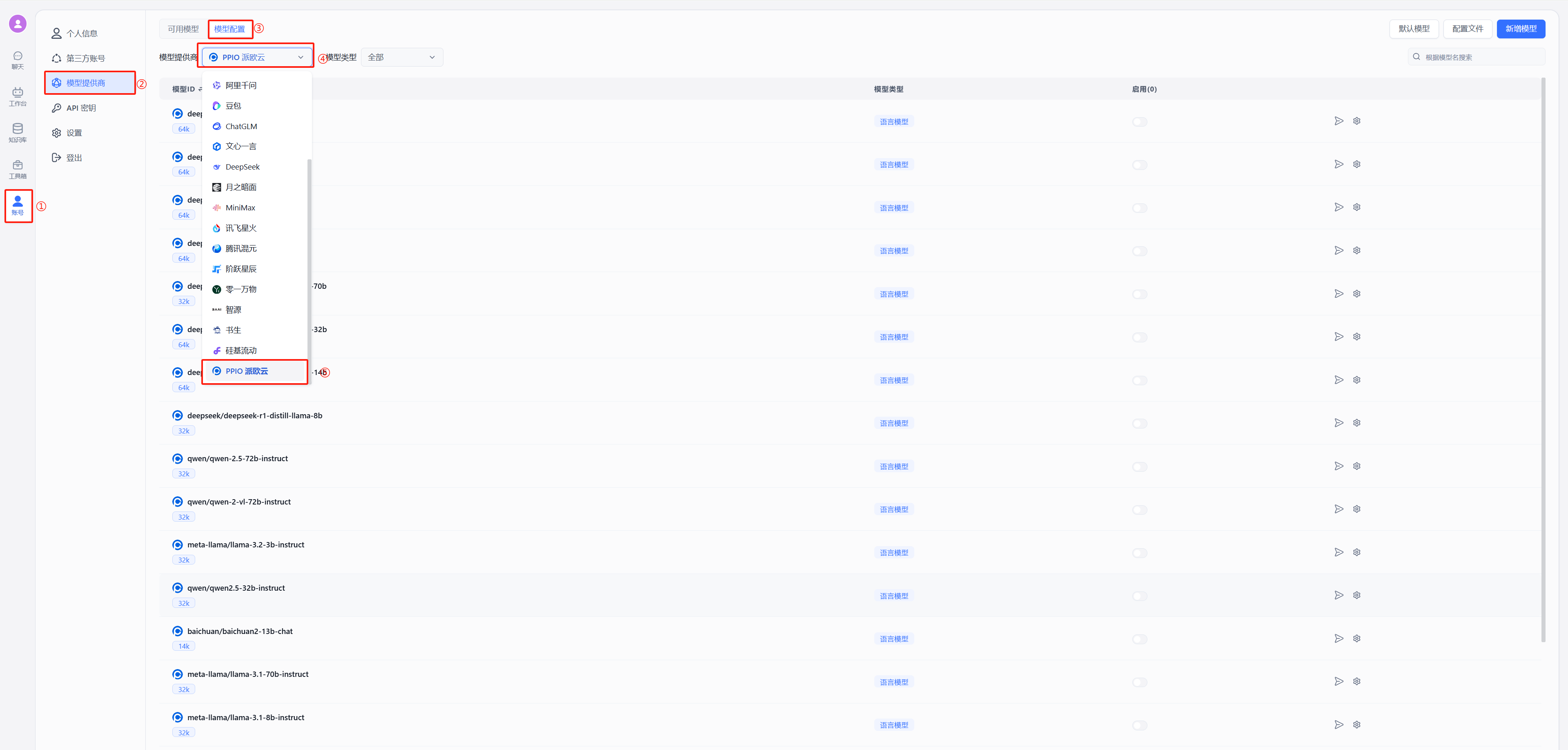
|
||||
|
||||
- 配置模型 自定义请求地址中输入:`https://api.ppinfra.com/v3/openai/chat/completions`
|
||||
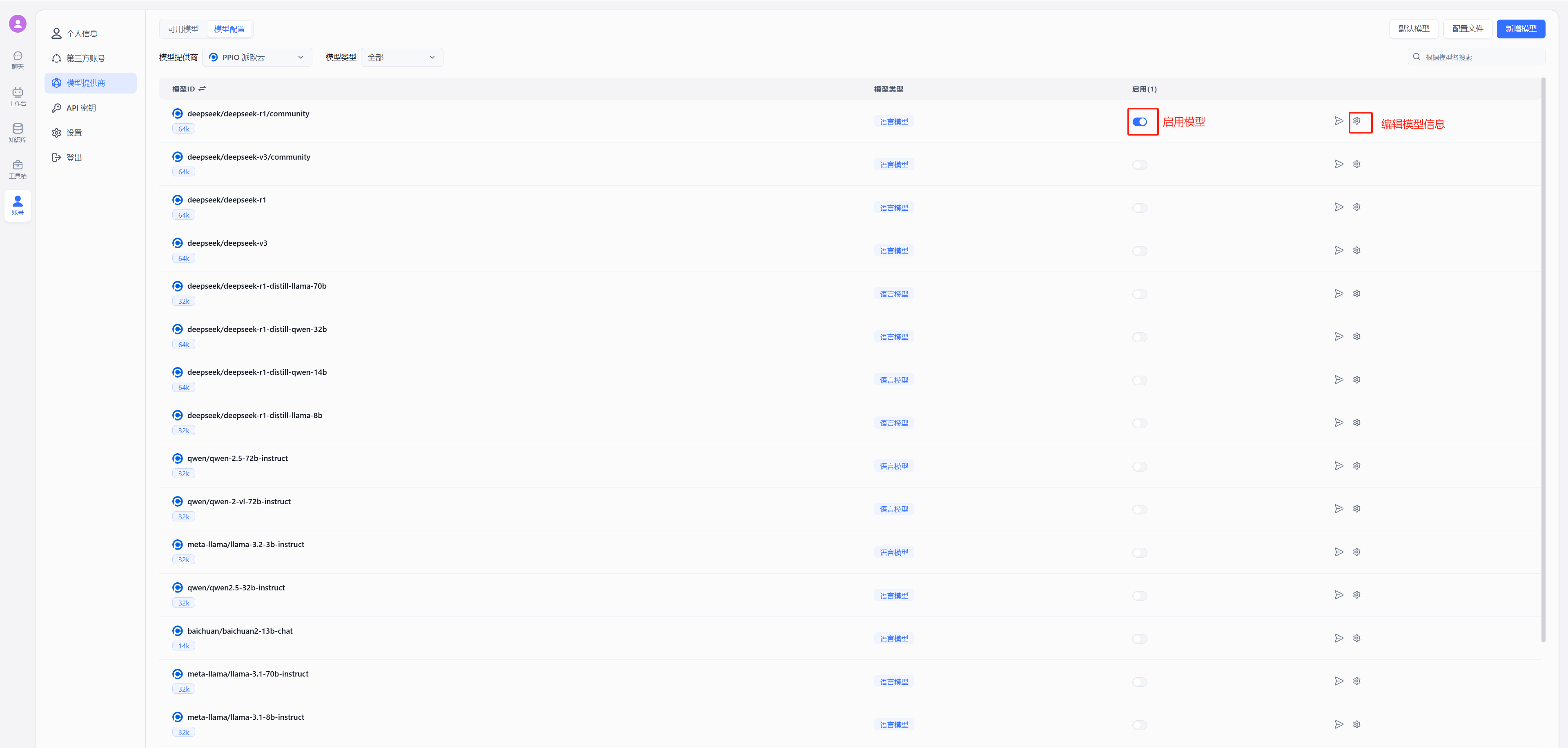
|
||||
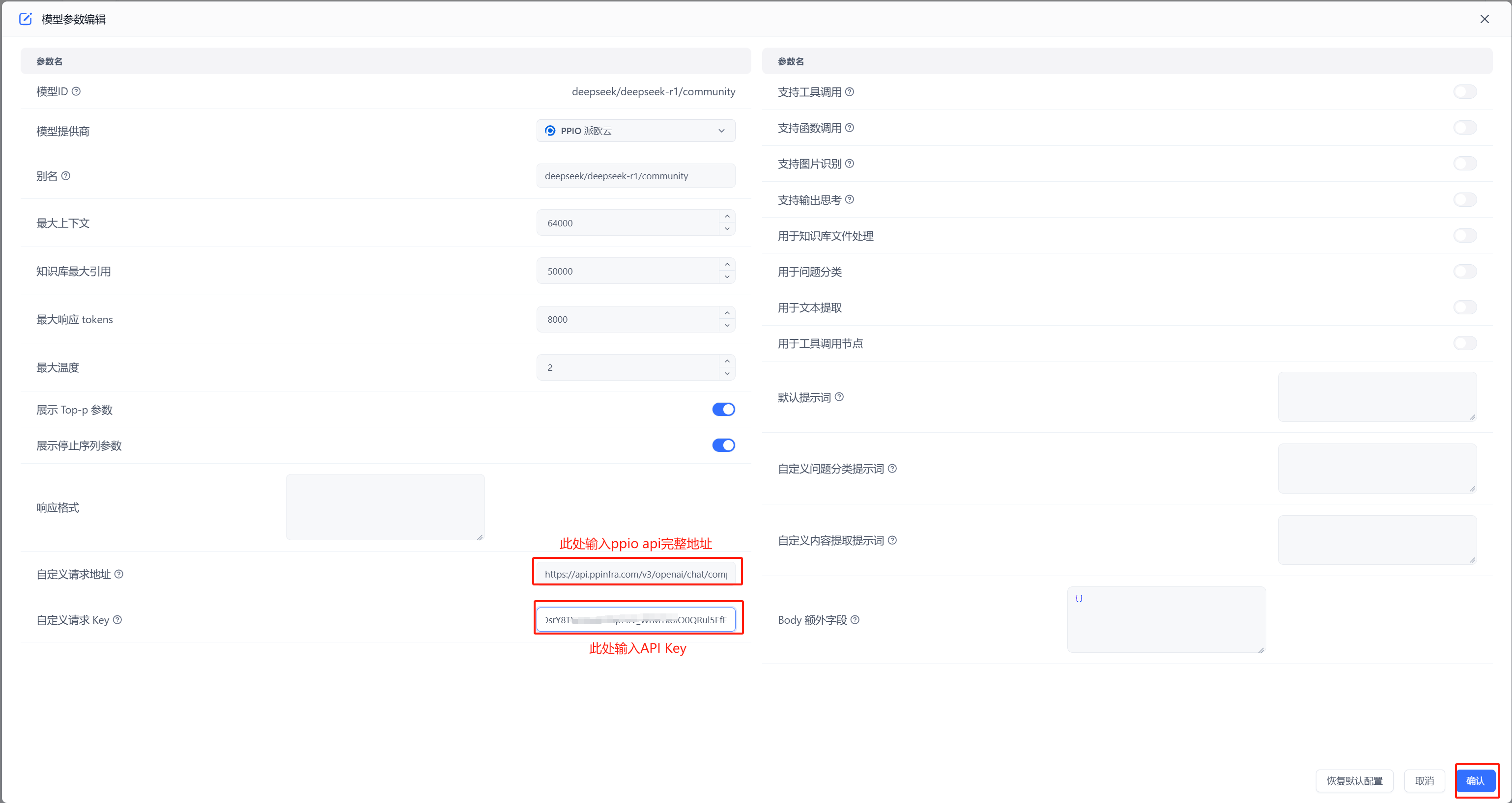
|
||||
|
||||
- 测试连通性
|
||||
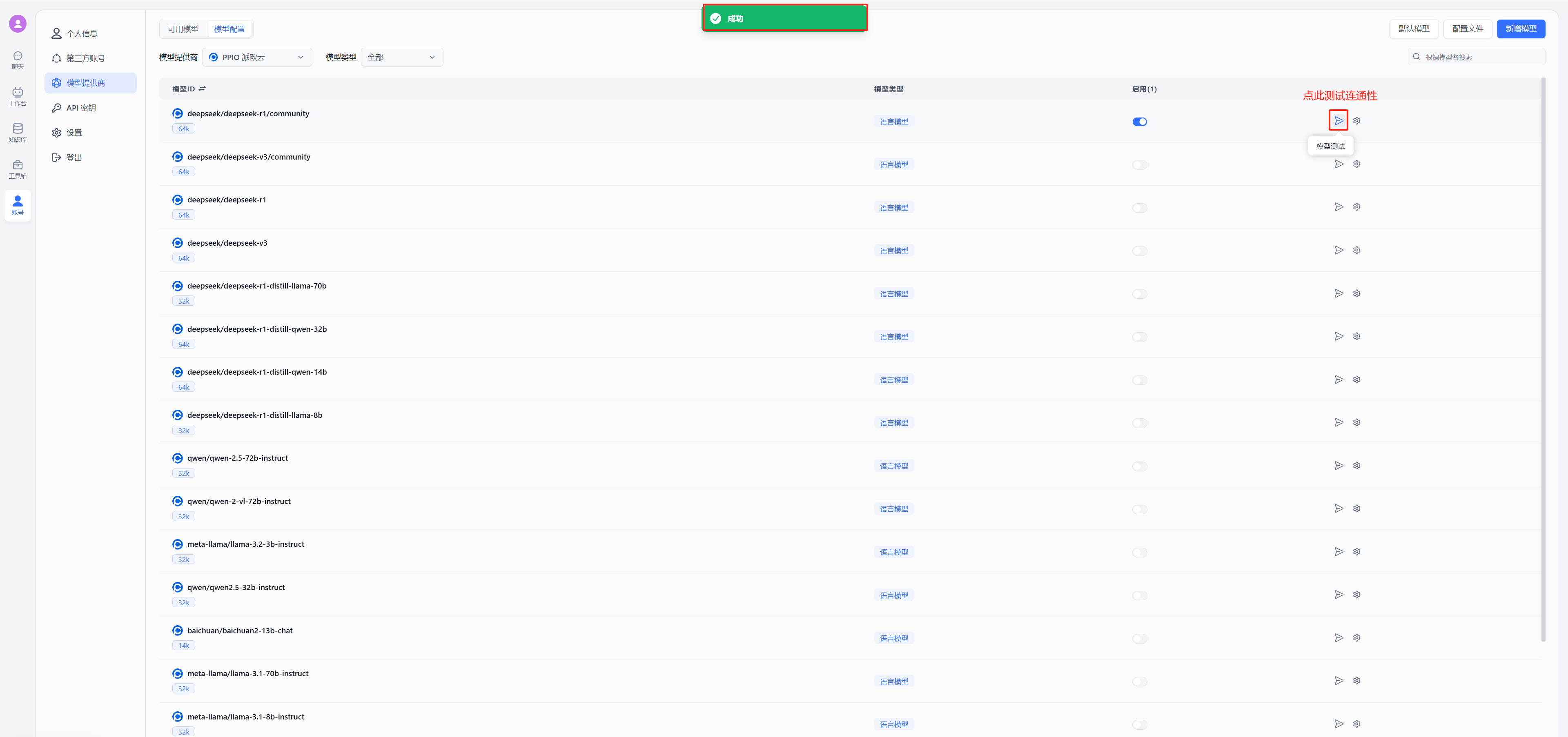
|
||||
|
||||
出现图中绿色的的成功显示证明连通成功,可以进行对话配置
|
||||
|
||||
## 4. 配置对话
|
||||
(1)新建工作台
|
||||
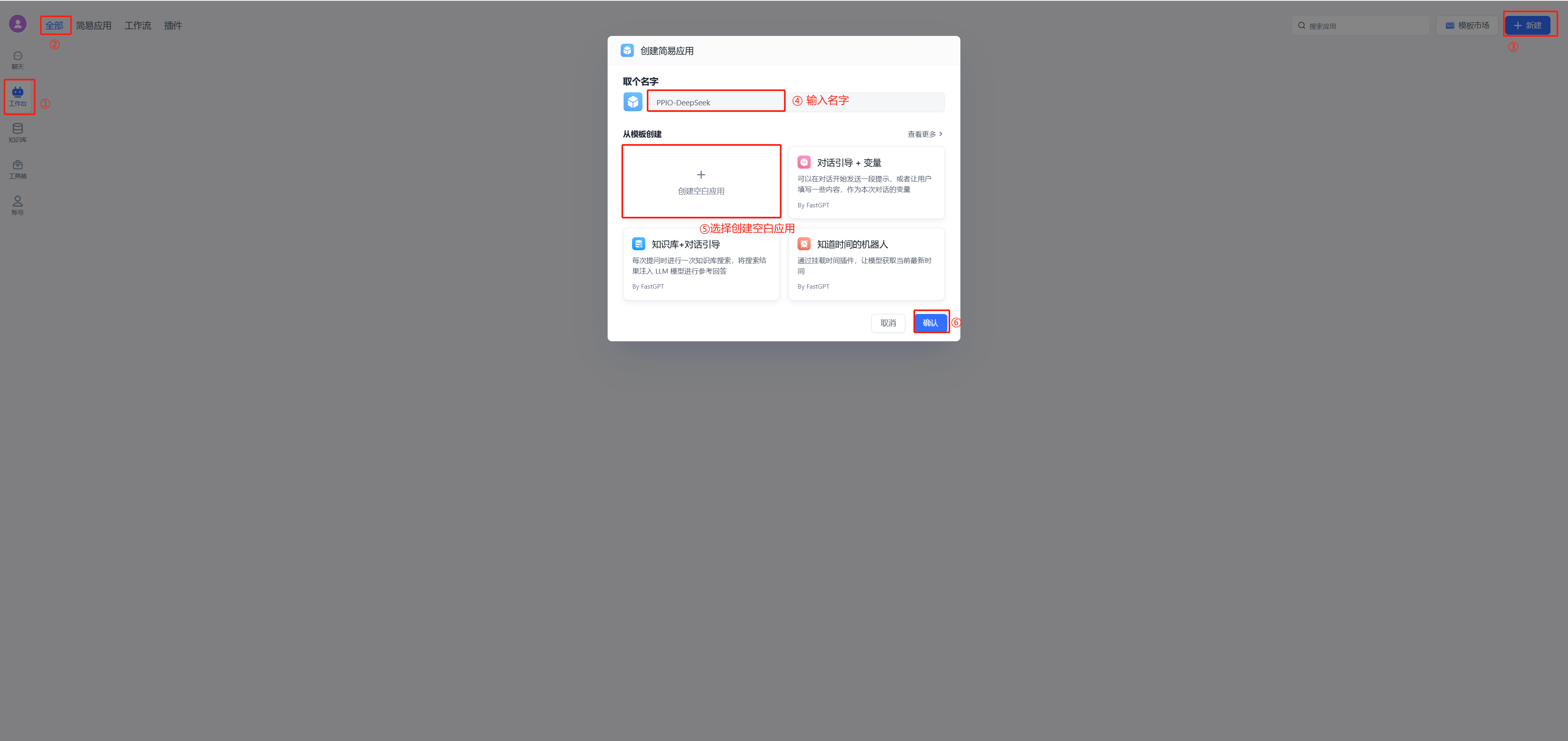
|
||||
(2)开始聊天
|
||||
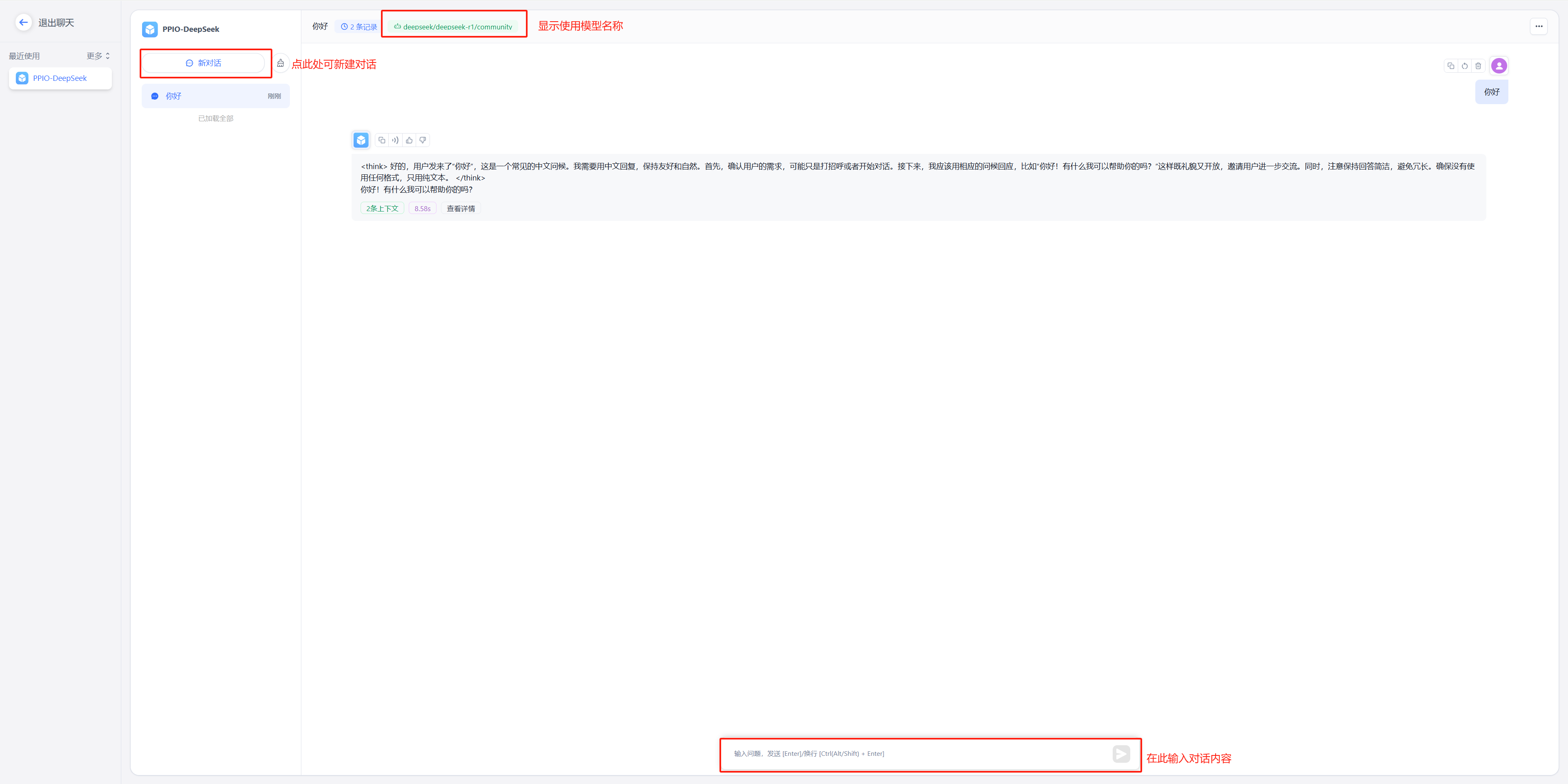
|
||||
|
||||
## PPIO 全新福利重磅来袭 🔥
|
||||
顺利完成教程配置步骤后,您将解锁两大权益:1. 畅享 PPIO 高速通道与 FastGPT 的效能组合;2.立即激活 **「新用户邀请奖励」** ————通过专属邀请码邀好友注册,您与好友可各领 50 元代金券,硬核福利助力 AI 工具效率倍增!
|
||||
|
||||
🎁 新手专享:立即使用邀请码【VOJL20】完成注册,50 元代金券奖励即刻到账!
|
||||
@@ -11,6 +11,8 @@ weight: 853
|
||||
| --------------------- | --------------------- |
|
||||
|  |  |
|
||||
|
||||
|
||||
|
||||
## 创建训练订单
|
||||
|
||||
{{< tabs tabTotal="2" >}}
|
||||
@@ -287,7 +289,7 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?
|
||||
|
||||
## 集合
|
||||
|
||||
### 通用创建参数说明(必看)
|
||||
### 通用创建参数说明
|
||||
|
||||
**入参**
|
||||
|
||||
@@ -298,11 +300,8 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?
|
||||
| trainingType | 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 | ✅ |
|
||||
| autoIndexes | 是否自动生成索引(仅商业版支持) | |
|
||||
| imageIndex | 是否自动生成图片索引(仅商业版支持) | |
|
||||
| chunkSettingMode | 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 | |
|
||||
| chunkSplitMode | 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 | |
|
||||
| chunkSize | 分块大小,默认 1500。chunkSettingMode=auto时不生效。 | |
|
||||
| indexSize | 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 | |
|
||||
| chunkSplitter | 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 | |
|
||||
| chunkSize | 预估块大小 | |
|
||||
| chunkSplitter | 自定义最高优先分割符号 | |
|
||||
| qaPrompt | qa拆分提示词 | |
|
||||
| tags | 集合标签(字符串数组) | |
|
||||
| createTime | 文件创建时间(Date / String) | |
|
||||
@@ -390,8 +389,9 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
"name":"测试训练",
|
||||
|
||||
"trainingType": "qa",
|
||||
"chunkSettingMode": "auto",
|
||||
"qaPrompt":"",
|
||||
"chunkSize":8000,
|
||||
"chunkSplitter":"",
|
||||
"qaPrompt":"11",
|
||||
|
||||
"metadata":{}
|
||||
}'
|
||||
@@ -409,6 +409,10 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
- parentId: 父级ID,不填则默认为根目录
|
||||
- name: 集合名称(必填)
|
||||
- metadata: 元数据(暂时没啥用)
|
||||
- trainingType: 训练模式(必填)
|
||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
||||
- qaPrompt: qa拆分自定义提示词(可选)
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
@@ -458,7 +462,8 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
"parentId": null,
|
||||
|
||||
"trainingType": "chunk",
|
||||
"chunkSettingMode": "auto",
|
||||
"chunkSize":512,
|
||||
"chunkSplitter":"",
|
||||
"qaPrompt":"",
|
||||
|
||||
"metadata":{
|
||||
@@ -478,6 +483,10 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
- datasetId: 知识库的ID(必填)
|
||||
- parentId: 父级ID,不填则默认为根目录
|
||||
- metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选)
|
||||
- trainingType:训练模式(必填)
|
||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
||||
- qaPrompt: qa拆分自定义提示词(可选)
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
@@ -536,7 +545,13 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
|
||||
{{% alert icon=" " context="success" %}}
|
||||
- file: 文件
|
||||
- data: 知识库相关信息(json序列化后传入),参数说明见上方“通用创建参数说明”
|
||||
- data: 知识库相关信息(json序列化后传入)
|
||||
- datasetId: 知识库的ID(必填)
|
||||
- parentId: 父级ID,不填则默认为根目录
|
||||
- trainingType:训练模式(必填)
|
||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
||||
- qaPrompt: qa拆分自定义提示词(可选)
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
|
||||
@@ -7,39 +7,12 @@ toc: true
|
||||
weight: 799
|
||||
---
|
||||
|
||||
## 更新指南
|
||||
|
||||
### 1. 做好数据库备份
|
||||
|
||||
### 2. 更新镜像
|
||||
|
||||
- 更新 FastGPT 镜像 tag: v4.9.1-fix2
|
||||
- 更新 FastGPT 商业版镜像 tag: v4.9.1-fix2
|
||||
- Sandbox 镜像,可以不更新
|
||||
- AIProxy 镜像修改为: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3
|
||||
|
||||
### 3. 执行升级脚本
|
||||
|
||||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||
--header 'rootkey: {{rootkey}}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
**脚本功能**
|
||||
|
||||
重新使用最新的 jieba 分词库进行分词处理。时间较长,可以从日志里查看进度。
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
1. 商业版支持单团队模式,更好的管理内部成员。
|
||||
2. 知识库分块阅读器。
|
||||
3. API 知识库支持 PDF 增强解析。
|
||||
4. 邀请团队成员,改为邀请链接模式。
|
||||
5. 支持混合检索权重设置。
|
||||
6. 支持重排模型选择和权重设置,同时调整了知识库搜索权重计算方式,改成 搜索权重 + 重排权重,而不是向量检索权重+全文检索权重+重排权重。
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
@@ -48,7 +21,6 @@ curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||
3. 增加依赖包安全版本检测,并升级部分依赖包。
|
||||
4. 模型测试代码。
|
||||
5. 优化思考过程解析逻辑:只要配置了模型支持思考,均会解析 <think> 标签,不会因为对话时,关闭思考而不解析。
|
||||
6. 载入最新 jieba 分词库,增强全文检索分词效果。
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
@@ -60,6 +32,3 @@ curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||
6. 模型渠道测试时,实际未指定渠道测试。
|
||||
7. 新增自定义模型时,会把默认模型字段也保存,导致默认模型误判。
|
||||
8. 修复 promp 模式工具调用,未判空思考链,导致 UI 错误展示。
|
||||
9. 编辑应用信息导致头像丢失。
|
||||
10. 分享链接标题会被刷新掉。
|
||||
11. 计算 parentPath 时,存在鉴权失败清空。
|
||||
|
||||
@@ -1,44 +0,0 @@
|
||||
---
|
||||
title: 'V4.9.2(进行中)'
|
||||
description: 'FastGPT V4.9.2 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 799
|
||||
---
|
||||
|
||||
## 重要提示
|
||||
|
||||
- 知识库导入数据 API 变更,增加`chunkSettingMode`,`chunkSplitMode`,`indexSize`可选参数,具体可参考 [知识库导入数据 API](/docs/development/openapi/dataset) 文档。
|
||||
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
1. 知识库分块优化:支持单独配置分块大小和索引大小,允许进行超大分块,以更大的输入 Tokens 换取完整分块。
|
||||
2. 知识库分块增加自定义分隔符预设值,同时支持自定义换行符分割。
|
||||
3. 外部变量改名:自定义变量。 并且支持在测试时调试,在分享链接中,该变量直接隐藏。
|
||||
4. 集合同步时,支持同步修改标题。
|
||||
5. 团队成员管理重构,抽离主流 IM SSO(企微、飞书、钉钉),并支持通过自定义 SSO 接入 FastGPT。同时完善与外部系统的成员同步。
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
1. 导出对话日志时,支持导出成员名。
|
||||
2. 邀请链接交互。
|
||||
3. 无 SSL 证书时复制失败,会提示弹窗用于手动复制。
|
||||
4. FastGPT 未内置 ai proxy 渠道时,也能正常展示其名称。
|
||||
5. 升级 nextjs 版本至 14.2.25。
|
||||
6. 工作流节点数组字符串类型,自动适配 string 输入。
|
||||
7. 工作流节点数组类型,自动进行 JSON parse 解析 string 输入。
|
||||
8. AI proxy 日志优化,去除重试失败的日志,仅保留最后一份错误日志。
|
||||
9. 分块算法小调整:
|
||||
* 跨处理符号之间连续性更强。
|
||||
* 代码块分割时,用 LLM 模型上下文作为分块大小,尽可能保证代码块完整性。
|
||||
* 表格分割时,用 LLM 模型上下文作为分块大小,尽可能保证表格完整性。
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
1. 飞书和语雀知识库无法同步。
|
||||
2. 渠道测试时,如果配置了模型自定义请求地址,会走自定义请求地址,而不是渠道请求地址。
|
||||
3. 语音识别模型测试未启用的模型时,无法正常测试。
|
||||
4. 管理员配置系统插件时,如果插件包含其他系统应用,无法正常鉴权。
|
||||
5. 移除 TTS 自定义请求地址时,必须需要填 requestAuth 字段。
|
||||
@@ -124,7 +124,6 @@ curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
|
||||
"success": true,
|
||||
"message": "",
|
||||
"data": {
|
||||
"title": "文档标题",
|
||||
"content": "FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!\n",
|
||||
"previewUrl": "xxxx"
|
||||
}
|
||||
@@ -132,13 +131,10 @@ curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
|
||||
```
|
||||
|
||||
{{% alert icon=" " context="success" %}}
|
||||
二选一返回,如果同时返回则 content 优先级更高。
|
||||
|
||||
- title - 文件标题。
|
||||
- content - 文件内容,直接拿来用。
|
||||
- previewUrl - 文件链接,系统会请求该地址获取文件内容。
|
||||
|
||||
`content`和`previewUrl`二选一返回,如果同时返回则 `content` 优先级更高,返回 `previewUrl`时,则会访问该链接进行文档内容读取。
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
|
||||
@@ -1,66 +0,0 @@
|
||||
---
|
||||
title: "邀请链接说明文档"
|
||||
description: "如何使用邀请链接来邀请团队成员"
|
||||
icon: "group"
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 451
|
||||
---
|
||||
|
||||
v4.9.1 团队邀请成员将开始使用「邀请链接」的模式,弃用之前输入用户名进行添加的形式。
|
||||
|
||||
在版本升级后,原收到邀请还未加入团队的成员,将自动清除邀请。请使用邀请链接重新邀请成员。
|
||||
|
||||
## 如何使用
|
||||
|
||||
1. **在团队管理页面,管理员可点击「邀请成员」按钮打开邀请成员弹窗**
|
||||
|
||||

|
||||
|
||||
2. **在邀请成员弹窗中,点击「创建邀请链接」按钮,创建邀请链接。**
|
||||
|
||||

|
||||
|
||||
3. **输入对应内容**
|
||||
|
||||

|
||||
|
||||
链接描述:建议将链接描述为使用场景或用途。链接创建后不支持修改噢。
|
||||
|
||||
有效期:30分钟,7天,1年
|
||||
|
||||
有效人数:1人,无限制
|
||||
|
||||
4. **点击复制链接,并将其发送给想要邀请的人。**
|
||||
|
||||

|
||||
|
||||
5. **用户访问链接后,如果未登录/未注册,则先跳转到登录页面进行登录。在登录后将进入团队页面,处理邀请。**
|
||||
|
||||
> 邀请链接形如:fastgpt.cn/account/team?invitelinkid=xxxx
|
||||
|
||||

|
||||
|
||||
点击接受,则用户将加入团队
|
||||
|
||||
点击忽略,则关闭弹窗,用户下次访问该邀请链接则还可以选择加入。
|
||||
|
||||
## 链接失效和自动清理
|
||||
|
||||
### 链接失效原因
|
||||
|
||||
手动停用链接
|
||||
|
||||
邀请链接到达有效期,自动停用
|
||||
|
||||
有效人数为1人的链接,已有1人通过邀请链接加入团队。
|
||||
|
||||
停用的链接无法访问,也无法再次启用。
|
||||
|
||||
### 链接上限
|
||||
|
||||
一个用户最多可以同时存在 10 个**有效的**邀请链接。
|
||||
|
||||
### 链接自动清理
|
||||
|
||||
失效的链接将在 30 天后自动清理。
|
||||
@@ -12,7 +12,7 @@
|
||||
"previewIcon": "node ./scripts/icon/index.js",
|
||||
"api:gen": "tsc ./scripts/openapi/index.ts && node ./scripts/openapi/index.js && npx @redocly/cli build-docs ./scripts/openapi/openapi.json -o ./projects/app/public/openapi/index.html",
|
||||
"create:i18n": "node ./scripts/i18n/index.js",
|
||||
"test": "vitest run --exclude 'test/cases/spec'",
|
||||
"test": "vitest run --exclude './projects/app/src/test/**'",
|
||||
"test:all": "vitest run",
|
||||
"test:workflow": "vitest run workflow"
|
||||
},
|
||||
@@ -20,9 +20,9 @@
|
||||
"@chakra-ui/cli": "^2.4.1",
|
||||
"@vitest/coverage-v8": "^3.0.2",
|
||||
"husky": "^8.0.3",
|
||||
"i18next": "23.16.8",
|
||||
"i18next": "23.11.5",
|
||||
"lint-staged": "^13.3.0",
|
||||
"next-i18next": "15.4.2",
|
||||
"next-i18next": "15.3.0",
|
||||
"prettier": "3.2.4",
|
||||
"react-i18next": "14.1.2",
|
||||
"vitest": "^3.0.2",
|
||||
|
||||
@@ -1,8 +1,3 @@
|
||||
export type GetPathProps = {
|
||||
sourceId?: ParentIdType;
|
||||
type: 'current' | 'parent';
|
||||
};
|
||||
|
||||
export type ParentTreePathItemType = {
|
||||
parentId: string;
|
||||
parentName: string;
|
||||
|
||||
@@ -1,17 +1,16 @@
|
||||
import { defaultMaxChunkSize } from '../../core/dataset/training/utils';
|
||||
import { getErrText } from '../error/utils';
|
||||
import { replaceRegChars } from './tools';
|
||||
|
||||
export const CUSTOM_SPLIT_SIGN = '-----CUSTOM_SPLIT_SIGN-----';
|
||||
|
||||
type SplitProps = {
|
||||
text: string;
|
||||
chunkSize: number;
|
||||
maxSize?: number;
|
||||
chunkLen: number;
|
||||
overlapRatio?: number;
|
||||
customReg?: string[];
|
||||
};
|
||||
export type TextSplitProps = Omit<SplitProps, 'text' | 'chunkSize'> & {
|
||||
chunkSize?: number;
|
||||
export type TextSplitProps = Omit<SplitProps, 'text' | 'chunkLen'> & {
|
||||
chunkLen?: number;
|
||||
};
|
||||
|
||||
type SplitResponse = {
|
||||
@@ -57,7 +56,7 @@ const strIsMdTable = (str: string) => {
|
||||
return true;
|
||||
};
|
||||
const markdownTableSplit = (props: SplitProps): SplitResponse => {
|
||||
let { text = '', chunkSize } = props;
|
||||
let { text = '', chunkLen } = props;
|
||||
const splitText2Lines = text.split('\n');
|
||||
const header = splitText2Lines[0];
|
||||
const headerSize = header.split('|').length - 2;
|
||||
@@ -73,7 +72,7 @@ ${mdSplitString}
|
||||
`;
|
||||
|
||||
for (let i = 2; i < splitText2Lines.length; i++) {
|
||||
if (chunk.length + splitText2Lines[i].length > chunkSize * 1.2) {
|
||||
if (chunk.length + splitText2Lines[i].length > chunkLen * 1.2) {
|
||||
chunks.push(chunk);
|
||||
chunk = `${header}
|
||||
${mdSplitString}
|
||||
@@ -100,17 +99,11 @@ ${mdSplitString}
|
||||
5. 标点分割:重叠
|
||||
*/
|
||||
const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
let {
|
||||
text = '',
|
||||
chunkSize,
|
||||
maxSize = defaultMaxChunkSize,
|
||||
overlapRatio = 0.15,
|
||||
customReg = []
|
||||
} = props;
|
||||
let { text = '', chunkLen, overlapRatio = 0.15, customReg = [] } = props;
|
||||
|
||||
const splitMarker = 'SPLIT_HERE_SPLIT_HERE';
|
||||
const codeBlockMarker = 'CODE_BLOCK_LINE_MARKER';
|
||||
const overlapLen = Math.round(chunkSize * overlapRatio);
|
||||
const overlapLen = Math.round(chunkLen * overlapRatio);
|
||||
|
||||
// replace code block all \n to codeBlockMarker
|
||||
text = text.replace(/(```[\s\S]*?```|~~~[\s\S]*?~~~)/g, function (match) {
|
||||
@@ -122,38 +115,34 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
// The larger maxLen is, the next sentence is less likely to trigger splitting
|
||||
const markdownIndex = 4;
|
||||
const forbidOverlapIndex = 8;
|
||||
|
||||
const stepReges: { reg: RegExp | string; maxLen: number }[] = [
|
||||
const stepReges: { reg: RegExp; maxLen: number }[] = [
|
||||
...customReg.map((text) => ({
|
||||
reg: text.replaceAll('\\n', '\n'),
|
||||
maxLen: chunkSize
|
||||
reg: new RegExp(`(${replaceRegChars(text)})`, 'g'),
|
||||
maxLen: chunkLen * 1.4
|
||||
})),
|
||||
{ reg: /^(#\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(##\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(###\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(####\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(#####\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(#\s[^\n]+\n)/gm, maxLen: chunkLen * 1.2 },
|
||||
{ reg: /^(##\s[^\n]+\n)/gm, maxLen: chunkLen * 1.4 },
|
||||
{ reg: /^(###\s[^\n]+\n)/gm, maxLen: chunkLen * 1.6 },
|
||||
{ reg: /^(####\s[^\n]+\n)/gm, maxLen: chunkLen * 1.8 },
|
||||
{ reg: /^(#####\s[^\n]+\n)/gm, maxLen: chunkLen * 1.8 },
|
||||
|
||||
{ reg: /([\n](```[\s\S]*?```|~~~[\s\S]*?~~~))/g, maxLen: maxSize }, // code block
|
||||
{
|
||||
reg: /(\n\|(?:(?:[^\n|]+\|){1,})\n\|(?:[:\-\s]+\|){1,}\n(?:\|(?:[^\n|]+\|)*\n)*)/g,
|
||||
maxLen: maxSize
|
||||
}, // Table 尽可能保证完整性
|
||||
{ reg: /(\n{2,})/g, maxLen: chunkSize },
|
||||
{ reg: /([\n])/g, maxLen: chunkSize },
|
||||
{ reg: /([\n]([`~]))/g, maxLen: chunkLen * 4 }, // code block
|
||||
{ reg: /([\n](?=\s*[0-9]+\.))/g, maxLen: chunkLen * 2 }, // 增大块,尽可能保证它是一个完整的段落。 (?![\*\-|>`0-9]): markdown special char
|
||||
{ reg: /(\n{2,})/g, maxLen: chunkLen * 1.6 },
|
||||
{ reg: /([\n])/g, maxLen: chunkLen * 1.2 },
|
||||
// ------ There's no overlap on the top
|
||||
{ reg: /([。]|([a-zA-Z])\.\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([!]|!\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([?]|\?\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([;]|;\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([,]|,\s)/g, maxLen: chunkSize }
|
||||
{ reg: /([。]|([a-zA-Z])\.\s)/g, maxLen: chunkLen * 1.2 },
|
||||
{ reg: /([!]|!\s)/g, maxLen: chunkLen * 1.2 },
|
||||
{ reg: /([?]|\?\s)/g, maxLen: chunkLen * 1.4 },
|
||||
{ reg: /([;]|;\s)/g, maxLen: chunkLen * 1.6 },
|
||||
{ reg: /([,]|,\s)/g, maxLen: chunkLen * 2 }
|
||||
];
|
||||
|
||||
const customRegLen = customReg.length;
|
||||
const checkIsCustomStep = (step: number) => step < customRegLen;
|
||||
const checkIsMarkdownSplit = (step: number) =>
|
||||
step >= customRegLen && step <= markdownIndex + customRegLen;
|
||||
|
||||
+customReg.length;
|
||||
const checkForbidOverlap = (step: number) => step <= forbidOverlapIndex + customRegLen;
|
||||
|
||||
// if use markdown title split, Separate record title
|
||||
@@ -162,8 +151,7 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
return [
|
||||
{
|
||||
text,
|
||||
title: '',
|
||||
chunkMaxSize: chunkSize
|
||||
title: ''
|
||||
}
|
||||
];
|
||||
}
|
||||
@@ -171,46 +159,27 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
const isCustomStep = checkIsCustomStep(step);
|
||||
const isMarkdownSplit = checkIsMarkdownSplit(step);
|
||||
|
||||
const { reg, maxLen } = stepReges[step];
|
||||
const { reg } = stepReges[step];
|
||||
|
||||
const replaceText = (() => {
|
||||
if (typeof reg === 'string') {
|
||||
let tmpText = text;
|
||||
reg.split('|').forEach((itemReg) => {
|
||||
tmpText = tmpText.replaceAll(
|
||||
itemReg,
|
||||
(() => {
|
||||
if (isCustomStep) return splitMarker;
|
||||
if (isMarkdownSplit) return `${splitMarker}$1`;
|
||||
return `$1${splitMarker}`;
|
||||
})()
|
||||
);
|
||||
});
|
||||
return tmpText;
|
||||
}
|
||||
|
||||
return text.replace(
|
||||
const splitTexts = text
|
||||
.replace(
|
||||
reg,
|
||||
(() => {
|
||||
if (isCustomStep) return splitMarker;
|
||||
if (isMarkdownSplit) return `${splitMarker}$1`;
|
||||
return `$1${splitMarker}`;
|
||||
})()
|
||||
);
|
||||
})();
|
||||
|
||||
const splitTexts = replaceText.split(splitMarker).filter((part) => part.trim());
|
||||
)
|
||||
.split(`${splitMarker}`)
|
||||
.filter((part) => part.trim());
|
||||
|
||||
return splitTexts
|
||||
.map((text) => {
|
||||
const matchTitle = isMarkdownSplit ? text.match(reg)?.[0] || '' : '';
|
||||
// 如果一个分块没有匹配到,则使用默认块大小,否则使用最大块大小
|
||||
const chunkMaxSize = text.match(reg) === null ? chunkSize : maxLen;
|
||||
|
||||
return {
|
||||
text: isMarkdownSplit ? text.replace(matchTitle, '') : text,
|
||||
title: matchTitle,
|
||||
chunkMaxSize
|
||||
title: matchTitle
|
||||
};
|
||||
})
|
||||
.filter((item) => !!item.title || !!item.text?.trim());
|
||||
@@ -219,7 +188,7 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
/* Gets the overlap at the end of a text as the beginning of the next block */
|
||||
const getOneTextOverlapText = ({ text, step }: { text: string; step: number }): string => {
|
||||
const forbidOverlap = checkForbidOverlap(step);
|
||||
const maxOverlapLen = chunkSize * 0.4;
|
||||
const maxOverlapLen = chunkLen * 0.4;
|
||||
|
||||
// step >= stepReges.length: Do not overlap incomplete sentences
|
||||
if (forbidOverlap || overlapLen === 0 || step >= stepReges.length) return '';
|
||||
@@ -260,15 +229,15 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
const isCustomStep = checkIsCustomStep(step);
|
||||
const forbidConcat = isCustomStep; // forbid=true时候,lastText肯定为空
|
||||
|
||||
// Over step
|
||||
// oversize
|
||||
if (step >= stepReges.length) {
|
||||
if (text.length < maxSize) {
|
||||
if (text.length < chunkLen * 3) {
|
||||
return [text];
|
||||
}
|
||||
// use slice-chunkSize to split text
|
||||
// use slice-chunkLen to split text
|
||||
const chunks: string[] = [];
|
||||
for (let i = 0; i < text.length; i += chunkSize - overlapLen) {
|
||||
chunks.push(text.slice(i, i + chunkSize));
|
||||
for (let i = 0; i < text.length; i += chunkLen - overlapLen) {
|
||||
chunks.push(text.slice(i, i + chunkLen));
|
||||
}
|
||||
return chunks;
|
||||
}
|
||||
@@ -276,18 +245,19 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
// split text by special char
|
||||
const splitTexts = getSplitTexts({ text, step });
|
||||
|
||||
const maxLen = splitTexts.length > 1 ? stepReges[step].maxLen : chunkLen;
|
||||
const minChunkLen = chunkLen * 0.7;
|
||||
|
||||
const chunks: string[] = [];
|
||||
for (let i = 0; i < splitTexts.length; i++) {
|
||||
const item = splitTexts[i];
|
||||
|
||||
const maxLen = item.chunkMaxSize; // 当前块最大长度
|
||||
|
||||
const lastTextLen = lastText.length;
|
||||
const currentText = item.text;
|
||||
const newText = lastText + currentText;
|
||||
const newTextLen = newText.length;
|
||||
|
||||
// Markdown 模式下,会强制向下拆分最小块,并再最后一个标题深度,给小块都补充上所有标题(包含父级标题)
|
||||
// Markdown 模式下,会强制向下拆分最小块,并再最后一个标题时候,给小块都补充上所有标题(包含父级标题)
|
||||
if (isMarkdownStep) {
|
||||
// split new Text, split chunks must will greater 1 (small lastText)
|
||||
const innerChunks = splitTextRecursively({
|
||||
@@ -297,13 +267,11 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
parentTitle: parentTitle + item.title
|
||||
});
|
||||
|
||||
// 只有标题,没有内容。
|
||||
if (innerChunks.length === 0) {
|
||||
chunks.push(`${parentTitle}${item.title}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
// 在合并最深级标题时,需要补充标题
|
||||
chunks.push(
|
||||
...innerChunks.map(
|
||||
(chunk) =>
|
||||
@@ -314,18 +282,9 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
continue;
|
||||
}
|
||||
|
||||
// newText is too large(now, The lastText must be smaller than chunkSize)
|
||||
// newText is too large(now, The lastText must be smaller than chunkLen)
|
||||
if (newTextLen > maxLen) {
|
||||
const minChunkLen = maxLen * 0.8; // 当前块最小长度
|
||||
const maxChunkLen = maxLen * 1.2; // 当前块最大长度
|
||||
|
||||
// 新文本没有非常大,直接认为它是一个新的块
|
||||
if (newTextLen < maxChunkLen) {
|
||||
chunks.push(newText);
|
||||
lastText = getOneTextOverlapText({ text: newText, step }); // next chunk will start with overlayText
|
||||
continue;
|
||||
}
|
||||
// 上一个文本块已经挺大的,单独做一个块
|
||||
// lastText greater minChunkLen, direct push it to chunks, not add to next chunk. (large lastText)
|
||||
if (lastTextLen > minChunkLen) {
|
||||
chunks.push(lastText);
|
||||
|
||||
@@ -335,13 +294,13 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
continue;
|
||||
}
|
||||
|
||||
// 说明是当前文本比较大,需要进一步拆分
|
||||
// 说明是新的文本块比较大,需要进一步拆分
|
||||
|
||||
// 把新的文本块进行一个拆分,并追加到 latestText 中
|
||||
// split new Text, split chunks must will greater 1 (small lastText)
|
||||
const innerChunks = splitTextRecursively({
|
||||
text: currentText,
|
||||
text: newText,
|
||||
step: step + 1,
|
||||
lastText,
|
||||
lastText: '',
|
||||
parentTitle: parentTitle + item.title
|
||||
});
|
||||
const lastChunk = innerChunks[innerChunks.length - 1];
|
||||
@@ -369,16 +328,16 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
|
||||
// Not overlap
|
||||
if (forbidConcat) {
|
||||
chunks.push(currentText);
|
||||
chunks.push(item.text);
|
||||
continue;
|
||||
}
|
||||
|
||||
lastText = newText;
|
||||
lastText += item.text;
|
||||
}
|
||||
|
||||
/* If the last chunk is independent, it needs to be push chunks. */
|
||||
if (lastText && chunks[chunks.length - 1] && !chunks[chunks.length - 1].endsWith(lastText)) {
|
||||
if (lastText.length < chunkSize * 0.4) {
|
||||
if (lastText.length < chunkLen * 0.4) {
|
||||
chunks[chunks.length - 1] = chunks[chunks.length - 1] + lastText;
|
||||
} else {
|
||||
chunks.push(lastText);
|
||||
@@ -412,9 +371,9 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
|
||||
/**
|
||||
* text split into chunks
|
||||
* chunkSize - one chunk len. max: 3500
|
||||
* chunkLen - one chunk len. max: 3500
|
||||
* overlapLen - The size of the before and after Text
|
||||
* chunkSize > overlapLen
|
||||
* chunkLen > overlapLen
|
||||
* markdown
|
||||
*/
|
||||
export const splitText2Chunks = (props: SplitProps): SplitResponse => {
|
||||
|
||||
@@ -56,7 +56,7 @@ export const replaceSensitiveText = (text: string) => {
|
||||
};
|
||||
|
||||
/* Make sure the first letter is definitely lowercase */
|
||||
export const getNanoid = (size = 16) => {
|
||||
export const getNanoid = (size = 12) => {
|
||||
const firstChar = customAlphabet('abcdefghijklmnopqrstuvwxyz', 1)();
|
||||
|
||||
if (size === 1) return firstChar;
|
||||
|
||||
@@ -6,7 +6,7 @@ import type {
|
||||
EmbeddingModelItemType,
|
||||
AudioSpeechModels,
|
||||
STTModelType,
|
||||
RerankModelItemType
|
||||
ReRankModelItemType
|
||||
} from '../../../core/ai/model.d';
|
||||
import { SubTypeEnum } from '../../../support/wallet/sub/constants';
|
||||
|
||||
@@ -35,7 +35,7 @@ export type FastGPTConfigFileType = {
|
||||
// Abandon
|
||||
llmModels?: ChatModelItemType[];
|
||||
vectorModels?: EmbeddingModelItemType[];
|
||||
reRankModels?: RerankModelItemType[];
|
||||
reRankModels?: ReRankModelItemType[];
|
||||
audioSpeechModels?: TTSModelType[];
|
||||
whisperModel?: STTModelType;
|
||||
};
|
||||
@@ -84,6 +84,11 @@ export type FastGPTFeConfigsType = {
|
||||
github?: string;
|
||||
google?: string;
|
||||
wechat?: string;
|
||||
dingtalk?: string;
|
||||
wecom?: {
|
||||
corpid?: string;
|
||||
agentid?: string;
|
||||
};
|
||||
microsoft?: {
|
||||
clientId?: string;
|
||||
tenantId?: string;
|
||||
|
||||
2
packages/global/core/ai/model.d.ts
vendored
@@ -72,7 +72,7 @@ export type EmbeddingModelItemType = PriceType &
|
||||
queryConfig?: Record<string, any>; // Custom parameters for query
|
||||
};
|
||||
|
||||
export type RerankModelItemType = PriceType &
|
||||
export type ReRankModelItemType = PriceType &
|
||||
BaseModelItemType & {
|
||||
type: ModelTypeEnum.rerank;
|
||||
};
|
||||
|
||||
@@ -1,70 +1,54 @@
|
||||
import { PromptTemplateItem } from '../type.d';
|
||||
import { i18nT } from '../../../../web/i18n/utils';
|
||||
import { getPromptByVersion } from './utils';
|
||||
|
||||
export const Prompt_QuoteTemplateList: PromptTemplateItem[] = [
|
||||
{
|
||||
title: i18nT('app:template.standard_template'),
|
||||
desc: i18nT('app:template.standard_template_des'),
|
||||
value: {
|
||||
['4.9.2']: `{
|
||||
value: `{
|
||||
"sourceName": "{{source}}",
|
||||
"updateTime": "{{updateTime}}",
|
||||
"content": "{{q}}\n{{a}}"
|
||||
}
|
||||
`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.qa_template'),
|
||||
desc: i18nT('app:template.qa_template_des'),
|
||||
value: {
|
||||
['4.9.2']: `<Question>
|
||||
value: `<Question>
|
||||
{{q}}
|
||||
</Question>
|
||||
<Answer>
|
||||
{{a}}
|
||||
</Answer>`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.standard_strict'),
|
||||
desc: i18nT('app:template.standard_strict_des'),
|
||||
value: {
|
||||
['4.9.2']: `{
|
||||
value: `{
|
||||
"sourceName": "{{source}}",
|
||||
"updateTime": "{{updateTime}}",
|
||||
"content": "{{q}}\n{{a}}"
|
||||
}
|
||||
`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.hard_strict'),
|
||||
desc: i18nT('app:template.hard_strict_des'),
|
||||
value: {
|
||||
['4.9.2']: `<Question>
|
||||
value: `<Question>
|
||||
{{q}}
|
||||
</Question>
|
||||
<Answer>
|
||||
{{a}}
|
||||
</Answer>`
|
||||
}
|
||||
}
|
||||
];
|
||||
|
||||
export const getQuoteTemplate = (version?: string) => {
|
||||
const defaultTemplate = Prompt_QuoteTemplateList[0].value;
|
||||
|
||||
return getPromptByVersion(version, defaultTemplate);
|
||||
};
|
||||
|
||||
export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
{
|
||||
title: i18nT('app:template.standard_template'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -78,13 +62,11 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 使用与问题相同的语言回答。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.qa_template'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -97,13 +79,11 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.standard_strict'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -121,13 +101,11 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 使用与问题相同的语言回答。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.hard_strict'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -148,7 +126,6 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 使用与问题相同的语言回答。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
}
|
||||
];
|
||||
|
||||
@@ -156,8 +133,7 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
{
|
||||
title: i18nT('app:template.standard_template'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -169,13 +145,11 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 保持答案与 <Reference></Reference> 中描述的一致。
|
||||
- 使用 Markdown 语法优化回答格式。
|
||||
- 使用与问题相同的语言回答。`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.qa_template'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -186,13 +160,11 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 回答的内容应尽可能与 <答案></答案> 中的内容一致。
|
||||
- 如果没有相关的问答对,你需要澄清。
|
||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.standard_strict'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -208,13 +180,11 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 保持答案与 <Reference></Reference> 中描述的一致。
|
||||
- 使用 Markdown 语法优化回答格式。
|
||||
- 使用与问题相同的语言回答。`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.hard_strict'),
|
||||
desc: '',
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -233,28 +203,12 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
||||
- 使用 Markdown 语法优化回答格式。
|
||||
- 使用与问题相同的语言回答。`
|
||||
}
|
||||
}
|
||||
];
|
||||
|
||||
export const getQuotePrompt = (version?: string, role: 'user' | 'system' = 'user') => {
|
||||
const quotePromptTemplates =
|
||||
role === 'user' ? Prompt_userQuotePromptList : Prompt_systemQuotePromptList;
|
||||
|
||||
const defaultTemplate = quotePromptTemplates[0].value;
|
||||
|
||||
return getPromptByVersion(version, defaultTemplate);
|
||||
};
|
||||
|
||||
// Document quote prompt
|
||||
export const getDocumentQuotePrompt = (version: string) => {
|
||||
const promptMap = {
|
||||
['4.9.2']: `将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
|
||||
<FilesContent>
|
||||
{{quote}}
|
||||
</FilesContent>
|
||||
`
|
||||
};
|
||||
|
||||
return getPromptByVersion(version, promptMap);
|
||||
};
|
||||
export const Prompt_DocumentQuote = `将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
|
||||
<FilesContent>
|
||||
{{quote}}
|
||||
</FilesContent>
|
||||
`;
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
import { getPromptByVersion } from './utils';
|
||||
|
||||
export const Prompt_AgentQA = {
|
||||
description: `<Context></Context> 标记中是一段文本,学习和分析它,并整理学习成果:
|
||||
- 提出问题并给出每个问题的答案。
|
||||
@@ -27,9 +25,7 @@ A2:
|
||||
`
|
||||
};
|
||||
|
||||
export const getExtractJsonPrompt = (version?: string) => {
|
||||
const promptMap: Record<string, string> = {
|
||||
['4.9.2']: `你可以从 <对话记录></对话记录> 中提取指定 Json 信息,你仅需返回 Json 字符串,无需回答问题。
|
||||
export const Prompt_ExtractJson = `你可以从 <对话记录></对话记录> 中提取指定 Json 信息,你仅需返回 Json 字符串,无需回答问题。
|
||||
<提取要求>
|
||||
{{description}}
|
||||
</提取要求>
|
||||
@@ -48,31 +44,9 @@ export const getExtractJsonPrompt = (version?: string) => {
|
||||
{{text}}
|
||||
</对话记录>
|
||||
|
||||
提取的 json 字符串:`
|
||||
};
|
||||
提取的 json 字符串:`;
|
||||
|
||||
return getPromptByVersion(version, promptMap);
|
||||
};
|
||||
|
||||
export const getExtractJsonToolPrompt = (version?: string) => {
|
||||
const promptMap: Record<string, string> = {
|
||||
['4.9.2']: `我正在执行一个函数,需要你提供一些参数,请以 JSON 字符串格式返回这些参数,要求:
|
||||
"""
|
||||
- {{description}}
|
||||
- 不是每个参数都是必须生成的,如果没有合适的参数值,不要生成该参数,或返回空字符串。
|
||||
- 需要结合前面的对话内容,一起生成合适的参数。
|
||||
"""
|
||||
|
||||
本次输入内容: """{{content}}"""
|
||||
`
|
||||
};
|
||||
|
||||
return getPromptByVersion(version, promptMap);
|
||||
};
|
||||
|
||||
export const getCQPrompt = (version?: string) => {
|
||||
const promptMap: Record<string, string> = {
|
||||
['4.9.2']: `请帮我执行一个"问题分类"任务,将问题分类为以下几种类型之一:
|
||||
export const Prompt_CQJson = `请帮我执行一个“问题分类”任务,将问题分类为以下几种类型之一:
|
||||
|
||||
"""
|
||||
{{typeList}}
|
||||
@@ -90,13 +64,9 @@ export const getCQPrompt = (version?: string) => {
|
||||
|
||||
问题:"{{question}}"
|
||||
类型ID=
|
||||
`
|
||||
};
|
||||
`;
|
||||
|
||||
return getPromptByVersion(version, promptMap);
|
||||
};
|
||||
|
||||
export const QuestionGuidePrompt = `You are an AI assistant tasked with predicting the user's next question based on the conversation history. Your goal is to generate 3 potential questions that will guide the user to continue the conversation. When generating these questions, adhere to the following rules:
|
||||
export const PROMPT_QUESTION_GUIDE = `You are an AI assistant tasked with predicting the user's next question based on the conversation history. Your goal is to generate 3 potential questions that will guide the user to continue the conversation. When generating these questions, adhere to the following rules:
|
||||
|
||||
1. Use the same language as the user's last question in the conversation history.
|
||||
2. Keep each question under 20 characters in length.
|
||||
@@ -104,5 +74,4 @@ export const QuestionGuidePrompt = `You are an AI assistant tasked with predicti
|
||||
Analyze the conversation history provided to you and use it as context to generate relevant and engaging follow-up questions. Your predictions should be logical extensions of the current topic or related areas that the user might be interested in exploring further.
|
||||
|
||||
Remember to maintain consistency in tone and style with the existing conversation while providing diverse options for the user to choose from. Your goal is to keep the conversation flowing naturally and help the user delve deeper into the subject matter or explore related topics.`;
|
||||
|
||||
export const QuestionGuideFooterPrompt = `Please strictly follow the format rules: \nReturn questions in JSON format: ['Question 1', 'Question 2', 'Question 3']. Your output: `;
|
||||
export const PROMPT_QUESTION_GUIDE_FOOTER = `Please strictly follow the format rules: \nReturn questions in JSON format: ['Question 1', 'Question 2', 'Question 3']. Your output: `;
|
||||
|
||||
@@ -1,19 +0,0 @@
|
||||
export const getPromptByVersion = (version?: string, promptMap: Record<string, string> = {}) => {
|
||||
const versions = Object.keys(promptMap).sort((a, b) => {
|
||||
const [majorA, minorA, patchA] = a.split('.').map(Number);
|
||||
const [majorB, minorB, patchB] = b.split('.').map(Number);
|
||||
|
||||
if (majorA !== majorB) return majorB - majorA;
|
||||
if (minorA !== minorB) return minorB - minorA;
|
||||
return patchB - patchA;
|
||||
});
|
||||
|
||||
if (!version) {
|
||||
return promptMap[versions[0]];
|
||||
}
|
||||
|
||||
if (version in promptMap) {
|
||||
return promptMap[version];
|
||||
}
|
||||
return promptMap[versions[versions.length - 1]];
|
||||
};
|
||||
2
packages/global/core/ai/type.d.ts
vendored
@@ -80,5 +80,5 @@ export * from 'openai';
|
||||
export type PromptTemplateItem = {
|
||||
title: string;
|
||||
desc: string;
|
||||
value: Record<string, string>;
|
||||
value: string;
|
||||
};
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
import { PROMPT_QUESTION_GUIDE } from '../ai/prompt/agent';
|
||||
import {
|
||||
AppTTSConfigType,
|
||||
AppFileSelectConfigType,
|
||||
|
||||
23
packages/global/core/app/type.d.ts
vendored
@@ -71,20 +71,6 @@ export type AppDetailType = AppSchema & {
|
||||
permission: AppPermission;
|
||||
};
|
||||
|
||||
export type AppDatasetSearchParamsType = {
|
||||
searchMode: `${DatasetSearchModeEnum}`;
|
||||
limit?: number; // limit max tokens
|
||||
similarity?: number;
|
||||
embeddingWeight?: number; // embedding weight, fullText weight = 1 - embeddingWeight
|
||||
|
||||
usingReRank?: boolean;
|
||||
rerankModel?: string;
|
||||
rerankWeight?: number;
|
||||
|
||||
datasetSearchUsingExtensionQuery?: boolean;
|
||||
datasetSearchExtensionModel?: string;
|
||||
datasetSearchExtensionBg?: string;
|
||||
};
|
||||
export type AppSimpleEditFormType = {
|
||||
// templateId: string;
|
||||
aiSettings: {
|
||||
@@ -102,7 +88,14 @@ export type AppSimpleEditFormType = {
|
||||
};
|
||||
dataset: {
|
||||
datasets: SelectedDatasetType;
|
||||
} & AppDatasetSearchParamsType;
|
||||
searchMode: `${DatasetSearchModeEnum}`;
|
||||
similarity?: number;
|
||||
limit?: number;
|
||||
usingReRank?: boolean;
|
||||
datasetSearchUsingExtensionQuery?: boolean;
|
||||
datasetSearchExtensionModel?: string;
|
||||
datasetSearchExtensionBg?: string;
|
||||
};
|
||||
selectedTools: FlowNodeTemplateType[];
|
||||
chatConfig: AppChatConfigType;
|
||||
};
|
||||
|
||||
@@ -24,11 +24,9 @@ export const getDefaultAppForm = (): AppSimpleEditFormType => {
|
||||
dataset: {
|
||||
datasets: [],
|
||||
similarity: 0.4,
|
||||
limit: 3000,
|
||||
limit: 1500,
|
||||
searchMode: DatasetSearchModeEnum.embedding,
|
||||
usingReRank: false,
|
||||
rerankModel: '',
|
||||
rerankWeight: 0.5,
|
||||
datasetSearchUsingExtensionQuery: true,
|
||||
datasetSearchExtensionBg: ''
|
||||
},
|
||||
@@ -108,24 +106,10 @@ export const appWorkflow2Form = ({
|
||||
defaultAppForm.dataset.searchMode =
|
||||
findInputValueByKey(node.inputs, NodeInputKeyEnum.datasetSearchMode) ||
|
||||
DatasetSearchModeEnum.embedding;
|
||||
defaultAppForm.dataset.embeddingWeight = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchEmbeddingWeight
|
||||
);
|
||||
// Rerank
|
||||
defaultAppForm.dataset.usingReRank = !!findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchUsingReRank
|
||||
);
|
||||
defaultAppForm.dataset.rerankModel = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchRerankModel
|
||||
);
|
||||
defaultAppForm.dataset.rerankWeight = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchRerankWeight
|
||||
);
|
||||
// Query extension
|
||||
defaultAppForm.dataset.datasetSearchUsingExtensionQuery = findInputValueByKey(
|
||||
node.inputs,
|
||||
NodeInputKeyEnum.datasetSearchUsingExtensionQuery
|
||||
|
||||
13
packages/global/core/dataset/api.d.ts
vendored
@@ -1,10 +1,5 @@
|
||||
import { DatasetDataIndexItemType, DatasetSchemaType } from './type';
|
||||
import {
|
||||
DatasetCollectionTypeEnum,
|
||||
DatasetCollectionDataProcessModeEnum,
|
||||
ChunkSettingModeEnum,
|
||||
DataChunkSplitModeEnum
|
||||
} from './constants';
|
||||
import { DatasetCollectionTypeEnum, DatasetCollectionDataProcessModeEnum } from './constants';
|
||||
import type { LLMModelItemType } from '../ai/model.d';
|
||||
import { ParentIdType } from 'common/parentFolder/type';
|
||||
|
||||
@@ -38,13 +33,7 @@ export type DatasetCollectionChunkMetadataType = {
|
||||
trainingType?: DatasetCollectionDataProcessModeEnum;
|
||||
imageIndex?: boolean;
|
||||
autoIndexes?: boolean;
|
||||
|
||||
chunkSettingMode?: ChunkSettingModeEnum;
|
||||
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||
|
||||
chunkSize?: number;
|
||||
indexSize?: number;
|
||||
|
||||
chunkSplitter?: string;
|
||||
qaPrompt?: string;
|
||||
metadata?: Record<string, any>;
|
||||
|
||||
8
packages/global/core/dataset/apiDataset.d.ts
vendored
@@ -1,5 +1,3 @@
|
||||
import { RequireOnlyOne } from '../../common/type/utils';
|
||||
|
||||
export type APIFileItem = {
|
||||
id: string;
|
||||
parentId: string | null;
|
||||
@@ -17,9 +15,9 @@ export type APIFileServer = {
|
||||
|
||||
export type APIFileListResponse = APIFileItem[];
|
||||
|
||||
export type ApiFileReadContentResponse = {
|
||||
title?: string;
|
||||
rawText: string;
|
||||
export type APIFileContentResponse = {
|
||||
content?: string;
|
||||
previewUrl?: string;
|
||||
};
|
||||
|
||||
export type APIFileReadResponse = {
|
||||
|
||||
@@ -16,7 +16,3 @@ export const getCollectionSourceData = (collection?: DatasetCollectionSchemaType
|
||||
export const checkCollectionIsFolder = (type: DatasetCollectionTypeEnum) => {
|
||||
return type === DatasetCollectionTypeEnum.folder || type === DatasetCollectionTypeEnum.virtual;
|
||||
};
|
||||
|
||||
export const collectionCanSync = (type: DatasetCollectionTypeEnum) => {
|
||||
return [DatasetCollectionTypeEnum.link, DatasetCollectionTypeEnum.apiFile].includes(type);
|
||||
};
|
||||
|
||||
@@ -13,38 +13,38 @@ export enum DatasetTypeEnum {
|
||||
export const DatasetTypeMap = {
|
||||
[DatasetTypeEnum.folder]: {
|
||||
icon: 'common/folderFill',
|
||||
label: i18nT('dataset:folder_dataset'),
|
||||
collectionLabel: i18nT('common:Folder')
|
||||
label: 'folder_dataset',
|
||||
collectionLabel: 'common.Folder'
|
||||
},
|
||||
[DatasetTypeEnum.dataset]: {
|
||||
icon: 'core/dataset/commonDatasetOutline',
|
||||
label: i18nT('dataset:common_dataset'),
|
||||
collectionLabel: i18nT('common:common.File')
|
||||
label: 'common_dataset',
|
||||
collectionLabel: 'common.File'
|
||||
},
|
||||
[DatasetTypeEnum.websiteDataset]: {
|
||||
icon: 'core/dataset/websiteDatasetOutline',
|
||||
label: i18nT('dataset:website_dataset'),
|
||||
collectionLabel: i18nT('common:common.Website')
|
||||
label: 'website_dataset',
|
||||
collectionLabel: 'common.Website'
|
||||
},
|
||||
[DatasetTypeEnum.externalFile]: {
|
||||
icon: 'core/dataset/externalDatasetOutline',
|
||||
label: i18nT('dataset:external_file'),
|
||||
collectionLabel: i18nT('common:common.File')
|
||||
label: 'external_file',
|
||||
collectionLabel: 'common.File'
|
||||
},
|
||||
[DatasetTypeEnum.apiDataset]: {
|
||||
icon: 'core/dataset/externalDatasetOutline',
|
||||
label: i18nT('dataset:api_file'),
|
||||
collectionLabel: i18nT('common:common.File')
|
||||
label: 'api_file',
|
||||
collectionLabel: 'common.File'
|
||||
},
|
||||
[DatasetTypeEnum.feishu]: {
|
||||
icon: 'core/dataset/feishuDatasetOutline',
|
||||
label: i18nT('dataset:feishu_dataset'),
|
||||
collectionLabel: i18nT('common:common.File')
|
||||
label: 'feishu_dataset',
|
||||
collectionLabel: 'common.File'
|
||||
},
|
||||
[DatasetTypeEnum.yuque]: {
|
||||
icon: 'core/dataset/yuqueDatasetOutline',
|
||||
label: i18nT('dataset:yuque_dataset'),
|
||||
collectionLabel: i18nT('common:common.File')
|
||||
label: 'yuque_dataset',
|
||||
collectionLabel: 'common.File'
|
||||
}
|
||||
};
|
||||
|
||||
@@ -129,16 +129,6 @@ export const DatasetCollectionDataProcessModeMap = {
|
||||
}
|
||||
};
|
||||
|
||||
export enum ChunkSettingModeEnum {
|
||||
auto = 'auto',
|
||||
custom = 'custom'
|
||||
}
|
||||
|
||||
export enum DataChunkSplitModeEnum {
|
||||
size = 'size',
|
||||
char = 'char'
|
||||
}
|
||||
|
||||
/* ------------ data -------------- */
|
||||
|
||||
/* ------------ training -------------- */
|
||||
@@ -195,7 +185,7 @@ export enum SearchScoreTypeEnum {
|
||||
}
|
||||
export const SearchScoreTypeMap = {
|
||||
[SearchScoreTypeEnum.embedding]: {
|
||||
label: i18nT('common:core.dataset.search.mode.embedding'),
|
||||
label: i18nT('common:core.dataset.search.score.embedding'),
|
||||
desc: i18nT('common:core.dataset.search.score.embedding desc'),
|
||||
showScore: true
|
||||
},
|
||||
|
||||
1
packages/global/core/dataset/controller.d.ts
vendored
@@ -13,7 +13,6 @@ export type CreateDatasetDataProps = {
|
||||
|
||||
export type UpdateDatasetDataProps = {
|
||||
dataId: string;
|
||||
|
||||
q?: string;
|
||||
a?: string;
|
||||
indexes?: (Omit<DatasetDataIndexItemType, 'dataId'> & {
|
||||
|
||||
@@ -15,8 +15,6 @@ export type PushDataToTrainingQueueProps = {
|
||||
vectorModel: string;
|
||||
vlmModel?: string;
|
||||
|
||||
indexSize?: number;
|
||||
|
||||
billId?: string;
|
||||
session?: ClientSession;
|
||||
};
|
||||
|
||||
@@ -1,136 +0,0 @@
|
||||
import { EmbeddingModelItemType, LLMModelItemType } from '../../../core/ai/model.d';
|
||||
import {
|
||||
ChunkSettingModeEnum,
|
||||
DataChunkSplitModeEnum,
|
||||
DatasetCollectionDataProcessModeEnum
|
||||
} from '../constants';
|
||||
|
||||
export const minChunkSize = 64; // min index and chunk size
|
||||
|
||||
// Chunk size
|
||||
export const chunkAutoChunkSize = 1500;
|
||||
export const getMaxChunkSize = (model: LLMModelItemType) => {
|
||||
return Math.max(model.maxContext - model.maxResponse, 2000);
|
||||
};
|
||||
|
||||
// QA
|
||||
export const defaultMaxChunkSize = 8000;
|
||||
export const getLLMDefaultChunkSize = (model?: LLMModelItemType) => {
|
||||
if (!model) return defaultMaxChunkSize;
|
||||
return Math.max(Math.min(model.maxContext - model.maxResponse, defaultMaxChunkSize), 2000);
|
||||
};
|
||||
|
||||
export const getLLMMaxChunkSize = (model?: LLMModelItemType) => {
|
||||
if (!model) return 8000;
|
||||
return Math.max(model.maxContext - model.maxResponse, 2000);
|
||||
};
|
||||
|
||||
// Index size
|
||||
export const getMaxIndexSize = (model?: EmbeddingModelItemType) => {
|
||||
return model?.maxToken || 512;
|
||||
};
|
||||
export const getAutoIndexSize = (model?: EmbeddingModelItemType) => {
|
||||
return model?.defaultToken || 512;
|
||||
};
|
||||
|
||||
const indexSizeSelectList = [
|
||||
{
|
||||
label: '64',
|
||||
value: 64
|
||||
},
|
||||
{
|
||||
label: '128',
|
||||
value: 128
|
||||
},
|
||||
{
|
||||
label: '256',
|
||||
value: 256
|
||||
},
|
||||
{
|
||||
label: '512',
|
||||
value: 512
|
||||
},
|
||||
{
|
||||
label: '768',
|
||||
value: 768
|
||||
},
|
||||
{
|
||||
label: '1024',
|
||||
value: 1024
|
||||
},
|
||||
{
|
||||
label: '1536',
|
||||
value: 1536
|
||||
},
|
||||
{
|
||||
label: '2048',
|
||||
value: 2048
|
||||
},
|
||||
{
|
||||
label: '3072',
|
||||
value: 3072
|
||||
},
|
||||
{
|
||||
label: '4096',
|
||||
value: 4096
|
||||
},
|
||||
{
|
||||
label: '5120',
|
||||
value: 5120
|
||||
},
|
||||
{
|
||||
label: '6144',
|
||||
value: 6144
|
||||
},
|
||||
{
|
||||
label: '7168',
|
||||
value: 7168
|
||||
},
|
||||
{
|
||||
label: '8192',
|
||||
value: 8192
|
||||
}
|
||||
];
|
||||
export const getIndexSizeSelectList = (max = 512) => {
|
||||
return indexSizeSelectList.filter((item) => item.value <= max);
|
||||
};
|
||||
|
||||
// Compute
|
||||
export const computeChunkSize = (params: {
|
||||
trainingType: DatasetCollectionDataProcessModeEnum;
|
||||
chunkSettingMode?: ChunkSettingModeEnum;
|
||||
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||
llmModel?: LLMModelItemType;
|
||||
chunkSize?: number;
|
||||
}) => {
|
||||
if (params.trainingType === DatasetCollectionDataProcessModeEnum.qa) {
|
||||
if (params.chunkSettingMode === ChunkSettingModeEnum.auto) {
|
||||
return getLLMDefaultChunkSize(params.llmModel);
|
||||
}
|
||||
} else {
|
||||
// chunk
|
||||
if (params.chunkSettingMode === ChunkSettingModeEnum.auto) {
|
||||
return chunkAutoChunkSize;
|
||||
}
|
||||
}
|
||||
|
||||
if (params.chunkSplitMode === DataChunkSplitModeEnum.char) {
|
||||
return getLLMMaxChunkSize(params.llmModel);
|
||||
}
|
||||
|
||||
return Math.min(params.chunkSize || chunkAutoChunkSize, getLLMMaxChunkSize(params.llmModel));
|
||||
};
|
||||
|
||||
export const computeChunkSplitter = (params: {
|
||||
chunkSettingMode?: ChunkSettingModeEnum;
|
||||
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||
chunkSplitter?: string;
|
||||
}) => {
|
||||
if (params.chunkSettingMode === ChunkSettingModeEnum.auto) {
|
||||
return undefined;
|
||||
}
|
||||
if (params.chunkSplitMode === DataChunkSplitModeEnum.size) {
|
||||
return undefined;
|
||||
}
|
||||
return params.chunkSplitter;
|
||||
};
|
||||
9
packages/global/core/dataset/type.d.ts
vendored
@@ -2,7 +2,6 @@ import type { LLMModelItemType, EmbeddingModelItemType } from '../../core/ai/mod
|
||||
import { PermissionTypeEnum } from '../../support/permission/constant';
|
||||
import { PushDatasetDataChunkProps } from './api';
|
||||
import {
|
||||
DataChunkSplitModeEnum,
|
||||
DatasetCollectionDataProcessModeEnum,
|
||||
DatasetCollectionTypeEnum,
|
||||
DatasetStatusEnum,
|
||||
@@ -15,7 +14,6 @@ import { Permission } from '../../support/permission/controller';
|
||||
import { APIFileServer, FeishuServer, YuqueServer } from './apiDataset';
|
||||
import { SourceMemberType } from 'support/user/type';
|
||||
import { DatasetDataIndexTypeEnum } from './data/constants';
|
||||
import { ChunkSettingModeEnum } from './constants';
|
||||
|
||||
export type DatasetSchemaType = {
|
||||
_id: string;
|
||||
@@ -90,12 +88,7 @@ export type DatasetCollectionSchemaType = {
|
||||
autoIndexes?: boolean;
|
||||
imageIndex?: boolean;
|
||||
trainingType: DatasetCollectionDataProcessModeEnum;
|
||||
|
||||
chunkSettingMode?: ChunkSettingModeEnum;
|
||||
chunkSplitMode?: DataChunkSplitModeEnum;
|
||||
|
||||
chunkSize?: number;
|
||||
indexSize?: number;
|
||||
chunkSize: number;
|
||||
chunkSplitter?: string;
|
||||
qaPrompt?: string;
|
||||
};
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
import { TrainingModeEnum, DatasetCollectionTypeEnum } from './constants';
|
||||
import { getFileIcon } from '../../common/file/icon';
|
||||
import { strIsLink } from '../../common/string/tools';
|
||||
import { DatasetDataIndexTypeEnum } from './data/constants';
|
||||
|
||||
export function getCollectionIcon(
|
||||
type: DatasetCollectionTypeEnum = DatasetCollectionTypeEnum.file,
|
||||
@@ -37,6 +38,26 @@ export function getSourceNameIcon({
|
||||
return 'file/fill/file';
|
||||
}
|
||||
|
||||
/* get dataset data default index */
|
||||
export function getDefaultIndex(props?: { q?: string; a?: string }) {
|
||||
const { q = '', a } = props || {};
|
||||
|
||||
return [
|
||||
{
|
||||
text: q,
|
||||
type: DatasetDataIndexTypeEnum.default
|
||||
},
|
||||
...(a
|
||||
? [
|
||||
{
|
||||
text: a,
|
||||
type: DatasetDataIndexTypeEnum.default
|
||||
}
|
||||
]
|
||||
: [])
|
||||
];
|
||||
}
|
||||
|
||||
export const predictDataLimitLength = (mode: TrainingModeEnum, data: any[]) => {
|
||||
if (mode === TrainingModeEnum.qa) return data.length * 20;
|
||||
if (mode === TrainingModeEnum.auto) return data.length * 5;
|
||||
|
||||
2
packages/global/core/plugin/type.d.ts
vendored
@@ -41,8 +41,6 @@ export type PluginTemplateType = PluginRuntimeType & {
|
||||
export type PluginRuntimeType = {
|
||||
id: string;
|
||||
teamId?: string;
|
||||
tmbId?: string;
|
||||
|
||||
name: string;
|
||||
avatar: string;
|
||||
showStatus?: boolean;
|
||||
|
||||
@@ -20,7 +20,6 @@ export enum WorkflowIOValueTypeEnum {
|
||||
number = 'number',
|
||||
boolean = 'boolean',
|
||||
object = 'object',
|
||||
|
||||
arrayString = 'arrayString',
|
||||
arrayNumber = 'arrayNumber',
|
||||
arrayBoolean = 'arrayBoolean',
|
||||
@@ -155,12 +154,7 @@ export enum NodeInputKeyEnum {
|
||||
datasetSimilarity = 'similarity',
|
||||
datasetMaxTokens = 'limit',
|
||||
datasetSearchMode = 'searchMode',
|
||||
datasetSearchEmbeddingWeight = 'embeddingWeight',
|
||||
|
||||
datasetSearchUsingReRank = 'usingReRank',
|
||||
datasetSearchRerankWeight = 'rerankWeight',
|
||||
datasetSearchRerankModel = 'rerankModel',
|
||||
|
||||
datasetSearchUsingExtensionQuery = 'datasetSearchUsingExtensionQuery',
|
||||
datasetSearchExtensionModel = 'datasetSearchExtensionModel',
|
||||
datasetSearchExtensionBg = 'datasetSearchExtensionBg',
|
||||
|
||||
@@ -133,9 +133,6 @@ export type DispatchNodeResponseType = {
|
||||
similarity?: number;
|
||||
limit?: number;
|
||||
searchMode?: `${DatasetSearchModeEnum}`;
|
||||
embeddingWeight?: number;
|
||||
rerankModel?: string;
|
||||
rerankWeight?: number;
|
||||
searchUsingReRank?: boolean;
|
||||
queryExtensionResult?: {
|
||||
model: string;
|
||||
|
||||
@@ -76,9 +76,16 @@ export const Input_Template_Text_Quote: FlowNodeInputItemType = {
|
||||
valueType: WorkflowIOValueTypeEnum.string
|
||||
};
|
||||
|
||||
export const Input_Template_File_Link: FlowNodeInputItemType = {
|
||||
export const Input_Template_File_Link_Prompt: FlowNodeInputItemType = {
|
||||
key: NodeInputKeyEnum.fileUrlList,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.reference, FlowNodeInputTypeEnum.input],
|
||||
label: i18nT('app:file_quote_link'),
|
||||
debugLabel: i18nT('app:file_quote_link'),
|
||||
valueType: WorkflowIOValueTypeEnum.arrayString
|
||||
};
|
||||
export const Input_Template_File_Link: FlowNodeInputItemType = {
|
||||
key: NodeInputKeyEnum.fileUrlList,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.reference],
|
||||
label: i18nT('app:workflow.user_file_input'),
|
||||
debugLabel: i18nT('app:workflow.user_file_input'),
|
||||
description: i18nT('app:workflow.user_file_input_desc'),
|
||||
|
||||
@@ -17,7 +17,7 @@ import {
|
||||
Input_Template_History,
|
||||
Input_Template_System_Prompt,
|
||||
Input_Template_UserChatInput,
|
||||
Input_Template_File_Link
|
||||
Input_Template_File_Link_Prompt
|
||||
} from '../../input';
|
||||
import { chatNodeSystemPromptTip, systemPromptTip } from '../../tip';
|
||||
import { getHandleConfig } from '../../utils';
|
||||
@@ -55,7 +55,7 @@ export const AiChatModule: FlowNodeTemplateType = {
|
||||
showStatus: true,
|
||||
isTool: true,
|
||||
courseUrl: '/docs/guide/workbench/workflow/ai_chat/',
|
||||
version: '4.9.0',
|
||||
version: '490',
|
||||
inputs: [
|
||||
Input_Template_SettingAiModel,
|
||||
// --- settings modal
|
||||
@@ -129,7 +129,7 @@ export const AiChatModule: FlowNodeTemplateType = {
|
||||
},
|
||||
Input_Template_History,
|
||||
Input_Template_Dataset_Quote,
|
||||
Input_Template_File_Link,
|
||||
Input_Template_File_Link_Prompt,
|
||||
{ ...Input_Template_UserChatInput, toolDescription: i18nT('workflow:user_question') }
|
||||
],
|
||||
outputs: [
|
||||
|
||||
@@ -30,7 +30,7 @@ export const ClassifyQuestionModule: FlowNodeTemplateType = {
|
||||
name: i18nT('workflow:question_classification'),
|
||||
intro: i18nT('workflow:intro_question_classification'),
|
||||
showStatus: true,
|
||||
version: '4.9.2',
|
||||
version: '481',
|
||||
courseUrl: '/docs/guide/workbench/workflow/question_classify/',
|
||||
inputs: [
|
||||
{
|
||||
|
||||
@@ -27,7 +27,7 @@ export const ContextExtractModule: FlowNodeTemplateType = {
|
||||
showStatus: true,
|
||||
isTool: true,
|
||||
courseUrl: '/docs/guide/workbench/workflow/content_extract/',
|
||||
version: '4.9.2',
|
||||
version: '481',
|
||||
inputs: [
|
||||
{
|
||||
...Input_Template_SelectAIModel,
|
||||
|
||||
@@ -31,7 +31,7 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
||||
showStatus: true,
|
||||
isTool: true,
|
||||
courseUrl: '/docs/guide/workbench/workflow/dataset_search/',
|
||||
version: '4.9.2',
|
||||
version: '481',
|
||||
inputs: [
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSelectList,
|
||||
@@ -64,14 +64,6 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
||||
valueType: WorkflowIOValueTypeEnum.string,
|
||||
value: DatasetSearchModeEnum.embedding
|
||||
},
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchEmbeddingWeight,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
label: '',
|
||||
valueType: WorkflowIOValueTypeEnum.number,
|
||||
value: 0.5
|
||||
},
|
||||
// Rerank
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchUsingReRank,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
@@ -79,20 +71,6 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
||||
valueType: WorkflowIOValueTypeEnum.boolean,
|
||||
value: false
|
||||
},
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchRerankModel,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
label: '',
|
||||
valueType: WorkflowIOValueTypeEnum.string
|
||||
},
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchRerankWeight,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
label: '',
|
||||
valueType: WorkflowIOValueTypeEnum.number,
|
||||
value: 0.5
|
||||
},
|
||||
// Query Extension
|
||||
{
|
||||
key: NodeInputKeyEnum.datasetSearchUsingExtensionQuery,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
@@ -113,7 +91,6 @@ export const DatasetSearchModule: FlowNodeTemplateType = {
|
||||
valueType: WorkflowIOValueTypeEnum.string,
|
||||
value: ''
|
||||
},
|
||||
|
||||
{
|
||||
key: NodeInputKeyEnum.authTmbId,
|
||||
renderTypeList: [FlowNodeInputTypeEnum.hidden],
|
||||
|
||||
@@ -23,7 +23,7 @@ export const ReadFilesNode: FlowNodeTemplateType = {
|
||||
name: i18nT('app:workflow.read_files'),
|
||||
intro: i18nT('app:workflow.read_files_tip'),
|
||||
showStatus: true,
|
||||
version: '4.9.2',
|
||||
version: '4812',
|
||||
isTool: false,
|
||||
courseUrl: '/docs/guide/course/fileinput/',
|
||||
inputs: [
|
||||
|
||||
@@ -20,7 +20,7 @@ import { chatNodeSystemPromptTip, systemPromptTip } from '../tip';
|
||||
import { LLMModelTypeEnum } from '../../../ai/constants';
|
||||
import { getHandleConfig } from '../utils';
|
||||
import { i18nT } from '../../../../../web/i18n/utils';
|
||||
import { Input_Template_File_Link } from '../input';
|
||||
import { Input_Template_File_Link_Prompt } from '../input';
|
||||
|
||||
export const ToolModule: FlowNodeTemplateType = {
|
||||
id: FlowNodeTypeEnum.tools,
|
||||
@@ -33,7 +33,7 @@ export const ToolModule: FlowNodeTemplateType = {
|
||||
intro: i18nT('workflow:template.tool_call_intro'),
|
||||
showStatus: true,
|
||||
courseUrl: '/docs/guide/workbench/workflow/tool/',
|
||||
version: '4.9.2',
|
||||
version: '4813',
|
||||
inputs: [
|
||||
{
|
||||
...Input_Template_SettingAiModel,
|
||||
@@ -97,7 +97,7 @@ export const ToolModule: FlowNodeTemplateType = {
|
||||
placeholder: chatNodeSystemPromptTip
|
||||
},
|
||||
Input_Template_History,
|
||||
Input_Template_File_Link,
|
||||
Input_Template_File_Link_Prompt,
|
||||
Input_Template_UserChatInput
|
||||
],
|
||||
outputs: [
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
"js-yaml": "^4.1.0",
|
||||
"jschardet": "3.1.1",
|
||||
"nanoid": "^5.1.3",
|
||||
"next": "14.2.25",
|
||||
"next": "14.2.21",
|
||||
"openai": "4.61.0",
|
||||
"openapi-types": "^12.1.3",
|
||||
"json5": "^2.2.3",
|
||||
|
||||
@@ -1,4 +0,0 @@
|
||||
export type GetGroupListBody = {
|
||||
searchKey?: string;
|
||||
withMembers?: boolean;
|
||||
};
|
||||
@@ -1,7 +1,6 @@
|
||||
import { TeamMemberItemType } from 'support/user/team/type';
|
||||
import { TeamPermission } from '../user/controller';
|
||||
import { GroupMemberRole } from './constant';
|
||||
import { Permission } from '../controller';
|
||||
|
||||
type MemberGroupSchemaType = {
|
||||
_id: string;
|
||||
@@ -17,28 +16,12 @@ type GroupMemberSchemaType = {
|
||||
role: `${GroupMemberRole}`;
|
||||
};
|
||||
|
||||
type MemberGroupListItemType<T extends boolean | undefined> = MemberGroupSchemaType & {
|
||||
members: T extends true
|
||||
? {
|
||||
tmbId: string;
|
||||
name: string;
|
||||
avatar: string;
|
||||
}[]
|
||||
: undefined;
|
||||
count: T extends true ? number : undefined;
|
||||
owner?: T extends true
|
||||
? {
|
||||
tmbId: string;
|
||||
name: string;
|
||||
avatar: string;
|
||||
}
|
||||
: undefined;
|
||||
permission: T extends true ? Permission : undefined;
|
||||
type MemberGroupType = MemberGroupSchemaType & {
|
||||
members: {
|
||||
tmbId: string;
|
||||
role: `${GroupMemberRole}`;
|
||||
}[]; // we can get tmb's info from other api. there is no need but only need to get tmb's id
|
||||
permission: TeamPermission;
|
||||
};
|
||||
|
||||
type GroupMemberItemType = {
|
||||
tmbId: string;
|
||||
name: string;
|
||||
avatar: string;
|
||||
role: `${GroupMemberRole}`;
|
||||
};
|
||||
type MemberGroupListType = MemberGroupType[];
|
||||
|
||||
7
packages/global/support/user/api.d.ts
vendored
@@ -1,7 +1,4 @@
|
||||
import {
|
||||
MemberGroupSchemaType,
|
||||
MemberGroupListItemType
|
||||
} from 'support/permission/memberGroup/type';
|
||||
import { MemberGroupSchemaType, MemberGroupType } from 'support/permission/memberGroup/type';
|
||||
import { OAuthEnum } from './constant';
|
||||
import { TrackRegisterParams } from './login/api';
|
||||
import { TeamMemberStatusEnum } from './team/constant';
|
||||
@@ -15,8 +12,8 @@ export type PostLoginProps = {
|
||||
|
||||
export type OauthLoginProps = {
|
||||
type: `${OAuthEnum}`;
|
||||
code: string;
|
||||
callbackUrl: string;
|
||||
props: Record<string, string>;
|
||||
} & TrackRegisterParams;
|
||||
|
||||
export type WxLoginProps = {
|
||||
|
||||
@@ -16,5 +16,7 @@ export enum OAuthEnum {
|
||||
google = 'google',
|
||||
wechat = 'wechat',
|
||||
microsoft = 'microsoft',
|
||||
dingtalk = 'dingtalk',
|
||||
wecom = 'wecom',
|
||||
sso = 'sso'
|
||||
}
|
||||
|
||||
@@ -1,12 +1,12 @@
|
||||
export type postCreateOrgData = {
|
||||
name: string;
|
||||
parentId: string;
|
||||
description?: string;
|
||||
avatar?: string;
|
||||
orgId?: string;
|
||||
};
|
||||
|
||||
export type putUpdateOrgMembersData = {
|
||||
orgId?: string;
|
||||
orgId: string;
|
||||
members: {
|
||||
tmbId: string;
|
||||
// role: `${OrgMemberRole}`;
|
||||
@@ -14,7 +14,7 @@ export type putUpdateOrgMembersData = {
|
||||
};
|
||||
|
||||
export type putUpdateOrgData = {
|
||||
orgId: string; // can not be undefined because can not uppdate root org
|
||||
orgId: string;
|
||||
name?: string;
|
||||
avatar?: string;
|
||||
description?: string;
|
||||
@@ -22,7 +22,7 @@ export type putUpdateOrgData = {
|
||||
|
||||
export type putMoveOrgType = {
|
||||
orgId: string;
|
||||
targetOrgId?: string; // '' ===> move to root org
|
||||
targetOrgId: string;
|
||||
};
|
||||
|
||||
// type putChnageOrgOwnerData = {
|
||||
|
||||
@@ -3,10 +3,7 @@ import { OrgSchemaType } from './type';
|
||||
export const OrgCollectionName = 'team_orgs';
|
||||
export const OrgMemberCollectionName = 'team_org_members';
|
||||
|
||||
export const getOrgChildrenPath = (org: OrgSchemaType) => {
|
||||
if (org.path === '' && org.pathId === '') return '';
|
||||
return `${org.path ?? ''}/${org.pathId}`;
|
||||
};
|
||||
export const getOrgChildrenPath = (org: OrgSchemaType) => `${org.path}/${org.pathId}`;
|
||||
|
||||
export enum SyncOrgSourceEnum {
|
||||
wecom = 'wecom'
|
||||
|
||||
13
packages/global/support/user/team/org/type.d.ts
vendored
@@ -1,6 +1,5 @@
|
||||
import type { TeamPermission } from '../../../permission/user/controller';
|
||||
import type { TeamPermission } from 'support/permission/user/controller';
|
||||
import { ResourcePermissionType } from '../type';
|
||||
import { SourceMemberType } from '../../type';
|
||||
|
||||
type OrgSchemaType = {
|
||||
_id: string;
|
||||
@@ -8,7 +7,7 @@ type OrgSchemaType = {
|
||||
pathId: string;
|
||||
path: string;
|
||||
name: string;
|
||||
avatar: string;
|
||||
avatar?: string;
|
||||
description?: string;
|
||||
updateTime: Date;
|
||||
};
|
||||
@@ -20,14 +19,8 @@ type OrgMemberSchemaType = {
|
||||
tmbId: string;
|
||||
};
|
||||
|
||||
export type OrgListItemType = OrgSchemaType & {
|
||||
permission?: TeamPermission;
|
||||
total: number; // members + children orgs
|
||||
};
|
||||
|
||||
export type OrgType = Omit<OrgSchemaType, 'avatar'> & {
|
||||
type OrgType = Omit<OrgSchemaType, 'avatar'> & {
|
||||
avatar: string;
|
||||
permission: TeamPermission;
|
||||
members: OrgMemberSchemaType[];
|
||||
total: number; // members + children orgs
|
||||
};
|
||||
|
||||
25
packages/global/support/user/team/type.d.ts
vendored
@@ -70,13 +70,7 @@ export type TeamTmbItemType = {
|
||||
permission: TeamPermission;
|
||||
} & ThirdPartyAccountType;
|
||||
|
||||
export type TeamMemberItemType<
|
||||
Options extends {
|
||||
withPermission?: boolean;
|
||||
withOrgs?: boolean;
|
||||
withGroupRole?: boolean;
|
||||
} = { withPermission: true; withOrgs: true; withGroupRole: false }
|
||||
> = {
|
||||
export type TeamMemberItemType = {
|
||||
userId: string;
|
||||
tmbId: string;
|
||||
teamId: string;
|
||||
@@ -84,24 +78,11 @@ export type TeamMemberItemType<
|
||||
avatar: string;
|
||||
role: `${TeamMemberRoleEnum}`;
|
||||
status: `${TeamMemberStatusEnum}`;
|
||||
permission: TeamPermission;
|
||||
contact?: string;
|
||||
createTime: Date;
|
||||
updateTime?: Date;
|
||||
} & (Options extends { withPermission: true }
|
||||
? {
|
||||
permission: TeamPermission;
|
||||
}
|
||||
: {}) &
|
||||
(Options extends { withOrgs: true }
|
||||
? {
|
||||
orgs?: string[]; // full path name, pattern: /teamName/orgname1/orgname2
|
||||
}
|
||||
: {}) &
|
||||
(Options extends { withGroupRole: true }
|
||||
? {
|
||||
groupRole?: `${GroupMemberRole}`;
|
||||
}
|
||||
: {});
|
||||
};
|
||||
|
||||
export type TeamTagItemType = {
|
||||
label: string;
|
||||
|
||||
@@ -76,7 +76,7 @@ export const refreshSourceAvatar = async (
|
||||
const newId = getIdFromPath(path);
|
||||
const oldId = getIdFromPath(oldPath);
|
||||
|
||||
if (!newId || newId === oldId) return;
|
||||
if (!newId) return;
|
||||
|
||||
await MongoImage.updateOne({ _id: newId }, { $unset: { expiredTime: 1 } }, { session });
|
||||
|
||||
|
||||
@@ -1,13 +1,4 @@
|
||||
import { Jieba } from '@node-rs/jieba';
|
||||
|
||||
let jieba: Jieba | undefined;
|
||||
|
||||
(async () => {
|
||||
const dictData = await import('./dict.json');
|
||||
// @ts-ignore
|
||||
const dictBuffer = Buffer.from(dictData.dict?.replace(/\\n/g, '\n'), 'utf-8');
|
||||
jieba = Jieba.withDict(dictBuffer);
|
||||
})();
|
||||
import { cut } from '@node-rs/jieba';
|
||||
|
||||
const stopWords = new Set([
|
||||
'--',
|
||||
@@ -1518,10 +1509,8 @@ const stopWords = new Set([
|
||||
]
|
||||
]);
|
||||
|
||||
export async function jiebaSplit({ text }: { text: string }) {
|
||||
text = text.replace(/[#*`_~>[\](){}|]/g, '').replace(/\S*https?\S*/gi, '');
|
||||
|
||||
const tokens = (await jieba!.cutAsync(text, true)) as string[];
|
||||
export function jiebaSplit({ text }: { text: string }) {
|
||||
const tokens = cut(text, true);
|
||||
|
||||
return (
|
||||
tokens
|
||||
@@ -30,8 +30,6 @@ export const isInternalAddress = (url: string): boolean => {
|
||||
return true;
|
||||
}
|
||||
|
||||
if (process.env.CHECK_INTERNAL_IP !== 'true') return false;
|
||||
|
||||
// For IP addresses, check if they are internal
|
||||
const ipv4Pattern = /^(\d{1,3}\.){3}\d{1,3}$/;
|
||||
if (!ipv4Pattern.test(hostname)) {
|
||||
|
||||
@@ -30,11 +30,11 @@ export async function text2Speech({
|
||||
response_format: 'mp3',
|
||||
speed
|
||||
},
|
||||
modelData.requestUrl
|
||||
modelData.requestUrl && modelData.requestAuth
|
||||
? {
|
||||
path: modelData.requestUrl,
|
||||
headers: {
|
||||
...(modelData.requestAuth ? { Authorization: `Bearer ${modelData.requestAuth}` } : {})
|
||||
Authorization: `Bearer ${modelData.requestAuth}`
|
||||
}
|
||||
}
|
||||
: {}
|
||||
|
||||
@@ -3,25 +3,21 @@ import { getAxiosConfig } from '../config';
|
||||
import axios from 'axios';
|
||||
import FormData from 'form-data';
|
||||
import { getSTTModel } from '../model';
|
||||
import { STTModelType } from '@fastgpt/global/core/ai/model.d';
|
||||
|
||||
export const aiTranscriptions = async ({
|
||||
model: modelData,
|
||||
model,
|
||||
fileStream,
|
||||
headers
|
||||
}: {
|
||||
model: STTModelType;
|
||||
model: string;
|
||||
fileStream: fs.ReadStream;
|
||||
headers?: Record<string, string>;
|
||||
}) => {
|
||||
if (!modelData) {
|
||||
return Promise.reject('no model');
|
||||
}
|
||||
|
||||
const data = new FormData();
|
||||
data.append('model', modelData.model);
|
||||
data.append('model', model);
|
||||
data.append('file', fileStream);
|
||||
|
||||
const modelData = getSTTModel(model);
|
||||
const aiAxiosConfig = getAxiosConfig();
|
||||
|
||||
const { data: result } = await axios<{ text: string }>({
|
||||
|
||||
@@ -8,7 +8,7 @@ import {
|
||||
EmbeddingModelItemType,
|
||||
TTSModelType,
|
||||
STTModelType,
|
||||
RerankModelItemType
|
||||
ReRankModelItemType
|
||||
} from '@fastgpt/global/core/ai/model.d';
|
||||
import { debounce } from 'lodash';
|
||||
import {
|
||||
@@ -94,7 +94,7 @@ export const loadSystemModels = async (init = false) => {
|
||||
global.embeddingModelMap = new Map<string, EmbeddingModelItemType>();
|
||||
global.ttsModelMap = new Map<string, TTSModelType>();
|
||||
global.sttModelMap = new Map<string, STTModelType>();
|
||||
global.reRankModelMap = new Map<string, RerankModelItemType>();
|
||||
global.reRankModelMap = new Map<string, ReRankModelItemType>();
|
||||
// @ts-ignore
|
||||
global.systemDefaultModel = {};
|
||||
|
||||
|
||||
@@ -4,8 +4,8 @@ import { countGptMessagesTokens, countPromptTokens } from '../../../common/strin
|
||||
import { loadRequestMessages } from '../../chat/utils';
|
||||
import { llmCompletionsBodyFormat } from '../utils';
|
||||
import {
|
||||
QuestionGuidePrompt,
|
||||
QuestionGuideFooterPrompt
|
||||
PROMPT_QUESTION_GUIDE,
|
||||
PROMPT_QUESTION_GUIDE_FOOTER
|
||||
} from '@fastgpt/global/core/ai/prompt/agent';
|
||||
import { addLog } from '../../../common/system/log';
|
||||
import json5 from 'json5';
|
||||
@@ -27,7 +27,7 @@ export async function createQuestionGuide({
|
||||
...messages,
|
||||
{
|
||||
role: 'user',
|
||||
content: `${customPrompt || QuestionGuidePrompt}\n${QuestionGuideFooterPrompt}`
|
||||
content: `${customPrompt || PROMPT_QUESTION_GUIDE}\n${PROMPT_QUESTION_GUIDE_FOOTER}`
|
||||
}
|
||||
];
|
||||
const requestMessages = await loadRequestMessages({
|
||||
|
||||
@@ -38,7 +38,7 @@ export function getSTTModel(model?: string) {
|
||||
}
|
||||
|
||||
export const getDefaultRerankModel = () => global?.systemDefaultModel.rerank!;
|
||||
export function getRerankModel(model?: string) {
|
||||
export function getReRankModel(model?: string) {
|
||||
if (!model) return getDefaultRerankModel();
|
||||
return global.reRankModelMap.get(model) || getDefaultRerankModel();
|
||||
}
|
||||
|
||||
@@ -2,7 +2,7 @@ import { addLog } from '../../../common/system/log';
|
||||
import { POST } from '../../../common/api/serverRequest';
|
||||
import { getDefaultRerankModel } from '../model';
|
||||
import { getAxiosConfig } from '../config';
|
||||
import { RerankModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
import { ReRankModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
|
||||
type PostReRankResponse = {
|
||||
id: string;
|
||||
@@ -19,7 +19,7 @@ export function reRankRecall({
|
||||
documents,
|
||||
headers
|
||||
}: {
|
||||
model?: RerankModelItemType;
|
||||
model?: ReRankModelItemType;
|
||||
query: string;
|
||||
documents: { id: string; text: string }[];
|
||||
headers?: Record<string, string>;
|
||||
|
||||
8
packages/service/core/ai/type.d.ts
vendored
@@ -1,7 +1,7 @@
|
||||
import { ModelTypeEnum } from '@fastgpt/global/core/ai/model';
|
||||
import {
|
||||
STTModelType,
|
||||
RerankModelItemType,
|
||||
ReRankModelItemType,
|
||||
TTSModelType,
|
||||
EmbeddingModelItemType,
|
||||
LLMModelItemType
|
||||
@@ -18,7 +18,7 @@ export type SystemModelItemType =
|
||||
| EmbeddingModelItemType
|
||||
| TTSModelType
|
||||
| STTModelType
|
||||
| RerankModelItemType;
|
||||
| ReRankModelItemType;
|
||||
|
||||
export type SystemDefaultModelType = {
|
||||
[ModelTypeEnum.llm]?: LLMModelItemType;
|
||||
@@ -28,7 +28,7 @@ export type SystemDefaultModelType = {
|
||||
[ModelTypeEnum.embedding]?: EmbeddingModelItemType;
|
||||
[ModelTypeEnum.tts]?: TTSModelType;
|
||||
[ModelTypeEnum.stt]?: STTModelType;
|
||||
[ModelTypeEnum.rerank]?: RerankModelItemType;
|
||||
[ModelTypeEnum.rerank]?: ReRankModelItemType;
|
||||
};
|
||||
|
||||
declare global {
|
||||
@@ -38,7 +38,7 @@ declare global {
|
||||
var embeddingModelMap: Map<string, EmbeddingModelItemType>;
|
||||
var ttsModelMap: Map<string, TTSModelType>;
|
||||
var sttModelMap: Map<string, STTModelType>;
|
||||
var reRankModelMap: Map<string, RerankModelItemType>;
|
||||
var reRankModelMap: Map<string, ReRankModelItemType>;
|
||||
|
||||
var systemActiveModelList: SystemModelItemType[];
|
||||
var systemDefaultModel: SystemDefaultModelType;
|
||||
|
||||
@@ -65,7 +65,6 @@ export const llmCompletionsBodyFormat = <T extends CompletionsBodyType>(
|
||||
|
||||
const requestBody: T = {
|
||||
...body,
|
||||
model: modelData.model,
|
||||
temperature:
|
||||
typeof body.temperature === 'number'
|
||||
? computedTemperature({
|
||||
|
||||
@@ -37,12 +37,11 @@ export async function splitCombinePluginId(id: string) {
|
||||
return { source, pluginId: id };
|
||||
}
|
||||
|
||||
type ChildAppType = SystemPluginTemplateItemType & { teamId?: string; tmbId?: string };
|
||||
|
||||
type ChildAppType = SystemPluginTemplateItemType & { teamId?: string };
|
||||
const getSystemPluginTemplateById = async (
|
||||
pluginId: string,
|
||||
versionId?: string
|
||||
): Promise<ChildAppType> => {
|
||||
): Promise<SystemPluginTemplateItemType> => {
|
||||
const item = getSystemPluginTemplates().find((plugin) => plugin.id === pluginId);
|
||||
if (!item) return Promise.reject(PluginErrEnum.unAuth);
|
||||
|
||||
@@ -68,17 +67,12 @@ const getSystemPluginTemplateById = async (
|
||||
: await getAppLatestVersion(plugin.associatedPluginId, app);
|
||||
if (!version.versionId) return Promise.reject('App version not found');
|
||||
|
||||
return {
|
||||
...plugin,
|
||||
workflow: {
|
||||
nodes: version.nodes,
|
||||
edges: version.edges,
|
||||
chatConfig: version.chatConfig
|
||||
},
|
||||
version: versionId || String(version.versionId),
|
||||
teamId: String(app.teamId),
|
||||
tmbId: String(app.tmbId)
|
||||
plugin.workflow = {
|
||||
nodes: version.nodes,
|
||||
edges: version.edges,
|
||||
chatConfig: version.chatConfig
|
||||
};
|
||||
plugin.version = versionId || String(version.versionId);
|
||||
}
|
||||
return plugin;
|
||||
};
|
||||
@@ -174,7 +168,6 @@ export async function getChildAppRuntimeById(
|
||||
return {
|
||||
id: String(item._id),
|
||||
teamId: String(item.teamId),
|
||||
tmbId: String(item.tmbId),
|
||||
name: item.name,
|
||||
avatar: item.avatar,
|
||||
intro: item.intro,
|
||||
@@ -194,7 +187,6 @@ export async function getChildAppRuntimeById(
|
||||
pluginOrder: 0
|
||||
};
|
||||
} else {
|
||||
// System
|
||||
return getSystemPluginTemplateById(pluginId, versionId);
|
||||
}
|
||||
})();
|
||||
@@ -202,7 +194,6 @@ export async function getChildAppRuntimeById(
|
||||
return {
|
||||
id: app.id,
|
||||
teamId: app.teamId,
|
||||
tmbId: app.tmbId,
|
||||
name: app.name,
|
||||
avatar: app.avatar,
|
||||
showStatus: app.showStatus,
|
||||
|
||||
@@ -131,10 +131,6 @@ export async function rewriteAppWorkflowToSimple(formatNodes: StoreNodeItemType[
|
||||
if (!val) {
|
||||
input.value = [];
|
||||
} else if (Array.isArray(val)) {
|
||||
// Not rewrite reference value
|
||||
if (val.length === 2 && val.every((item) => typeof item === 'string')) {
|
||||
return;
|
||||
}
|
||||
input.value = val
|
||||
.map((dataset: { datasetId: string }) => ({
|
||||
datasetId: dataset.datasetId
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import type {
|
||||
APIFileContentResponse,
|
||||
APIFileListResponse,
|
||||
ApiFileReadContentResponse,
|
||||
APIFileReadResponse,
|
||||
APIFileServer
|
||||
} from '@fastgpt/global/core/dataset/apiDataset';
|
||||
@@ -8,7 +8,6 @@ import axios, { Method } from 'axios';
|
||||
import { addLog } from '../../../common/system/log';
|
||||
import { readFileRawTextByUrl } from '../read';
|
||||
import { ParentIdType } from '@fastgpt/global/common/parentFolder/type';
|
||||
import { RequireOnlyOne } from '@fastgpt/global/common/type/utils';
|
||||
|
||||
type ResponseDataType = {
|
||||
success: boolean;
|
||||
@@ -119,24 +118,17 @@ export const useApiDatasetRequest = ({ apiServer }: { apiServer: APIFileServer }
|
||||
tmbId: string;
|
||||
apiFileId: string;
|
||||
customPdfParse?: boolean;
|
||||
}): Promise<ApiFileReadContentResponse> => {
|
||||
const data = await request<
|
||||
{
|
||||
title?: string;
|
||||
} & RequireOnlyOne<{
|
||||
content: string;
|
||||
previewUrl: string;
|
||||
}>
|
||||
>(`/v1/file/content`, { id: apiFileId }, 'GET');
|
||||
const title = data.title;
|
||||
}) => {
|
||||
const data = await request<APIFileContentResponse>(
|
||||
`/v1/file/content`,
|
||||
{ id: apiFileId },
|
||||
'GET'
|
||||
);
|
||||
const content = data.content;
|
||||
const previewUrl = data.previewUrl;
|
||||
|
||||
if (content) {
|
||||
return {
|
||||
title,
|
||||
rawText: content
|
||||
};
|
||||
return content;
|
||||
}
|
||||
if (previewUrl) {
|
||||
const rawText = await readFileRawTextByUrl({
|
||||
@@ -146,10 +138,7 @@ export const useApiDatasetRequest = ({ apiServer }: { apiServer: APIFileServer }
|
||||
relatedId: apiFileId,
|
||||
customPdfParse
|
||||
});
|
||||
return {
|
||||
title,
|
||||
rawText
|
||||
};
|
||||
return rawText;
|
||||
}
|
||||
return Promise.reject('Invalid content type: content or previewUrl is required');
|
||||
};
|
||||
|
||||
@@ -27,11 +27,6 @@ import { addDays } from 'date-fns';
|
||||
import { MongoDatasetDataText } from '../data/dataTextSchema';
|
||||
import { retryFn } from '@fastgpt/global/common/system/utils';
|
||||
import { getTrainingModeByCollection } from './utils';
|
||||
import {
|
||||
computeChunkSize,
|
||||
computeChunkSplitter,
|
||||
getLLMMaxChunkSize
|
||||
} from '@fastgpt/global/core/dataset/training/utils';
|
||||
|
||||
export const createCollectionAndInsertData = async ({
|
||||
dataset,
|
||||
@@ -59,22 +54,18 @@ export const createCollectionAndInsertData = async ({
|
||||
|
||||
const teamId = createCollectionParams.teamId;
|
||||
const tmbId = createCollectionParams.tmbId;
|
||||
|
||||
// Set default params
|
||||
// Chunk split params
|
||||
const trainingType =
|
||||
createCollectionParams.trainingType || DatasetCollectionDataProcessModeEnum.chunk;
|
||||
const chunkSize = computeChunkSize({
|
||||
...createCollectionParams,
|
||||
trainingType,
|
||||
llmModel: getLLMModel(dataset.agentModel)
|
||||
});
|
||||
const chunkSplitter = computeChunkSplitter(createCollectionParams);
|
||||
const chunkSize = createCollectionParams.chunkSize || 512;
|
||||
const chunkSplitter = createCollectionParams.chunkSplitter;
|
||||
const qaPrompt = createCollectionParams.qaPrompt;
|
||||
const usageName = createCollectionParams.name;
|
||||
|
||||
// 1. split chunks
|
||||
const chunks = rawText2Chunks({
|
||||
rawText,
|
||||
chunkSize,
|
||||
maxSize: getLLMMaxChunkSize(getLLMModel(dataset.agentModel)),
|
||||
chunkLen: chunkSize,
|
||||
overlapRatio: trainingType === DatasetCollectionDataProcessModeEnum.chunk ? 0.2 : 0,
|
||||
customReg: chunkSplitter ? [chunkSplitter] : [],
|
||||
isQAImport
|
||||
@@ -85,7 +76,7 @@ export const createCollectionAndInsertData = async ({
|
||||
teamId,
|
||||
insertLen: predictDataLimitLength(
|
||||
getTrainingModeByCollection({
|
||||
trainingType: trainingType,
|
||||
trainingType,
|
||||
autoIndexes: createCollectionParams.autoIndexes,
|
||||
imageIndex: createCollectionParams.imageIndex
|
||||
}),
|
||||
@@ -97,9 +88,6 @@ export const createCollectionAndInsertData = async ({
|
||||
// 3. create collection
|
||||
const { _id: collectionId } = await createOneCollection({
|
||||
...createCollectionParams,
|
||||
trainingType,
|
||||
chunkSize,
|
||||
chunkSplitter,
|
||||
|
||||
hashRawText: hashStr(rawText),
|
||||
rawTextLength: rawText.length,
|
||||
@@ -123,7 +111,7 @@ export const createCollectionAndInsertData = async ({
|
||||
const { billId: newBillId } = await createTrainingUsage({
|
||||
teamId,
|
||||
tmbId,
|
||||
appName: createCollectionParams.name,
|
||||
appName: usageName,
|
||||
billSource: UsageSourceEnum.training,
|
||||
vectorModel: getEmbeddingModel(dataset.vectorModel)?.name,
|
||||
agentModel: getLLMModel(dataset.agentModel)?.name,
|
||||
@@ -142,13 +130,12 @@ export const createCollectionAndInsertData = async ({
|
||||
agentModel: dataset.agentModel,
|
||||
vectorModel: dataset.vectorModel,
|
||||
vlmModel: dataset.vlmModel,
|
||||
indexSize: createCollectionParams.indexSize,
|
||||
mode: getTrainingModeByCollection({
|
||||
trainingType: trainingType,
|
||||
trainingType,
|
||||
autoIndexes: createCollectionParams.autoIndexes,
|
||||
imageIndex: createCollectionParams.imageIndex
|
||||
}),
|
||||
prompt: createCollectionParams.qaPrompt,
|
||||
prompt: qaPrompt,
|
||||
billId: traingBillId,
|
||||
data: chunks.map((item, index) => ({
|
||||
...item,
|
||||
@@ -220,14 +207,11 @@ export async function createOneCollection({
|
||||
// Parse settings
|
||||
customPdfParse,
|
||||
imageIndex,
|
||||
autoIndexes,
|
||||
|
||||
// Chunk settings
|
||||
trainingType,
|
||||
chunkSettingMode,
|
||||
chunkSplitMode,
|
||||
chunkSize,
|
||||
indexSize,
|
||||
trainingType = DatasetCollectionDataProcessModeEnum.chunk,
|
||||
autoIndexes,
|
||||
chunkSize = 512,
|
||||
chunkSplitter,
|
||||
qaPrompt,
|
||||
|
||||
@@ -265,14 +249,11 @@ export async function createOneCollection({
|
||||
// Parse settings
|
||||
customPdfParse,
|
||||
imageIndex,
|
||||
autoIndexes,
|
||||
|
||||
// Chunk settings
|
||||
trainingType,
|
||||
chunkSettingMode,
|
||||
chunkSplitMode,
|
||||
autoIndexes,
|
||||
chunkSize,
|
||||
indexSize,
|
||||
chunkSplitter,
|
||||
qaPrompt
|
||||
}
|
||||
|
||||
@@ -3,9 +3,7 @@ const { Schema, model, models } = connectionMongo;
|
||||
import { DatasetCollectionSchemaType } from '@fastgpt/global/core/dataset/type.d';
|
||||
import {
|
||||
DatasetCollectionTypeMap,
|
||||
DatasetCollectionDataProcessModeEnum,
|
||||
ChunkSettingModeEnum,
|
||||
DataChunkSplitModeEnum
|
||||
DatasetCollectionDataProcessModeEnum
|
||||
} from '@fastgpt/global/core/dataset/constants';
|
||||
import { DatasetCollectionName } from '../schema';
|
||||
import {
|
||||
@@ -96,18 +94,11 @@ const DatasetCollectionSchema = new Schema({
|
||||
type: String,
|
||||
enum: Object.values(DatasetCollectionDataProcessModeEnum)
|
||||
},
|
||||
chunkSettingMode: {
|
||||
type: String,
|
||||
enum: Object.values(ChunkSettingModeEnum)
|
||||
chunkSize: {
|
||||
type: Number,
|
||||
required: true
|
||||
},
|
||||
chunkSplitMode: {
|
||||
type: String,
|
||||
enum: Object.values(DataChunkSplitModeEnum)
|
||||
},
|
||||
chunkSize: Number,
|
||||
chunkSplitter: String,
|
||||
|
||||
indexSize: Number,
|
||||
qaPrompt: String
|
||||
});
|
||||
|
||||
|
||||
@@ -11,6 +11,7 @@ import {
|
||||
DatasetCollectionSyncResultEnum,
|
||||
DatasetCollectionTypeEnum,
|
||||
DatasetSourceReadTypeEnum,
|
||||
DatasetTypeEnum,
|
||||
TrainingModeEnum
|
||||
} from '@fastgpt/global/core/dataset/constants';
|
||||
import { DatasetErrEnum } from '@fastgpt/global/common/error/code/dataset';
|
||||
@@ -18,7 +19,6 @@ import { readDatasetSourceRawText } from '../read';
|
||||
import { hashStr } from '@fastgpt/global/common/string/tools';
|
||||
import { mongoSessionRun } from '../../../common/mongo/sessionRun';
|
||||
import { createCollectionAndInsertData, delCollection } from './controller';
|
||||
import { collectionCanSync } from '@fastgpt/global/core/dataset/collection/utils';
|
||||
|
||||
/**
|
||||
* get all collection by top collectionId
|
||||
@@ -137,7 +137,10 @@ export const collectionTagsToTagLabel = async ({
|
||||
export const syncCollection = async (collection: CollectionWithDatasetType) => {
|
||||
const dataset = collection.dataset;
|
||||
|
||||
if (!collectionCanSync(collection.type)) {
|
||||
if (
|
||||
collection.type !== DatasetCollectionTypeEnum.link &&
|
||||
dataset.type !== DatasetTypeEnum.apiDataset
|
||||
) {
|
||||
return Promise.reject(DatasetErrEnum.notSupportSync);
|
||||
}
|
||||
|
||||
@@ -152,20 +155,15 @@ export const syncCollection = async (collection: CollectionWithDatasetType) => {
|
||||
};
|
||||
}
|
||||
|
||||
const sourceId = collection.apiFileId;
|
||||
|
||||
if (!sourceId) return Promise.reject('apiFileId is missing');
|
||||
|
||||
if (!collection.apiFileId) return Promise.reject('apiFileId is missing');
|
||||
if (!dataset.apiServer) return Promise.reject('apiServer not found');
|
||||
return {
|
||||
type: DatasetSourceReadTypeEnum.apiFile,
|
||||
sourceId,
|
||||
apiServer: dataset.apiServer,
|
||||
feishuServer: dataset.feishuServer,
|
||||
yuqueServer: dataset.yuqueServer
|
||||
sourceId: collection.apiFileId,
|
||||
apiServer: dataset.apiServer
|
||||
};
|
||||
})();
|
||||
|
||||
const { title, rawText } = await readDatasetSourceRawText({
|
||||
const rawText = await readDatasetSourceRawText({
|
||||
teamId: collection.teamId,
|
||||
tmbId: collection.tmbId,
|
||||
...sourceReadType
|
||||
@@ -198,7 +196,7 @@ export const syncCollection = async (collection: CollectionWithDatasetType) => {
|
||||
createCollectionParams: {
|
||||
teamId: collection.teamId,
|
||||
tmbId: collection.tmbId,
|
||||
name: title || collection.name,
|
||||
name: collection.name,
|
||||
datasetId: collection.datasetId,
|
||||
parentId: collection.parentId,
|
||||
type: collection.type,
|
||||
|
||||
@@ -41,7 +41,7 @@ try {
|
||||
}
|
||||
);
|
||||
DatasetDataTextSchema.index({ teamId: 1, datasetId: 1, collectionId: 1 });
|
||||
DatasetDataTextSchema.index({ dataId: 'hashed' });
|
||||
DatasetDataTextSchema.index({ dataId: 1 }, { unique: true });
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
}
|
||||
|
||||
@@ -86,8 +86,7 @@ const DatasetDataSchema = new Schema({
|
||||
|
||||
// Abandon
|
||||
fullTextToken: String,
|
||||
initFullText: Boolean,
|
||||
initJieba: Boolean
|
||||
initFullText: Boolean
|
||||
});
|
||||
|
||||
try {
|
||||
@@ -104,9 +103,6 @@ try {
|
||||
DatasetDataSchema.index({ updateTime: 1 });
|
||||
// rebuild data
|
||||
DatasetDataSchema.index({ rebuilding: 1, teamId: 1, datasetId: 1 });
|
||||
|
||||
// 为查询 initJieba 字段不存在的数据添加索引
|
||||
DatasetDataSchema.index({ initJieba: 1, updateTime: 1 });
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
}
|
||||
|
||||
@@ -79,12 +79,9 @@ export const readDatasetSourceRawText = async ({
|
||||
apiServer?: APIFileServer; // api dataset
|
||||
feishuServer?: FeishuServer; // feishu dataset
|
||||
yuqueServer?: YuqueServer; // yuque dataset
|
||||
}): Promise<{
|
||||
title?: string;
|
||||
rawText: string;
|
||||
}> => {
|
||||
}): Promise<string> => {
|
||||
if (type === DatasetSourceReadTypeEnum.fileLocal) {
|
||||
const { filename, rawText } = await readFileContentFromMongo({
|
||||
const { rawText } = await readFileContentFromMongo({
|
||||
teamId,
|
||||
tmbId,
|
||||
bucketName: BucketNameEnum.dataset,
|
||||
@@ -92,20 +89,14 @@ export const readDatasetSourceRawText = async ({
|
||||
isQAImport,
|
||||
customPdfParse
|
||||
});
|
||||
return {
|
||||
title: filename,
|
||||
rawText
|
||||
};
|
||||
return rawText;
|
||||
} else if (type === DatasetSourceReadTypeEnum.link) {
|
||||
const result = await urlsFetch({
|
||||
urlList: [sourceId],
|
||||
selector
|
||||
});
|
||||
|
||||
return {
|
||||
title: result[0]?.title,
|
||||
rawText: result[0]?.content || ''
|
||||
};
|
||||
return result[0]?.content || '';
|
||||
} else if (type === DatasetSourceReadTypeEnum.externalFile) {
|
||||
if (!externalFileId) return Promise.reject('FileId not found');
|
||||
const rawText = await readFileRawTextByUrl({
|
||||
@@ -115,11 +106,9 @@ export const readDatasetSourceRawText = async ({
|
||||
relatedId: externalFileId,
|
||||
customPdfParse
|
||||
});
|
||||
return {
|
||||
rawText
|
||||
};
|
||||
return rawText;
|
||||
} else if (type === DatasetSourceReadTypeEnum.apiFile) {
|
||||
const { title, rawText } = await readApiServerFileContent({
|
||||
const rawText = await readApiServerFileContent({
|
||||
apiServer,
|
||||
feishuServer,
|
||||
yuqueServer,
|
||||
@@ -127,15 +116,9 @@ export const readDatasetSourceRawText = async ({
|
||||
teamId,
|
||||
tmbId
|
||||
});
|
||||
return {
|
||||
title,
|
||||
rawText
|
||||
};
|
||||
return rawText;
|
||||
}
|
||||
return {
|
||||
title: '',
|
||||
rawText: ''
|
||||
};
|
||||
return '';
|
||||
};
|
||||
|
||||
export const readApiServerFileContent = async ({
|
||||
@@ -154,10 +137,7 @@ export const readApiServerFileContent = async ({
|
||||
teamId: string;
|
||||
tmbId: string;
|
||||
customPdfParse?: boolean;
|
||||
}): Promise<{
|
||||
title?: string;
|
||||
rawText: string;
|
||||
}> => {
|
||||
}) => {
|
||||
if (apiServer) {
|
||||
return useApiDatasetRequest({ apiServer }).getFileContent({
|
||||
teamId,
|
||||
@@ -168,10 +148,7 @@ export const readApiServerFileContent = async ({
|
||||
}
|
||||
|
||||
if (feishuServer || yuqueServer) {
|
||||
return POST<{
|
||||
title?: string;
|
||||
rawText: string;
|
||||
}>(`/core/dataset/systemApiDataset`, {
|
||||
return POST<string>(`/core/dataset/systemApiDataset`, {
|
||||
type: 'content',
|
||||
feishuServer,
|
||||
yuqueServer,
|
||||
@@ -185,7 +162,7 @@ export const readApiServerFileContent = async ({
|
||||
export const rawText2Chunks = ({
|
||||
rawText,
|
||||
isQAImport,
|
||||
chunkSize = 512,
|
||||
chunkLen = 512,
|
||||
...splitProps
|
||||
}: {
|
||||
rawText: string;
|
||||
@@ -198,7 +175,7 @@ export const rawText2Chunks = ({
|
||||
|
||||
const { chunks } = splitText2Chunks({
|
||||
text: rawText,
|
||||
chunkSize,
|
||||
chunkLen,
|
||||
...splitProps
|
||||
});
|
||||
|
||||
|
||||
@@ -16,7 +16,7 @@ import { reRankRecall } from '../../../core/ai/rerank';
|
||||
import { countPromptTokens } from '../../../common/string/tiktoken/index';
|
||||
import { datasetSearchResultConcat } from '@fastgpt/global/core/dataset/search/utils';
|
||||
import { hashStr } from '@fastgpt/global/common/string/tools';
|
||||
import { jiebaSplit } from '../../../common/string/jieba/index';
|
||||
import { jiebaSplit } from '../../../common/string/jieba';
|
||||
import { getCollectionSourceData } from '@fastgpt/global/core/dataset/collection/utils';
|
||||
import { Types } from '../../../common/mongo';
|
||||
import json5 from 'json5';
|
||||
@@ -27,7 +27,6 @@ import { ChatItemType } from '@fastgpt/global/core/chat/type';
|
||||
import { POST } from '../../../common/api/plusRequest';
|
||||
import { NodeInputKeyEnum } from '@fastgpt/global/core/workflow/constants';
|
||||
import { datasetSearchQueryExtension } from './utils';
|
||||
import type { RerankModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
|
||||
export type SearchDatasetDataProps = {
|
||||
histories: ChatItemType[];
|
||||
@@ -40,11 +39,7 @@ export type SearchDatasetDataProps = {
|
||||
[NodeInputKeyEnum.datasetSimilarity]?: number; // min distance
|
||||
[NodeInputKeyEnum.datasetMaxTokens]: number; // max Token limit
|
||||
[NodeInputKeyEnum.datasetSearchMode]?: `${DatasetSearchModeEnum}`;
|
||||
[NodeInputKeyEnum.datasetSearchEmbeddingWeight]?: number;
|
||||
|
||||
[NodeInputKeyEnum.datasetSearchUsingReRank]?: boolean;
|
||||
[NodeInputKeyEnum.datasetSearchRerankModel]?: RerankModelItemType;
|
||||
[NodeInputKeyEnum.datasetSearchRerankWeight]?: number;
|
||||
|
||||
/*
|
||||
{
|
||||
@@ -80,16 +75,13 @@ export type SearchDatasetDataResponse = {
|
||||
};
|
||||
|
||||
export const datasetDataReRank = async ({
|
||||
rerankModel,
|
||||
data,
|
||||
query
|
||||
}: {
|
||||
rerankModel?: RerankModelItemType;
|
||||
data: SearchDataResponseItemType[];
|
||||
query: string;
|
||||
}): Promise<SearchDataResponseItemType[]> => {
|
||||
const results = await reRankRecall({
|
||||
model: rerankModel,
|
||||
query,
|
||||
documents: data.map((item) => ({
|
||||
id: item.id,
|
||||
@@ -134,10 +126,12 @@ export const filterDatasetDataByMaxTokens = async (
|
||||
let totalTokens = 0;
|
||||
|
||||
for await (const item of tokensScoreFilter) {
|
||||
results.push(item);
|
||||
|
||||
totalTokens += item.tokens;
|
||||
|
||||
if (totalTokens > maxTokens + 500) {
|
||||
break;
|
||||
}
|
||||
results.push(item);
|
||||
if (totalTokens > maxTokens) {
|
||||
break;
|
||||
}
|
||||
@@ -160,10 +154,7 @@ export async function searchDatasetData(
|
||||
similarity = 0,
|
||||
limit: maxTokens,
|
||||
searchMode = DatasetSearchModeEnum.embedding,
|
||||
embeddingWeight = 0.5,
|
||||
usingReRank = false,
|
||||
rerankModel,
|
||||
rerankWeight = 0.5,
|
||||
datasetIds = [],
|
||||
collectionFilterMatch
|
||||
} = props;
|
||||
@@ -535,7 +526,7 @@ export async function searchDatasetData(
|
||||
$match: {
|
||||
teamId: new Types.ObjectId(teamId),
|
||||
datasetId: new Types.ObjectId(id),
|
||||
$text: { $search: await jiebaSplit({ text: query }) },
|
||||
$text: { $search: jiebaSplit({ text: query }) },
|
||||
...(filterCollectionIdList
|
||||
? {
|
||||
collectionId: {
|
||||
@@ -720,7 +711,6 @@ export async function searchDatasetData(
|
||||
});
|
||||
try {
|
||||
return await datasetDataReRank({
|
||||
rerankModel,
|
||||
query: reRankQuery,
|
||||
data: filterSameDataResults
|
||||
});
|
||||
@@ -731,26 +721,11 @@ export async function searchDatasetData(
|
||||
})();
|
||||
|
||||
// embedding recall and fullText recall rrf concat
|
||||
const baseK = 120;
|
||||
const embK = Math.round(baseK * (1 - embeddingWeight)); // 搜索结果的 k 值
|
||||
const fullTextK = Math.round(baseK * embeddingWeight); // rerank 结果的 k 值
|
||||
|
||||
const rrfSearchResult = datasetSearchResultConcat([
|
||||
{ k: embK, list: embeddingRecallResults },
|
||||
{ k: fullTextK, list: fullTextRecallResults }
|
||||
const rrfConcatResults = datasetSearchResultConcat([
|
||||
{ k: 60, list: embeddingRecallResults },
|
||||
{ k: 60, list: fullTextRecallResults },
|
||||
{ k: 58, list: reRankResults }
|
||||
]);
|
||||
const rrfConcatResults = (() => {
|
||||
if (reRankResults.length === 0) return rrfSearchResult;
|
||||
if (rerankWeight === 1) return reRankResults;
|
||||
|
||||
const searchK = Math.round(baseK * rerankWeight); // 搜索结果的 k 值
|
||||
const rerankK = Math.round(baseK * (1 - rerankWeight)); // rerank 结果的 k 值
|
||||
|
||||
return datasetSearchResultConcat([
|
||||
{ k: searchK, list: rrfSearchResult },
|
||||
{ k: rerankK, list: reRankResults }
|
||||
]);
|
||||
})();
|
||||
|
||||
// remove same q and a data
|
||||
set = new Set<string>();
|
||||
|
||||
@@ -12,10 +12,6 @@ import { getCollectionWithDataset } from '../controller';
|
||||
import { mongoSessionRun } from '../../../common/mongo/sessionRun';
|
||||
import { PushDataToTrainingQueueProps } from '@fastgpt/global/core/dataset/training/type';
|
||||
import { i18nT } from '../../../../web/i18n/utils';
|
||||
import {
|
||||
getLLMDefaultChunkSize,
|
||||
getLLMMaxChunkSize
|
||||
} from '../../../../global/core/dataset/training/utils';
|
||||
|
||||
export const lockTrainingDataByTeamId = async (teamId: string): Promise<any> => {
|
||||
try {
|
||||
@@ -59,7 +55,6 @@ export async function pushDataListToTrainingQueue({
|
||||
prompt,
|
||||
billId,
|
||||
mode = TrainingModeEnum.chunk,
|
||||
indexSize,
|
||||
session
|
||||
}: PushDataToTrainingQueueProps): Promise<PushDatasetDataResponse> {
|
||||
const getImageChunkMode = (data: PushDatasetDataChunkProps, mode: TrainingModeEnum) => {
|
||||
@@ -73,41 +68,38 @@ export async function pushDataListToTrainingQueue({
|
||||
}
|
||||
return mode;
|
||||
};
|
||||
|
||||
const vectorModelData = getEmbeddingModel(vectorModel);
|
||||
if (!vectorModelData) {
|
||||
return Promise.reject(i18nT('common:error_embedding_not_config'));
|
||||
}
|
||||
const agentModelData = getLLMModel(agentModel);
|
||||
if (!agentModelData) {
|
||||
return Promise.reject(i18nT('common:error_llm_not_config'));
|
||||
}
|
||||
if (mode === TrainingModeEnum.chunk || mode === TrainingModeEnum.auto) {
|
||||
prompt = undefined;
|
||||
}
|
||||
|
||||
const { model, maxToken, weight } = await (async () => {
|
||||
if (mode === TrainingModeEnum.chunk) {
|
||||
const vectorModelData = getEmbeddingModel(vectorModel);
|
||||
if (!vectorModelData) {
|
||||
return Promise.reject(i18nT('common:error_embedding_not_config'));
|
||||
}
|
||||
return {
|
||||
maxToken: getLLMMaxChunkSize(agentModelData),
|
||||
maxToken: vectorModelData.maxToken * 1.5,
|
||||
model: vectorModelData.model,
|
||||
weight: vectorModelData.weight
|
||||
};
|
||||
}
|
||||
|
||||
if (mode === TrainingModeEnum.qa || mode === TrainingModeEnum.auto) {
|
||||
const agentModelData = getLLMModel(agentModel);
|
||||
if (!agentModelData) {
|
||||
return Promise.reject(i18nT('common:error_llm_not_config'));
|
||||
}
|
||||
return {
|
||||
maxToken: getLLMMaxChunkSize(agentModelData),
|
||||
maxToken: agentModelData.maxContext * 0.8,
|
||||
model: agentModelData.model,
|
||||
weight: 0
|
||||
};
|
||||
}
|
||||
|
||||
if (mode === TrainingModeEnum.image) {
|
||||
const vllmModelData = getVlmModel(vlmModel);
|
||||
if (!vllmModelData) {
|
||||
return Promise.reject(i18nT('common:error_vlm_not_config'));
|
||||
}
|
||||
return {
|
||||
maxToken: getLLMMaxChunkSize(vllmModelData),
|
||||
maxToken: vllmModelData.maxContext * 0.8,
|
||||
model: vllmModelData.model,
|
||||
weight: 0
|
||||
};
|
||||
@@ -115,6 +107,10 @@ export async function pushDataListToTrainingQueue({
|
||||
|
||||
return Promise.reject(`Training mode "${mode}" is inValid`);
|
||||
})();
|
||||
// Filter redundant params
|
||||
if (mode === TrainingModeEnum.chunk || mode === TrainingModeEnum.auto) {
|
||||
prompt = undefined;
|
||||
}
|
||||
|
||||
// filter repeat or equal content
|
||||
const set = new Set();
|
||||
@@ -147,13 +143,13 @@ export async function pushDataListToTrainingQueue({
|
||||
|
||||
const text = item.q + item.a;
|
||||
|
||||
// Oversize llm tokens
|
||||
if (text.length > maxToken) {
|
||||
filterResult.overToken.push(item);
|
||||
return;
|
||||
}
|
||||
|
||||
if (set.has(text)) {
|
||||
console.log('repeat', item);
|
||||
filterResult.repeat.push(item);
|
||||
} else {
|
||||
filterResult.success.push(item);
|
||||
@@ -186,7 +182,6 @@ export async function pushDataListToTrainingQueue({
|
||||
q: item.q,
|
||||
a: item.a,
|
||||
chunkIndex: item.chunkIndex ?? 0,
|
||||
indexSize,
|
||||
weight: weight ?? 0,
|
||||
indexes: item.indexes,
|
||||
retryCount: 5
|
||||
|
||||
@@ -76,7 +76,6 @@ const TrainingDataSchema = new Schema({
|
||||
type: Number,
|
||||
default: 0
|
||||
},
|
||||
indexSize: Number,
|
||||
weight: {
|
||||
type: Number,
|
||||
default: 0
|
||||
|
||||
@@ -10,7 +10,8 @@ import type { ClassifyQuestionAgentItemType } from '@fastgpt/global/core/workflo
|
||||
import { NodeInputKeyEnum, NodeOutputKeyEnum } from '@fastgpt/global/core/workflow/constants';
|
||||
import { DispatchNodeResponseKeyEnum } from '@fastgpt/global/core/workflow/runtime/constants';
|
||||
import type { ModuleDispatchProps } from '@fastgpt/global/core/workflow/runtime/type';
|
||||
import { getCQPrompt } from '@fastgpt/global/core/ai/prompt/agent';
|
||||
import { replaceVariable } from '@fastgpt/global/common/string/tools';
|
||||
import { Prompt_CQJson } from '@fastgpt/global/core/ai/prompt/agent';
|
||||
import { LLMModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
import { getLLMModel } from '../../../ai/model';
|
||||
import { getHistories } from '../utils';
|
||||
@@ -22,7 +23,6 @@ import { loadRequestMessages } from '../../../chat/utils';
|
||||
import { llmCompletionsBodyFormat } from '../../../ai/utils';
|
||||
import { addLog } from '../../../../common/system/log';
|
||||
import { ModelTypeEnum } from '../../../../../global/core/ai/model';
|
||||
import { replaceVariable } from '@fastgpt/global/common/string/tools';
|
||||
|
||||
type Props = ModuleDispatchProps<{
|
||||
[NodeInputKeyEnum.aiModel]: string;
|
||||
@@ -99,8 +99,7 @@ const completions = async ({
|
||||
cqModel,
|
||||
externalProvider,
|
||||
histories,
|
||||
params: { agents, systemPrompt = '', userChatInput },
|
||||
node: { version }
|
||||
params: { agents, systemPrompt = '', userChatInput }
|
||||
}: ActionProps) => {
|
||||
const messages: ChatItemType[] = [
|
||||
{
|
||||
@@ -109,7 +108,7 @@ const completions = async ({
|
||||
{
|
||||
type: ChatItemValueTypeEnum.text,
|
||||
text: {
|
||||
content: replaceVariable(cqModel.customCQPrompt || getCQPrompt(version), {
|
||||
content: replaceVariable(cqModel.customCQPrompt || Prompt_CQJson, {
|
||||
systemPrompt: systemPrompt || 'null',
|
||||
typeList: agents
|
||||
.map((item) => `{"类型ID":"${item.key}", "问题类型":"${item.value}"}`)
|
||||
|
||||
@@ -16,6 +16,7 @@ import {
|
||||
} from '@fastgpt/global/core/workflow/constants';
|
||||
import { DispatchNodeResponseKeyEnum } from '@fastgpt/global/core/workflow/runtime/constants';
|
||||
import type { ModuleDispatchProps } from '@fastgpt/global/core/workflow/runtime/type';
|
||||
import { Prompt_ExtractJson } from '@fastgpt/global/core/ai/prompt/agent';
|
||||
import { replaceVariable, sliceJsonStr } from '@fastgpt/global/common/string/tools';
|
||||
import { LLMModelItemType } from '@fastgpt/global/core/ai/model.d';
|
||||
import { getHistories } from '../utils';
|
||||
@@ -32,10 +33,6 @@ import { DispatchNodeResultType } from '@fastgpt/global/core/workflow/runtime/ty
|
||||
import { chatValue2RuntimePrompt } from '@fastgpt/global/core/chat/adapt';
|
||||
import { llmCompletionsBodyFormat } from '../../../ai/utils';
|
||||
import { ModelTypeEnum } from '../../../../../global/core/ai/model';
|
||||
import {
|
||||
getExtractJsonPrompt,
|
||||
getExtractJsonToolPrompt
|
||||
} from '@fastgpt/global/core/ai/prompt/agent';
|
||||
|
||||
type Props = ModuleDispatchProps<{
|
||||
[NodeInputKeyEnum.history]?: ChatItemType[];
|
||||
@@ -157,8 +154,7 @@ export async function dispatchContentExtract(props: Props): Promise<Response> {
|
||||
const getFunctionCallSchema = async ({
|
||||
extractModel,
|
||||
histories,
|
||||
params: { content, extractKeys, description },
|
||||
node: { version }
|
||||
params: { content, extractKeys, description }
|
||||
}: ActionProps) => {
|
||||
const messages: ChatItemType[] = [
|
||||
...histories,
|
||||
@@ -168,10 +164,15 @@ const getFunctionCallSchema = async ({
|
||||
{
|
||||
type: ChatItemValueTypeEnum.text,
|
||||
text: {
|
||||
content: replaceVariable(getExtractJsonToolPrompt(version), {
|
||||
description,
|
||||
content
|
||||
})
|
||||
content: `我正在执行一个函数,需要你提供一些参数,请以 JSON 字符串格式返回这些参数,要求:
|
||||
"""
|
||||
${description ? `- ${description}` : ''}
|
||||
- 不是每个参数都是必须生成的,如果没有合适的参数值,不要生成该参数,或返回空字符串。
|
||||
- 需要结合前面的对话内容,一起生成合适的参数。
|
||||
"""
|
||||
|
||||
本次输入内容: """${content}"""
|
||||
`
|
||||
}
|
||||
}
|
||||
]
|
||||
@@ -333,8 +334,7 @@ const completions = async ({
|
||||
extractModel,
|
||||
externalProvider,
|
||||
histories,
|
||||
params: { content, extractKeys, description = 'No special requirements' },
|
||||
node: { version }
|
||||
params: { content, extractKeys, description = 'No special requirements' }
|
||||
}: ActionProps) => {
|
||||
const messages: ChatItemType[] = [
|
||||
{
|
||||
@@ -343,26 +343,23 @@ const completions = async ({
|
||||
{
|
||||
type: ChatItemValueTypeEnum.text,
|
||||
text: {
|
||||
content: replaceVariable(
|
||||
extractModel.customExtractPrompt || getExtractJsonPrompt(version),
|
||||
{
|
||||
description,
|
||||
json: extractKeys
|
||||
.map((item) => {
|
||||
const valueType = item.valueType || 'string';
|
||||
if (valueType !== 'string' && valueType !== 'number') {
|
||||
item.enum = undefined;
|
||||
}
|
||||
content: replaceVariable(extractModel.customExtractPrompt || Prompt_ExtractJson, {
|
||||
description,
|
||||
json: extractKeys
|
||||
.map((item) => {
|
||||
const valueType = item.valueType || 'string';
|
||||
if (valueType !== 'string' && valueType !== 'number') {
|
||||
item.enum = undefined;
|
||||
}
|
||||
|
||||
return `{"type":${item.valueType || 'string'}, "key":"${item.key}", "description":"${item.desc}" ${
|
||||
item.enum ? `, "enum":"[${item.enum.split('\n')}]"` : ''
|
||||
}}`;
|
||||
})
|
||||
.join('\n'),
|
||||
text: `${histories.map((item) => `${item.obj}:${chatValue2RuntimePrompt(item.value).text}`).join('\n')}
|
||||
return `{"type":${item.valueType || 'string'}, "key":"${item.key}", "description":"${item.desc}" ${
|
||||
item.enum ? `, "enum":"[${item.enum.split('\n')}]"` : ''
|
||||
}}`;
|
||||
})
|
||||
.join('\n'),
|
||||
text: `${histories.map((item) => `${item.obj}:${chatValue2RuntimePrompt(item.value).text}`).join('\n')}
|
||||
Human: ${content}`
|
||||
}
|
||||
)
|
||||
})
|
||||
}
|
||||
}
|
||||
]
|
||||
|
||||
@@ -28,10 +28,10 @@ import { filterToolResponseToPreview } from './utils';
|
||||
import { InteractiveNodeResponseType } from '@fastgpt/global/core/workflow/template/system/interactive/type';
|
||||
import { getFileContentFromLinks, getHistoryFileLinks } from '../../tools/readFiles';
|
||||
import { parseUrlToFileType } from '@fastgpt/global/common/file/tools';
|
||||
import { Prompt_DocumentQuote } from '@fastgpt/global/core/ai/prompt/AIChat';
|
||||
import { FlowNodeTypeEnum } from '@fastgpt/global/core/workflow/node/constant';
|
||||
import { postTextCensor } from '../../../../../common/api/requestPlusApi';
|
||||
import { ModelTypeEnum } from '@fastgpt/global/core/ai/model';
|
||||
import { getDocumentQuotePrompt } from '@fastgpt/global/core/ai/prompt/AIChat';
|
||||
|
||||
type Response = DispatchNodeResultType<{
|
||||
[NodeOutputKeyEnum.answerText]: string;
|
||||
@@ -40,7 +40,7 @@ type Response = DispatchNodeResultType<{
|
||||
|
||||
export const dispatchRunTools = async (props: DispatchToolModuleProps): Promise<Response> => {
|
||||
const {
|
||||
node: { nodeId, name, isEntry, version },
|
||||
node: { nodeId, name, isEntry },
|
||||
runtimeNodes,
|
||||
runtimeEdges,
|
||||
histories,
|
||||
@@ -118,7 +118,7 @@ export const dispatchRunTools = async (props: DispatchToolModuleProps): Promise<
|
||||
toolModel.defaultSystemChatPrompt,
|
||||
systemPrompt,
|
||||
documentQuoteText
|
||||
? replaceVariable(getDocumentQuotePrompt(version), {
|
||||
? replaceVariable(Prompt_DocumentQuote, {
|
||||
quote: documentQuoteText
|
||||
})
|
||||
: ''
|
||||
|
||||