Compare commits
103 Commits
v4.9.1
...
v4.9.5-alp
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
16a22bc76a | ||
|
|
b51a87f5b7 | ||
|
|
bc1ca66b66 | ||
|
|
c9e12bb608 | ||
|
|
4e7fa29087 | ||
|
|
ec3bcfa124 | ||
|
|
199f454b6b | ||
|
|
80f41dd2a9 | ||
|
|
4343eecaaf | ||
|
|
c02864facc | ||
|
|
e4629a5c8c | ||
|
|
2dc3cb75fe | ||
|
|
431390fe42 | ||
|
|
1f5709eda6 | ||
|
|
86988e31d9 | ||
|
|
675e8ccedb | ||
|
|
9dfafb13bf | ||
|
|
f642c9603b | ||
|
|
5839325f77 | ||
|
|
73c997f7c5 | ||
|
|
ff92dced98 | ||
|
|
7a0747947c | ||
|
|
5ad383bc6e | ||
|
|
c85b719384 | ||
|
|
aeedc2fada | ||
|
|
be34b69f9b | ||
|
|
944774ec5f | ||
|
|
5b21b4b674 | ||
|
|
b0f0afabd2 | ||
|
|
d9aea53d13 | ||
|
|
73db92e4ad | ||
|
|
267cc5702c | ||
|
|
540f321fc9 | ||
|
|
a37c75159f | ||
|
|
0ed99d8c9a | ||
|
|
2d3ae7f944 | ||
|
|
565a966d19 | ||
|
|
8323c2d27e | ||
|
|
4f86a0591c | ||
|
|
14895bbcfd | ||
|
|
ccf9f5be2e | ||
|
|
e5b986b4de | ||
|
|
cf119a9f0f | ||
|
|
05b3062204 | ||
|
|
fed04f0b5d | ||
|
|
96aabdf579 | ||
|
|
e9f75c7e66 | ||
|
|
8b29aae238 | ||
|
|
8999dc5b8c | ||
|
|
17b20270e1 | ||
|
|
9d97b60561 | ||
|
|
f483832749 | ||
|
|
0778508908 | ||
|
|
f3a069bc80 | ||
|
|
2ebb2ccc9c | ||
|
|
484b87478c | ||
|
|
a17623d4ea | ||
|
|
dd2f7bdcfd | ||
|
|
4871a6980f | ||
|
|
64fb09146f | ||
|
|
1fdf947a13 | ||
|
|
ff64a3c039 | ||
|
|
37b4a1919b | ||
|
|
826a53dcb6 | ||
|
|
5a47af6fff | ||
|
|
6ea57e4609 | ||
|
|
2fcf421672 | ||
|
|
a680b565ea | ||
|
|
e812ad6e84 | ||
|
|
222ff0d49a | ||
|
|
2c73e9dc12 | ||
|
|
9918133426 | ||
|
|
8eec8566db | ||
|
|
6a4eada85b | ||
|
|
652ec45bbd | ||
|
|
6fee39873d | ||
|
|
87e90c37bd | ||
|
|
73451dbc64 | ||
|
|
077350e651 | ||
|
|
d52700c645 | ||
|
|
ec30d79286 | ||
|
|
cb29076e5b | ||
|
|
29a10c1389 | ||
|
|
28877373ac | ||
|
|
4538f2a9d4 | ||
|
|
fc23db745c | ||
|
|
8a68de6471 | ||
|
|
1c4e0c66d5 | ||
|
|
6dcdd540b9 | ||
|
|
48233c7d55 | ||
|
|
f3ef56998d | ||
|
|
7e7269b2ba | ||
|
|
606e9505c0 | ||
|
|
1db39e8907 | ||
|
|
7f13eb4642 | ||
|
|
9a1fff74fd | ||
|
|
de87639fce | ||
|
|
f9cecfd49a | ||
|
|
70563d2bcb | ||
|
|
4ca99a6361 | ||
|
|
8f70e436cf | ||
|
|
e75d81d05a | ||
|
|
56793114d8 |
@@ -1,4 +1,4 @@
|
||||
yangchuansheng/fastgpt-imgs:
|
||||
- source: docSite/assets/imgs/
|
||||
dest: imgs/
|
||||
deleteOrphaned: true
|
||||
deleteOrphaned: true
|
||||
30
.github/gh-bot.yml
vendored
@@ -1,30 +0,0 @@
|
||||
version: v1
|
||||
debug: true
|
||||
action:
|
||||
printConfig: false
|
||||
release:
|
||||
retry: 15s
|
||||
actionName: Release
|
||||
allowOps:
|
||||
- cuisongliu
|
||||
bot:
|
||||
prefix: /
|
||||
spe: _
|
||||
allowOps:
|
||||
- sealos-ci-robot
|
||||
- sealos-release-robot
|
||||
email: sealos-ci-robot@sealos.io
|
||||
username: sealos-ci-robot
|
||||
repo:
|
||||
org: false
|
||||
|
||||
message:
|
||||
success: |
|
||||
🤖 says: Hooray! The action {{.Body}} has been completed successfully. 🎉
|
||||
format_error: |
|
||||
🤖 says: ‼️ There is a formatting issue with the action, kindly verify the action's format.
|
||||
permission_error: |
|
||||
🤖 says: ‼️ The action doesn't have permission to trigger.
|
||||
release_error: |
|
||||
🤖 says: ‼️ Release action failed.
|
||||
Error details: {{.Error}}
|
||||
@@ -1,4 +1,4 @@
|
||||
name: Deploy doc image to vercel
|
||||
name: Deploy doc image to cf
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
@@ -20,6 +20,11 @@ jobs:
|
||||
# The type of runner that the job will run on
|
||||
runs-on: ubuntu-22.04
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.ref }}
|
||||
|
||||
# Job outputs
|
||||
outputs:
|
||||
docs: ${{ steps.filter.outputs.docs }}
|
||||
@@ -58,20 +63,9 @@ jobs:
|
||||
- name: Build
|
||||
run: cd docSite && hugo mod get -u github.com/colinwilson/lotusdocs@6d0568e && hugo -v --minify
|
||||
|
||||
# Step 5 - Push our generated site to Vercel
|
||||
- name: Deploy to Vercel
|
||||
uses: amondnet/vercel-action@v25
|
||||
id: vercel-action
|
||||
with:
|
||||
vercel-token: ${{ secrets.VERCEL_TOKEN }} # Required
|
||||
vercel-org-id: ${{ secrets.VERCEL_ORG_ID }} #Required
|
||||
vercel-project-id: ${{ secrets.VERCEL_PROJECT_ID }} #Required
|
||||
github-comment: false
|
||||
vercel-args: '--prod --local-config ../vercel.json' # Optional
|
||||
working-directory: docSite/public
|
||||
|
||||
- name: Deploy to GitHub Pages
|
||||
uses: peaceiris/actions-gh-pages@v3
|
||||
uses: peaceiris/actions-gh-pages@v4
|
||||
if: github.ref == 'refs/heads/main'
|
||||
with:
|
||||
github_token: ${{ secrets.GH_PAT }}
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
publish_dir: docSite/public
|
||||
19
.github/workflows/docs-deploy-kubeconfig.yml
vendored
@@ -10,6 +10,13 @@ on:
|
||||
jobs:
|
||||
build-fastgpt-docs-images:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
packages: write
|
||||
attestations: write
|
||||
id-token: write
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
@@ -27,7 +34,6 @@ jobs:
|
||||
with:
|
||||
# list of Docker images to use as base name for tags
|
||||
images: |
|
||||
${{ secrets.DOCKER_HUB_NAME }}/fastgpt-docs
|
||||
ghcr.io/${{ github.repository_owner }}/fastgpt-docs
|
||||
registry.cn-hangzhou.aliyuncs.com/${{ secrets.ALI_HUB_USERNAME }}/fastgpt-docs
|
||||
tags: |
|
||||
@@ -40,18 +46,12 @@ jobs:
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
|
||||
- name: Login to DockerHub
|
||||
uses: docker/login-action@v3
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_HUB_NAME }}
|
||||
password: ${{ secrets.DOCKER_HUB_PASSWORD }}
|
||||
|
||||
- name: Login to ghcr.io
|
||||
uses: docker/login-action@v3
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GH_PAT }}
|
||||
username: ${{ github.actor }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Login to Aliyun
|
||||
uses: docker/login-action@v3
|
||||
@@ -70,6 +70,7 @@ jobs:
|
||||
labels: ${{ steps.meta.outputs.labels }}
|
||||
outputs:
|
||||
tags: ${{ steps.datetime.outputs.datetime }}
|
||||
|
||||
update-docs-image:
|
||||
needs: build-fastgpt-docs-images
|
||||
runs-on: ubuntu-20.04
|
||||
|
||||
75
.github/workflows/docs-preview.yml
vendored
@@ -10,6 +10,12 @@ on:
|
||||
jobs:
|
||||
# This workflow contains jobs "deploy-production"
|
||||
deploy-preview:
|
||||
permissions:
|
||||
contents: read
|
||||
packages: write
|
||||
attestations: write
|
||||
id-token: write
|
||||
pull-requests: write
|
||||
# The environment this job references
|
||||
environment:
|
||||
name: Preview
|
||||
@@ -32,6 +38,7 @@ jobs:
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
submodules: recursive # Fetch submodules
|
||||
fetch-depth: 0 # Fetch all history for .GitInfo and .Lastmod
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
# Step 2 Detect changes to Docs Content
|
||||
- name: Detect changes in doc content
|
||||
@@ -43,10 +50,6 @@ jobs:
|
||||
- 'docSite/content/docs/**'
|
||||
base: main
|
||||
|
||||
- name: Add cdn for images
|
||||
run: |
|
||||
sed -i "s#\](/imgs/#\](https://cdn.jsdelivr.net/gh/yangchuansheng/fastgpt-imgs@main/imgs/#g" $(grep -rl "\](/imgs/" docSite/content/zh-cn/docs)
|
||||
|
||||
# Step 3 - Install Hugo (specific version)
|
||||
- name: Install Hugo
|
||||
uses: peaceiris/actions-hugo@v2
|
||||
@@ -58,39 +61,35 @@ jobs:
|
||||
- name: Build
|
||||
run: cd docSite && hugo mod get -u github.com/colinwilson/lotusdocs@6d0568e && hugo -v --minify
|
||||
|
||||
# Step 5 - Push our generated site to Vercel
|
||||
- name: Deploy to Vercel
|
||||
uses: amondnet/vercel-action@v25
|
||||
id: vercel-action
|
||||
# Step 5 - Push our generated site to Cloudflare
|
||||
- name: Deploy to Cloudflare Pages
|
||||
id: deploy
|
||||
uses: cloudflare/wrangler-action@v3
|
||||
with:
|
||||
vercel-token: ${{ secrets.VERCEL_TOKEN }} # Required
|
||||
vercel-org-id: ${{ secrets.VERCEL_ORG_ID }} #Required
|
||||
vercel-project-id: ${{ secrets.VERCEL_PROJECT_ID }} #Required
|
||||
github-comment: false
|
||||
vercel-args: '--local-config ../vercel.json' # Optional
|
||||
working-directory: docSite/public
|
||||
alias-domains: | #Optional
|
||||
fastgpt-staging.vercel.app
|
||||
docsOutput:
|
||||
needs: [deploy-preview]
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
- name: Write md
|
||||
run: |
|
||||
echo "# 🤖 Generated by deploy action" > report.md
|
||||
echo "[👀 Visit Preview](${{ needs.deploy-preview.outputs.url }})" >> report.md
|
||||
cat report.md
|
||||
- name: Gh Rebot for Sealos
|
||||
uses: labring/gh-rebot@v0.0.6
|
||||
if: ${{ (github.event_name == 'pull_request_target') }}
|
||||
with:
|
||||
version: v0.0.6
|
||||
apiToken: ${{ secrets.CLOUDFLARE_API_TOKEN }}
|
||||
accountId: ${{ secrets.CLOUDFLARE_ACCOUNT_ID }}
|
||||
command: pages deploy ./docSite/public --project-name=fastgpt-doc
|
||||
packageManager: npm
|
||||
|
||||
- name: Create deployment status comment
|
||||
if: always()
|
||||
env:
|
||||
GH_TOKEN: '${{ secrets.GH_PAT }}'
|
||||
SEALOS_TYPE: 'pr_comment'
|
||||
SEALOS_FILENAME: 'report.md'
|
||||
SEALOS_REPLACE_TAG: 'DEFAULT_REPLACE_DEPLOY'
|
||||
JOB_STATUS: ${{ job.status }}
|
||||
PREVIEW_URL: ${{ steps.deploy.outputs.deployment-url }}
|
||||
uses: actions/github-script@v6
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
script: |
|
||||
const success = process.env.JOB_STATUS === 'success';
|
||||
const deploymentUrl = `${process.env.PREVIEW_URL}`;
|
||||
const status = success ? '✅ Success' : '❌ Failed';
|
||||
console.log(process.env.JOB_STATUS);
|
||||
|
||||
const commentBody = `**Deployment Status: ${status}**
|
||||
${success ? `🔗 Preview URL: ${deploymentUrl}` : ''}`;
|
||||
|
||||
await github.rest.issues.createComment({
|
||||
...context.repo,
|
||||
issue_number: context.payload.pull_request.number,
|
||||
body: commentBody
|
||||
});
|
||||
|
||||
11
.github/workflows/docs-sync_imgs.yml
vendored
@@ -1,6 +1,6 @@
|
||||
name: Sync images
|
||||
on:
|
||||
pull_request_target:
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
@@ -15,13 +15,6 @@ jobs:
|
||||
sync:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
if: ${{ (github.event_name == 'pull_request_target') }}
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
|
||||
@@ -32,4 +25,4 @@ jobs:
|
||||
CONFIG_PATH: .github/sync_imgs.yml
|
||||
ORIGINAL_MESSAGE: true
|
||||
SKIP_PR: true
|
||||
COMMIT_EACH_FILE: false
|
||||
COMMIT_EACH_FILE: false
|
||||
|
||||
@@ -9,6 +9,11 @@ on:
|
||||
- 'main'
|
||||
jobs:
|
||||
build-fastgpt-images:
|
||||
permissions:
|
||||
packages: write
|
||||
contents: read
|
||||
attestations: write
|
||||
id-token: write
|
||||
runs-on: ubuntu-20.04
|
||||
if: github.repository != 'labring/FastGPT'
|
||||
steps:
|
||||
@@ -32,7 +37,7 @@ jobs:
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GH_PAT }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Set DOCKER_REPO_TAGGED based on branch or tag
|
||||
run: |
|
||||
echo "DOCKER_REPO_TAGGED=ghcr.io/${{ github.repository_owner }}/fastgpt:latest" >> $GITHUB_ENV
|
||||
|
||||
21
.github/workflows/fastgpt-build-image.yml
vendored
@@ -9,6 +9,11 @@ on:
|
||||
- 'v*'
|
||||
jobs:
|
||||
build-fastgpt-images:
|
||||
permissions:
|
||||
packages: write
|
||||
contents: read
|
||||
attestations: write
|
||||
id-token: write
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
# install env
|
||||
@@ -39,7 +44,7 @@ jobs:
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GH_PAT }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Login to Ali Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
@@ -91,6 +96,11 @@ jobs:
|
||||
-t ${Docker_Hub_Latest} \
|
||||
.
|
||||
build-fastgpt-images-sub-route:
|
||||
permissions:
|
||||
packages: write
|
||||
contents: read
|
||||
attestations: write
|
||||
id-token: write
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
# install env
|
||||
@@ -121,7 +131,7 @@ jobs:
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GH_PAT }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Login to Ali Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
@@ -174,6 +184,11 @@ jobs:
|
||||
-t ${Docker_Hub_Latest} \
|
||||
.
|
||||
build-fastgpt-images-sub-route-gchat:
|
||||
permissions:
|
||||
packages: write
|
||||
contents: read
|
||||
attestations: write
|
||||
id-token: write
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
# install env
|
||||
@@ -204,7 +219,7 @@ jobs:
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GH_PAT }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Login to Ali Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
|
||||
40
.github/workflows/fastgpt-preview-image.yml
vendored
@@ -5,6 +5,13 @@ on:
|
||||
|
||||
jobs:
|
||||
preview-fastgpt-images:
|
||||
permissions:
|
||||
contents: read
|
||||
packages: write
|
||||
attestations: write
|
||||
id-token: write
|
||||
pull-requests: write
|
||||
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
- name: Checkout
|
||||
@@ -12,8 +19,9 @@ jobs:
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
submodules: recursive # Fetch submodules
|
||||
fetch-depth: 0 # Fetch all history for .GitInfo and .Lastmod
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
with:
|
||||
@@ -25,15 +33,18 @@ jobs:
|
||||
key: ${{ runner.os }}-buildx-${{ github.sha }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-buildx-
|
||||
|
||||
- name: Login to GitHub Container Registry
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GH_PAT }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Set DOCKER_REPO_TAGGED based on branch or tag
|
||||
run: |
|
||||
echo "DOCKER_REPO_TAGGED=ghcr.io/${{ github.repository_owner }}/fastgpt-pr:${{ github.event.pull_request.head.sha }}" >> $GITHUB_ENV
|
||||
|
||||
- name: Build image for PR
|
||||
env:
|
||||
DOCKER_REPO_TAGGED: ${{ env.DOCKER_REPO_TAGGED }}
|
||||
@@ -48,20 +59,13 @@ jobs:
|
||||
--cache-to=type=local,dest=/tmp/.buildx-cache \
|
||||
-t ${DOCKER_REPO_TAGGED} \
|
||||
.
|
||||
# Add write md step after build
|
||||
- name: Write md
|
||||
run: |
|
||||
echo "# 🤖 Generated by deploy action" > report.md
|
||||
echo "📦 Preview Image: \`${DOCKER_REPO_TAGGED}\`" >> report.md
|
||||
cat report.md
|
||||
|
||||
- name: Gh Rebot for Sealos
|
||||
uses: labring/gh-rebot@v0.0.6
|
||||
if: ${{ (github.event_name == 'pull_request_target') }}
|
||||
- uses: actions/github-script@v7
|
||||
with:
|
||||
version: v0.0.6
|
||||
env:
|
||||
GH_TOKEN: '${{ secrets.GH_PAT }}'
|
||||
SEALOS_TYPE: 'pr_comment'
|
||||
SEALOS_FILENAME: 'report.md'
|
||||
SEALOS_REPLACE_TAG: 'DEFAULT_REPLACE_DEPLOY'
|
||||
github-token: ${{secrets.GITHUB_TOKEN}}
|
||||
script: |
|
||||
github.rest.issues.createComment({
|
||||
issue_number: context.issue.number,
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
body: 'Preview Image: `${{ env.DOCKER_REPO_TAGGED }}`'
|
||||
})
|
||||
|
||||
3
.github/workflows/fastgpt-test.yaml
vendored
@@ -15,6 +15,9 @@ jobs:
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
- uses: pnpm/action-setup@v4
|
||||
with:
|
||||
version: 10
|
||||
|
||||
7
.github/workflows/helm-release.yaml
vendored
@@ -8,6 +8,11 @@ on:
|
||||
|
||||
jobs:
|
||||
helm:
|
||||
permissions:
|
||||
packages: write
|
||||
contents: read
|
||||
attestations: write
|
||||
id-token: write
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
- name: Checkout
|
||||
@@ -20,7 +25,7 @@ jobs:
|
||||
run: echo "tag=$(git describe --tags)" >> $GITHUB_OUTPUT
|
||||
- name: Release Helm
|
||||
run: |
|
||||
echo ${{ secrets.GH_PAT }} | helm registry login ghcr.io -u ${{ github.repository_owner }} --password-stdin
|
||||
echo ${{ secrets.GITHUB_TOKEN }} | helm registry login ghcr.io -u ${{ github.repository_owner }} --password-stdin
|
||||
export APP_VERSION=${{ steps.vars.outputs.tag }}
|
||||
export HELM_VERSION=${{ steps.vars.outputs.tag }}
|
||||
export HELM_REPO=ghcr.io/${{ github.repository_owner }}
|
||||
|
||||
7
.github/workflows/sandbox-build-image.yml
vendored
@@ -8,6 +8,11 @@ on:
|
||||
- 'v*'
|
||||
jobs:
|
||||
build-fastgpt-sandbox-images:
|
||||
permissions:
|
||||
packages: write
|
||||
contents: read
|
||||
attestations: write
|
||||
id-token: write
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
# install env
|
||||
@@ -38,7 +43,7 @@ jobs:
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GH_PAT }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Login to Ali Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
|
||||
7
.vscode/i18n-ally-custom-framework.yml
vendored
@@ -17,15 +17,8 @@ usageMatchRegex:
|
||||
# you can ignore it and use your own matching rules as well
|
||||
- "[^\\w\\d]t\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]commonT\\(['\"`]({key})['\"`]"
|
||||
# 支持 appT("your.i18n.keys")
|
||||
- "[^\\w\\d]appT\\(['\"`]({key})['\"`]"
|
||||
# 支持 datasetT("your.i18n.keys")
|
||||
- "[^\\w\\d]datasetT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]fileT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]publishT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]workflowT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]userT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]chatT\\(['\"`]({key})['\"`]"
|
||||
- "[^\\w\\d]i18nT\\(['\"`]({key})['\"`]"
|
||||
|
||||
# A RegEx to set a custom scope range. This scope will be used as a prefix when detecting keys
|
||||
|
||||
39
.vscode/launch.json
vendored
Normal file
@@ -0,0 +1,39 @@
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Next.js: debug server-side",
|
||||
"type": "node-terminal",
|
||||
"request": "launch",
|
||||
"command": "pnpm run dev",
|
||||
"cwd": "${workspaceFolder}/projects/app"
|
||||
},
|
||||
{
|
||||
"name": "Next.js: debug client-side",
|
||||
"type": "chrome",
|
||||
"request": "launch",
|
||||
"url": "http://localhost:3000"
|
||||
},
|
||||
{
|
||||
"name": "Next.js: debug client-side (Edge)",
|
||||
"type": "msedge",
|
||||
"request": "launch",
|
||||
"url": "http://localhost:3000"
|
||||
},
|
||||
{
|
||||
"name": "Next.js: debug full stack",
|
||||
"type": "node-terminal",
|
||||
"request": "launch",
|
||||
"command": "pnpm run dev",
|
||||
"cwd": "${workspaceFolder}/projects/app",
|
||||
"skipFiles": ["<node_internals>/**"],
|
||||
"serverReadyAction": {
|
||||
"action": "debugWithEdge",
|
||||
"killOnServerStop": true,
|
||||
"pattern": "- Local:.+(https?://.+)",
|
||||
"uriFormat": "%s",
|
||||
"webRoot": "${workspaceFolder}/projects/app"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
@@ -10,7 +10,7 @@
|
||||
<a href="./README_ja.md">日语</a>
|
||||
</p>
|
||||
|
||||
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
|
||||
FastGPT 是一个 AI Agent 构建平台,提供开箱即用的数据处理、模型调用等能力,同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的应用场景!
|
||||
|
||||
</div>
|
||||
|
||||
@@ -129,7 +129,7 @@ https://github.com/labring/FastGPT/assets/15308462/7d3a38df-eb0e-4388-9250-2409b
|
||||
</a>
|
||||
|
||||
## 🌿 第三方生态
|
||||
|
||||
- [PPIO 派欧云:一键调用高性价比的开源模型 API 和 GPU 容器](https://ppinfra.com/user/register?invited_by=VITYVU&utm_source=github_fastgpt)
|
||||
- [AI Proxy:国内模型聚合服务](https://sealos.run/aiproxy/?k=fastgpt-github/)
|
||||
- [SiliconCloud (硅基流动) —— 开源模型在线体验平台](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
||||
- [COW 个人微信/企微机器人](https://doc.tryfastgpt.ai/docs/use-cases/external-integration/onwechat/)
|
||||
|
||||
@@ -110,19 +110,31 @@ services:
|
||||
|
||||
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
|
||||
wait $$!
|
||||
redis:
|
||||
image: redis:7.2-alpine
|
||||
container_name: redis
|
||||
# ports:
|
||||
# - 6379:6379
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
command: |
|
||||
redis-server --requirepass mypassword --loglevel warning --maxclients 10000 --appendonly yes --save 60 10 --maxmemory 4gb --maxmemory-policy noeviction
|
||||
volumes:
|
||||
- ./redis/data:/data
|
||||
|
||||
# fastgpt
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.0 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.4 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.4 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.0 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.4 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.4 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -157,6 +169,8 @@ services:
|
||||
# zilliz 连接参数
|
||||
- MILVUS_ADDRESS=http://milvusStandalone:19530
|
||||
- MILVUS_TOKEN=none
|
||||
# Redis 地址
|
||||
- REDIS_URL=redis://default:mypassword@redis:6379
|
||||
# sandbox 地址
|
||||
- SANDBOX_URL=http://sandbox:3000
|
||||
# 日志等级: debug, info, warn, error
|
||||
@@ -170,12 +184,15 @@ services:
|
||||
- ALLOWED_ORIGINS=
|
||||
# 是否开启IP限制,默认不开启
|
||||
- USE_IP_LIMIT=false
|
||||
# 对话文件过期天数
|
||||
- CHAT_FILE_EXPIRE_TIME=7
|
||||
volumes:
|
||||
- ./config.json:/app/data/config.json
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: 'ghcr.io/labring/aiproxy:latest'
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
|
||||
202
deploy/docker/docker-compose-oceanbase/docker-compose.yml
Normal file
@@ -0,0 +1,202 @@
|
||||
# 数据库的默认账号和密码仅首次运行时设置有效
|
||||
# 如果修改了账号密码,记得改数据库和项目连接参数,别只改一处~
|
||||
# 该配置文件只是给快速启动,测试使用。正式使用,记得务必修改账号密码,以及调整合适的知识库参数,共享内存等。
|
||||
# 如何无法访问 dockerhub 和 git,可以用阿里云(阿里云没有arm包)
|
||||
|
||||
version: '3.3'
|
||||
services:
|
||||
# vector db
|
||||
ob:
|
||||
image: oceanbase/oceanbase-ce # docker hub
|
||||
# image: quay.io/oceanbase/oceanbase-ce:4.3.5.1-101000042025031818 # 镜像
|
||||
container_name: ob
|
||||
restart: always
|
||||
# ports: # 生产环境建议不要暴露
|
||||
# - 2881:2881
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
|
||||
- OB_SYS_PASSWORD=obsyspassword
|
||||
# 不同于传统数据库,OceanBase 数据库的账号包含更多字段,包括用户名、租户名和集群名。经典格式为“用户名@租户名#集群名”
|
||||
# 比如用mysql客户端连接时,根据本文件的默认配置,应该指定 “-uroot@tenantname”
|
||||
- OB_TENANT_NAME=tenantname
|
||||
- OB_TENANT_PASSWORD=tenantpassword
|
||||
# MODE分为MINI和NORMAL, 后者会最大程度使用主机资源
|
||||
- MODE=NORMAL
|
||||
- OB_SERVER_IP=127.0.0.1
|
||||
# 更多环境变量配置见oceanbase官方文档: https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002013494
|
||||
volumes:
|
||||
- ./ob/data:/root/ob
|
||||
- ./ob/config:/root/.obd/cluster
|
||||
- ./init.sql:/root/boot/init.d/init.sql
|
||||
healthcheck:
|
||||
# obclient -h127.0.0.1 -P2881 -uroot@tenantname -ptenantpassword -e "SELECT 1;"
|
||||
test: ["CMD-SHELL", "obclient -h$OB_SERVER_IP -P2881 -uroot@$OB_TENANT_NAME -p$OB_TENANT_PASSWORD -e \"SELECT 1;\""]
|
||||
interval: 30s
|
||||
timeout: 10s
|
||||
retries: 1000
|
||||
start_period: 10s
|
||||
mongo:
|
||||
image: mongo:5.0.18 # dockerhub
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
|
||||
# image: mongo:4.4.29 # cpu不支持AVX时候使用
|
||||
container_name: mongo
|
||||
restart: always
|
||||
# ports:
|
||||
# - 27017:27017
|
||||
networks:
|
||||
- fastgpt
|
||||
command: mongod --keyFile /data/mongodb.key --replSet rs0
|
||||
environment:
|
||||
- MONGO_INITDB_ROOT_USERNAME=myusername
|
||||
- MONGO_INITDB_ROOT_PASSWORD=mypassword
|
||||
volumes:
|
||||
- ./mongo/data:/data/db
|
||||
entrypoint:
|
||||
- bash
|
||||
- -c
|
||||
- |
|
||||
openssl rand -base64 128 > /data/mongodb.key
|
||||
chmod 400 /data/mongodb.key
|
||||
chown 999:999 /data/mongodb.key
|
||||
echo 'const isInited = rs.status().ok === 1
|
||||
if(!isInited){
|
||||
rs.initiate({
|
||||
_id: "rs0",
|
||||
members: [
|
||||
{ _id: 0, host: "mongo:27017" }
|
||||
]
|
||||
})
|
||||
}' > /data/initReplicaSet.js
|
||||
# 启动MongoDB服务
|
||||
exec docker-entrypoint.sh "$$@" &
|
||||
|
||||
# 等待MongoDB服务启动
|
||||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
|
||||
echo "Waiting for MongoDB to start..."
|
||||
sleep 2
|
||||
done
|
||||
|
||||
# 执行初始化副本集的脚本
|
||||
mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js
|
||||
|
||||
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
|
||||
wait $$!
|
||||
|
||||
# fastgpt
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.3 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.3 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.9.3 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.3 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
- fastgpt
|
||||
depends_on:
|
||||
mongo:
|
||||
condition: service_started
|
||||
ob:
|
||||
condition: service_healthy
|
||||
sandbox:
|
||||
condition: service_started
|
||||
restart: always
|
||||
environment:
|
||||
# 前端外部可访问的地址,用于自动补全文件资源路径。例如 https:fastgpt.cn,不能填 localhost。这个值可以不填,不填则发给模型的图片会是一个相对路径,而不是全路径,模型可能伪造Host。
|
||||
- FE_DOMAIN=
|
||||
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。
|
||||
- DEFAULT_ROOT_PSW=1234
|
||||
# # AI Proxy 的地址,如果配了该地址,优先使用
|
||||
# - AIPROXY_API_ENDPOINT=http://aiproxy:3000
|
||||
# # AI Proxy 的 Admin Token,与 AI Proxy 中的环境变量 ADMIN_KEY
|
||||
# - AIPROXY_API_TOKEN=aiproxy
|
||||
# 模型中转地址(如果用了 AI Proxy,下面 2 个就不需要了,旧版 OneAPI 用户,使用下面的变量)
|
||||
- # openai 基本地址,可用作中转。
|
||||
- OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
|
||||
- # OpenAI API Key
|
||||
- CHAT_API_KEY=sk-8990fa15a34b464a805237cfe9561f11
|
||||
# 数据库最大连接数
|
||||
- DB_MAX_LINK=30
|
||||
# 登录凭证密钥
|
||||
- TOKEN_KEY=any
|
||||
# root的密钥,常用于升级时候的初始化请求
|
||||
- ROOT_KEY=root_key
|
||||
# 文件阅读加密
|
||||
- FILE_TOKEN_KEY=filetoken
|
||||
# MongoDB 连接参数. 用户名myusername,密码mypassword。
|
||||
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
|
||||
# OceanBase 向量库连接参数
|
||||
- OCEANBASE_URL=mysql://root%40tenantname:tenantpassword@ob:2881/test
|
||||
# sandbox 地址
|
||||
- SANDBOX_URL=http://sandbox:3000
|
||||
# 日志等级: debug, info, warn, error
|
||||
- LOG_LEVEL=info
|
||||
- STORE_LOG_LEVEL=warn
|
||||
# 工作流最大运行次数
|
||||
- WORKFLOW_MAX_RUN_TIMES=1000
|
||||
# 批量执行节点,最大输入长度
|
||||
- WORKFLOW_MAX_LOOP_TIMES=100
|
||||
# 自定义跨域,不配置时,默认都允许跨域(多个域名通过逗号分割)
|
||||
- ALLOWED_ORIGINS=
|
||||
# 是否开启IP限制,默认不开启
|
||||
- USE_IP_LIMIT=false
|
||||
volumes:
|
||||
- ./config.json:/app/data/config.json
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: ghcr.io/labring/aiproxy:v0.1.5
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
aiproxy_pg:
|
||||
condition: service_healthy
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
# 对应 fastgpt 里的AIPROXY_API_TOKEN
|
||||
- ADMIN_KEY=aiproxy
|
||||
# 错误日志详情保存时间(小时)
|
||||
- LOG_DETAIL_STORAGE_HOURS=1
|
||||
# 数据库连接地址
|
||||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||||
# 最大重试次数
|
||||
- RETRY_TIMES=3
|
||||
# 不需要计费
|
||||
- BILLING_ENABLED=false
|
||||
# 不需要严格检测模型
|
||||
- DISABLE_MODEL_CONFIG=true
|
||||
healthcheck:
|
||||
test: ['CMD', 'curl', '-f', 'http://localhost:3000/api/status']
|
||||
interval: 5s
|
||||
timeout: 5s
|
||||
retries: 10
|
||||
aiproxy_pg:
|
||||
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||||
restart: unless-stopped
|
||||
container_name: aiproxy_pg
|
||||
volumes:
|
||||
- ./aiproxy_pg:/var/lib/postgresql/data
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
POSTGRES_USER: postgres
|
||||
POSTGRES_DB: aiproxy
|
||||
POSTGRES_PASSWORD: aiproxy
|
||||
healthcheck:
|
||||
test: ['CMD', 'pg_isready', '-U', 'postgres', '-d', 'aiproxy']
|
||||
interval: 5s
|
||||
timeout: 5s
|
||||
retries: 10
|
||||
networks:
|
||||
fastgpt:
|
||||
2
deploy/docker/docker-compose-oceanbase/init.sql
Normal file
@@ -0,0 +1,2 @@
|
||||
ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;
|
||||
|
||||
@@ -69,18 +69,31 @@ services:
|
||||
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
|
||||
wait $$!
|
||||
|
||||
redis:
|
||||
image: redis:7.2-alpine
|
||||
container_name: redis
|
||||
# ports:
|
||||
# - 6379:6379
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
command: |
|
||||
redis-server --requirepass mypassword --loglevel warning --maxclients 10000 --appendonly yes --save 60 10 --maxmemory 4gb --maxmemory-policy noeviction
|
||||
volumes:
|
||||
- ./redis/data:/data
|
||||
|
||||
# fastgpt
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.0 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.4 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.4 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.0 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.4 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.4 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -114,6 +127,8 @@ services:
|
||||
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
|
||||
# pg 连接参数
|
||||
- PG_URL=postgresql://username:password@pg:5432/postgres
|
||||
# Redis 连接参数
|
||||
- REDIS_URL=redis://default:mypassword@redis:6379
|
||||
# sandbox 地址
|
||||
- SANDBOX_URL=http://sandbox:3000
|
||||
# 日志等级: debug, info, warn, error
|
||||
@@ -127,12 +142,15 @@ services:
|
||||
- ALLOWED_ORIGINS=
|
||||
# 是否开启IP限制,默认不开启
|
||||
- USE_IP_LIMIT=false
|
||||
# 对话文件过期天数
|
||||
- CHAT_FILE_EXPIRE_TIME=7
|
||||
volumes:
|
||||
- ./config.json:/app/data/config.json
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: 'ghcr.io/labring/aiproxy:latest'
|
||||
image: ghcr.io/labring/aiproxy:v0.1.5
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
|
||||
@@ -51,17 +51,30 @@ services:
|
||||
|
||||
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
|
||||
wait $$!
|
||||
redis:
|
||||
image: redis:7.2-alpine
|
||||
container_name: redis
|
||||
# ports:
|
||||
# - 6379:6379
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
command: |
|
||||
redis-server --requirepass mypassword --loglevel warning --maxclients 10000 --appendonly yes --save 60 10 --maxmemory 4gb --maxmemory-policy noeviction
|
||||
volumes:
|
||||
- ./redis/data:/data
|
||||
|
||||
sandbox:
|
||||
container_name: sandbox
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.0 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt-sandbox:v4.9.4 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.4 # 阿里云
|
||||
networks:
|
||||
- fastgpt
|
||||
restart: always
|
||||
fastgpt:
|
||||
container_name: fastgpt
|
||||
image: ghcr.io/labring/fastgpt:v4.9.0 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.0 # 阿里云
|
||||
image: ghcr.io/labring/fastgpt:v4.9.4 # git
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.4 # 阿里云
|
||||
ports:
|
||||
- 3000:3000
|
||||
networks:
|
||||
@@ -92,6 +105,8 @@ services:
|
||||
- FILE_TOKEN_KEY=filetoken
|
||||
# MongoDB 连接参数. 用户名myusername,密码mypassword。
|
||||
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
|
||||
# Redis 连接参数
|
||||
- REDIS_URI=redis://default:mypassword@redis:6379
|
||||
# zilliz 连接参数
|
||||
- MILVUS_ADDRESS=zilliz_cloud_address
|
||||
- MILVUS_TOKEN=zilliz_cloud_token
|
||||
@@ -108,12 +123,15 @@ services:
|
||||
- ALLOWED_ORIGINS=
|
||||
# 是否开启IP限制,默认不开启
|
||||
- USE_IP_LIMIT=false
|
||||
# 对话文件过期天数
|
||||
- CHAT_FILE_EXPIRE_TIME=7
|
||||
volumes:
|
||||
- ./config.json:/app/data/config.json
|
||||
|
||||
# AI Proxy
|
||||
aiproxy:
|
||||
image: 'ghcr.io/labring/aiproxy:latest'
|
||||
image: ghcr.io/labring/aiproxy:v0.1.3
|
||||
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3 # 阿里云
|
||||
container_name: aiproxy
|
||||
restart: unless-stopped
|
||||
depends_on:
|
||||
|
||||
@@ -7,7 +7,7 @@ data:
|
||||
"vectorMaxProcess": 15,
|
||||
"qaMaxProcess": 15,
|
||||
"vlmMaxProcess": 15,
|
||||
"pgHNSWEfSearch": 100
|
||||
"hnswEfSearch": 100
|
||||
},
|
||||
"llmModels": [
|
||||
{
|
||||
|
||||
BIN
docSite/assets/imgs/Ollama-aiproxy1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 68 KiB |
BIN
docSite/assets/imgs/Ollama-aiproxy2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 9.0 KiB |
BIN
docSite/assets/imgs/Ollama-aiproxy3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 179 KiB |
BIN
docSite/assets/imgs/Ollama-direct1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
BIN
docSite/assets/imgs/Ollama-models1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
docSite/assets/imgs/Ollama-models2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 138 KiB |
BIN
docSite/assets/imgs/Ollama-models3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 122 KiB |
BIN
docSite/assets/imgs/Ollama-models4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 124 KiB |
BIN
docSite/assets/imgs/Ollama-oneapi1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 94 KiB |
BIN
docSite/assets/imgs/Ollama-oneapi2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 57 KiB |
BIN
docSite/assets/imgs/Ollama-oneapi3 .png
Normal file
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
BIN
docSite/assets/imgs/Ollama-pull.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
BIN
docSite/assets/imgs/chunkReader1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
docSite/assets/imgs/chunkReader2.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 159 KiB |
BIN
docSite/assets/imgs/chunkReader3.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 71 KiB |
BIN
docSite/assets/imgs/chunkReader4.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 139 KiB |
BIN
docSite/assets/imgs/chunkReader5.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 57 KiB |
BIN
docSite/assets/imgs/chunkReader6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 122 KiB |
BIN
docSite/assets/imgs/chunkReader7.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 44 KiB |
BIN
docSite/assets/imgs/chunkReader8.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 197 KiB |
BIN
docSite/assets/imgs/chunkReader9.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 120 KiB |
{kind=link}
|
After Width: | Height: | Size: 170 KiB |
{kind=link}
|
After Width: | Height: | Size: 102 KiB |
{kind=link}
|
After Width: | Height: | Size: 70 KiB |
{kind=link}
|
After Width: | Height: | Size: 89 KiB |
{kind=link}
|
After Width: | Height: | Size: 87 KiB |
BIN
docSite/assets/imgs/sealos-redis1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 284 KiB |
BIN
docSite/assets/imgs/sealos-redis2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 294 KiB |
BIN
docSite/assets/imgs/sealos-redis3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 86 KiB |
BIN
docSite/assets/imgs/sso1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 133 KiB |
BIN
docSite/assets/imgs/sso10.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 124 KiB |
BIN
docSite/assets/imgs/sso11.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 117 KiB |
BIN
docSite/assets/imgs/sso12.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 79 KiB |
BIN
docSite/assets/imgs/sso13.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 319 KiB |
BIN
docSite/assets/imgs/sso14.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 174 KiB |
BIN
docSite/assets/imgs/sso15.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.2 KiB |
BIN
docSite/assets/imgs/sso16.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.7 KiB |
BIN
docSite/assets/imgs/sso17.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.8 KiB |
BIN
docSite/assets/imgs/sso18.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 177 KiB |
BIN
docSite/assets/imgs/sso2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 255 KiB |
BIN
docSite/assets/imgs/sso3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 24 KiB |
BIN
docSite/assets/imgs/sso4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 117 KiB |
BIN
docSite/assets/imgs/sso5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 86 KiB |
BIN
docSite/assets/imgs/sso6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
BIN
docSite/assets/imgs/sso7.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 140 KiB |
BIN
docSite/assets/imgs/sso8.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 108 KiB |
BIN
docSite/assets/imgs/sso9.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 119 KiB |
BIN
docSite/assets/imgs/sso_update1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 39 KiB |
BIN
docSite/assets/imgs/teammode.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 265 KiB |
@@ -25,7 +25,7 @@ weight: 707
|
||||
"qaMaxProcess": 15, // 问答拆分线程数量
|
||||
"vlmMaxProcess": 15, // 图片理解模型最大处理进程
|
||||
"tokenWorkers": 50, // Token 计算线程保持数,会持续占用内存,不能设置太大。
|
||||
"pgHNSWEfSearch": 100, // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
|
||||
"hnswEfSearch": 100, // 向量搜索参数,仅对 PG 和 OB 生效。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
|
||||
"customPdfParse": { // 4.9.0 新增配置
|
||||
"url": "", // 自定义 PDF 解析服务地址
|
||||
"key": "", // 自定义 PDF 解析服务密钥
|
||||
|
||||
@@ -31,9 +31,9 @@ weight: 920
|
||||
|
||||
3 个模型代码分别为:
|
||||
|
||||
1. [https://github.com/labring/FastGPT/tree/main/plugins/rerank-bge/bge-reranker-base](https://github.com/labring/FastGPT/tree/main/plugins/rerank-bge/bge-reranker-base)
|
||||
2. [https://github.com/labring/FastGPT/tree/main/plugins/rerank-bge/bge-reranker-large](https://github.com/labring/FastGPT/tree/main/plugins/rerank-bge/bge-reranker-large)
|
||||
3. [https://github.com/labring/FastGPT/tree/main/plugins/rerank-bge/bge-reranker-v2-m3](https://github.com/labring/FastGPT/tree/main/plugins/rerank-bge/bge-reranker-v2-m3)
|
||||
1. [https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-base](https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-base)
|
||||
2. [https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-large](https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-large)
|
||||
3. [https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-v2-m3](https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-v2-m3)
|
||||
|
||||
### 3. 安装依赖
|
||||
|
||||
|
||||
@@ -46,7 +46,7 @@ ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,
|
||||
### 源码部署
|
||||
|
||||
1. 根据上面的环境配置配置好环境,具体教程自行 GPT;
|
||||
2. 下载 [python 文件](https://github.com/labring/FastGPT/blob/main/files/models/ChatGLM2/openai_api.py)
|
||||
2. 下载 [python 文件](https://github.com/labring/FastGPT/blob/main/plugins/model/llm-ChatGLM2/openai_api.py)
|
||||
3. 在命令行输入命令 `pip install -r requirements.txt`;
|
||||
4. 打开你需要启动的 py 文件,在代码的 `verify_token` 方法中配置 token,这里的 token 只是加一层验证,防止接口被人盗用;
|
||||
5. 执行命令 `python openai_api.py --model_name 16`。这里的数字根据上面的配置进行选择。
|
||||
|
||||
184
docSite/content/zh-cn/docs/development/custom-models/ollama.md
Normal file
@@ -0,0 +1,184 @@
|
||||
---
|
||||
title: '使用 Ollama 接入本地模型 '
|
||||
description: ' 采用 Ollama 部署自己的模型'
|
||||
icon: 'api'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 950
|
||||
---
|
||||
|
||||
[Ollama](https://ollama.com/) 是一个开源的AI大模型部署工具,专注于简化大语言模型的部署和使用,支持一键下载和运行各种大模型。
|
||||
|
||||
## 安装 Ollama
|
||||
|
||||
Ollama 本身支持多种安装方式,但是推荐使用 Docker 拉取镜像部署。如果是个人设备上安装了 Ollama 后续需要解决如何让 Docker 中 FastGPT 容器访问宿主机 Ollama的问题,较为麻烦。
|
||||
|
||||
### Docker 安装(推荐)
|
||||
|
||||
你可以使用 Ollama 官方的 Docker 镜像来一键安装和启动 Ollama 服务(确保你的机器上已经安装了 Docker),命令如下:
|
||||
|
||||
```bash
|
||||
docker pull ollama/ollama
|
||||
docker run --rm -d --name ollama -p 11434:11434 ollama/ollama
|
||||
```
|
||||
|
||||
如果你的 FastGPT 是在 Docker 中进行部署的,建议在拉取 Ollama 镜像时保证和 FastGPT 镜像处于同一网络,否则可能出现 FastGPT 无法访问的问题,命令如下:
|
||||
|
||||
```bash
|
||||
docker run --rm -d --name ollama --network (你的 Fastgpt 容器所在网络) -p 11434:11434 ollama/ollama
|
||||
```
|
||||
|
||||
### 主机安装
|
||||
|
||||
如果你不想使用 Docker ,也可以采用主机安装,以下是主机安装的一些方式。
|
||||
|
||||
#### MacOS
|
||||
|
||||
如果你使用的是 macOS,且系统中已经安装了 Homebrew 包管理器,可通过以下命令来安装 Ollama:
|
||||
|
||||
```bash
|
||||
brew install ollama
|
||||
ollama serve #安装完成后,使用该命令启动服务
|
||||
```
|
||||
|
||||
#### Linux
|
||||
|
||||
在 Linux 系统上,你可以借助包管理器来安装 Ollama。以 Ubuntu 为例,在终端执行以下命令:
|
||||
|
||||
```bash
|
||||
curl https://ollama.com/install.sh | sh #此命令会从官方网站下载并执行安装脚本。
|
||||
ollama serve #安装完成后,同样启动服务
|
||||
```
|
||||
|
||||
#### Windows
|
||||
|
||||
在 Windows 系统中,你可以从 Ollama 官方网站 下载 Windows 版本的安装程序。下载完成后,运行安装程序,按照安装向导的提示完成安装。安装完成后,在命令提示符或 PowerShell 中启动服务:
|
||||
|
||||
```bash
|
||||
ollama serve #安装完成并启动服务后,你可以在浏览器中访问 http://localhost:11434 来验证 Ollama 是否安装成功。
|
||||
```
|
||||
|
||||
#### 补充说明
|
||||
|
||||
如果你是采用的主机应用 Ollama 而不是镜像,需要确保你的 Ollama 可以监听0.0.0.0。
|
||||
|
||||
##### 1. Linxu 系统
|
||||
|
||||
如果 Ollama 作为 systemd 服务运行,打开终端,编辑 Ollama 的 systemd 服务文件,使用命令sudo systemctl edit ollama.service,在[Service]部分添加Environment="OLLAMA_HOST=0.0.0.0"。保存并退出编辑器,然后执行sudo systemctl daemon - reload和sudo systemctl restart ollama使配置生效。
|
||||
|
||||
##### 2. MacOS 系统
|
||||
|
||||
打开终端,使用launchctl setenv ollama_host "0.0.0.0"命令设置环境变量,然后重启 Ollama 应用程序以使更改生效。
|
||||
|
||||
##### 3. Windows 系统
|
||||
|
||||
通过 “开始” 菜单或搜索栏打开 “编辑系统环境变量”,在 “系统属性” 窗口中点击 “环境变量”,在 “系统变量” 部分点击 “新建”,创建一个名为OLLAMA_HOST的变量,变量值设置为0.0.0.0,点击 “确定” 保存更改,最后从 “开始” 菜单重启 Ollama 应用程序。
|
||||
|
||||
### Ollama 拉取模型镜像
|
||||
|
||||
在安装后 Ollama 后,本地是没有模型镜像的,需要自己去拉取 Ollama 中的模型镜像。命令如下:
|
||||
|
||||
```bash
|
||||
# Docker 部署需要先进容器,命令为: docker exec -it < Ollama 容器名 > /bin/sh
|
||||
ollama pull <模型名>
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
### 测试通信
|
||||
|
||||
在安装完成后,需要进行检测测试,首先进入 FastGPT 所在的容器,尝试访问自己的 Ollama ,命令如下:
|
||||
|
||||
```bash
|
||||
docker exec -it < FastGPT 所在的容器名 > /bin/sh
|
||||
curl http://XXX.XXX.XXX.XXX:11434 #容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||||
```
|
||||
|
||||
看到访问显示自己的 Ollama 服务以及启动,说明可以正常通信。
|
||||
|
||||
## 将 Ollama 接入 FastGPT
|
||||
|
||||
### 1. 查看 Ollama 所拥有的模型
|
||||
|
||||
首先采用下述命令查看 Ollama 中所拥有的模型,
|
||||
|
||||
```bash
|
||||
# Docker 部署 Ollama,需要此命令 docker exec -it < Ollama 容器名 > /bin/sh
|
||||
ollama ls
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 2. AI Proxy 接入
|
||||
|
||||
如果你采用的是 FastGPT 中的默认配置文件部署[这里](/docs/development/docker.md),即默认采用 AI Proxy 进行启动。
|
||||
|
||||

|
||||
|
||||
以及在确保你的 FastGPT 可以直接访问 Ollama 容器的情况下,无法访问,参考上文[点此跳转](#安装-ollama)的安装过程,检测是不是主机不能监测0.0.0.0,或者容器不在同一个网络。
|
||||
|
||||

|
||||
|
||||
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。详细参考[这里](/docs/development/modelConfig/intro.md)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
运行 FastGPT ,在页面中选择账号->模型提供商->模型渠道->新增渠道。之后,在渠道选择中选择 Ollama ,然后加入自己拉取的模型,填入代理地址,如果是容器中安装 Ollama ,代理地址为http://地址:端口,补充:容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||||
|
||||

|
||||
|
||||
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||||
|
||||

|
||||
|
||||
### 3. OneAPI 接入
|
||||
|
||||
如果你想使用 OneAPI ,首先需要拉取 OneAPI 镜像,然后将其在 FastGPT 容器的网络中运行。具体命令如下:
|
||||
|
||||
```bash
|
||||
# 拉取 oneAPI 镜像
|
||||
docker pull intel/oneapi-hpckit
|
||||
|
||||
# 运行容器并指定自定义网络和容器名
|
||||
docker run -it --network < FastGPT 网络 > --name 容器名 intel/oneapi-hpckit /bin/bash
|
||||
```
|
||||
|
||||
进入 OneAPI 页面,添加新的渠道,类型选择 Ollama ,在模型中填入自己 Ollama 中的模型,需要保证添加的模型名称和 Ollama 中一致,再在下方填入自己的 Ollama 代理地址,默认http://地址:端口,不需要填写/v1。添加成功后在 OneAPI 进行渠道测试,测试成功则说明添加成功。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||||
|
||||

|
||||
|
||||
渠道添加成功后,点击令牌,点击添加令牌,填写名称,修改配置。
|
||||
|
||||

|
||||
|
||||
修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,在 OPENAI_BASE_URL 中加入自己的 OneAPI 开放地址,默认是http://地址:端口/v1,v1必须填写。KEY 中填写自己在 OneAPI 的令牌。
|
||||
|
||||

|
||||
|
||||
[直接跳转5](#5-模型添加和使用)添加模型,并使用。
|
||||
|
||||
### 4. 直接接入
|
||||
|
||||
如果你既不想使用 AI Proxy,也不想使用 OneAPI,也可以选择直接接入,修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,采用和 OneAPI 的类似配置。注释掉 AIProxy 相关代码,在OPENAI_BASE_URL中加入自己的 Ollama 开放地址,默认是http://地址:端口/v1,强调:v1必须填写。在KEY中随便填入,因为 Ollama 默认没有鉴权,如果开启鉴权,请自行填写。其他操作和在 OneAPI 中加入 Ollama 一致,只需在 FastGPT 中加入自己的模型即可使用。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||||
|
||||

|
||||
|
||||
完成后[点击这里](#5-模型添加和使用)进行模型添加并使用。
|
||||
|
||||
### 5. 模型添加和使用
|
||||
|
||||
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||||
|
||||

|
||||
|
||||
### 6. 补充
|
||||
上述接入 Ollama 的代理地址中,主机安装 Ollama 的地址为“http://<主机IP>:<端口>”,容器部署 Ollama 地址为“http://<容器名>:<端口>”
|
||||
@@ -56,7 +56,7 @@ weight: 707
|
||||
|
||||
### zilliz cloud版本
|
||||
|
||||
Milvus 的全托管服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||||
Zilliz Cloud 由 Milvus 原厂打造,是全托管的 SaaS 向量数据库服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||||
|
||||
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
|
||||
|
||||
@@ -135,6 +135,9 @@ curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data
|
||||
|
||||
# pgvector 版本(测试推荐,简单快捷)
|
||||
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
|
||||
# oceanbase 版本(需要将init.sql和docker-compose.yml放在同一个文件夹,方便挂载)
|
||||
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/docker-compose.yml
|
||||
# curl -o init.sql https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/init.sql
|
||||
# milvus 版本
|
||||
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-milvus.yml
|
||||
# zilliz 版本
|
||||
@@ -151,6 +154,13 @@ curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/mai
|
||||
|
||||
无需操作
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< tab tabName="Oceanbase版本" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
无需操作
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< tab tabName="Milvus版本" >}}
|
||||
|
||||
@@ -71,7 +71,7 @@ Mongo 数据库需要注意,需要注意在连接地址中增加 `directConnec
|
||||
- `vectorMaxProcess`: 向量生成最大进程,根据数据库和 key 的并发数来决定,通常单个 120 号,2c4g 服务器设置 10~15。
|
||||
- `qaMaxProcess`: QA 生成最大进程
|
||||
- `vlmMaxProcess`: 图片理解模型最大进程
|
||||
- `pgHNSWEfSearch`: PostgreSQL vector 索引参数,越大搜索精度越高但是速度越慢,具体可看 pgvector 官方说明。
|
||||
- `hnswEfSearch`: 向量搜索参数,仅对 PG 和 OB 生效,越大搜索精度越高但是速度越慢。
|
||||
|
||||
### 5. 运行
|
||||
|
||||
|
||||
@@ -302,7 +302,7 @@ OneAPI 的语言识别接口,无法正确的识别其他模型(会始终识
|
||||
"vectorMaxProcess": 15, // 向量处理线程数量
|
||||
"qaMaxProcess": 15, // 问答拆分线程数量
|
||||
"tokenWorkers": 50, // Token 计算线程保持数,会持续占用内存,不能设置太大。
|
||||
"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
|
||||
"hnswEfSearch": 100 // 向量搜索参数,仅对 PG 和 OB 生效。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
|
||||
},
|
||||
"llmModels": [
|
||||
{
|
||||
|
||||
100
docSite/content/zh-cn/docs/development/modelConfig/ppio.md
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
title: '通过 PPIO LLM API 接入模型'
|
||||
description: '通过 PPIO LLM API 接入模型'
|
||||
icon: 'api'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 747
|
||||
---
|
||||
|
||||
FastGPT 还可以通过 PPIO LLM API 接入模型。
|
||||
{{% alert context="warning" %}}
|
||||
以下内容搬运自 [FastGPT 接入 PPIO LLM API](https://ppinfra.com/docs/third-party/fastgpt-use),可能会有更新不及时的情况。
|
||||
{{% /alert %}}
|
||||
|
||||
FastGPT 是一个将 AI 开发、部署和使用全流程简化为可视化操作的平台。它使开发者不需要深入研究算法,
|
||||
用户也不需要掌握复杂技术,通过一站式服务将人工智能技术变成易于使用的工具。
|
||||
|
||||
PPIO 派欧云提供简单易用的 API 接口,让开发者能够轻松调用 DeepSeek 等模型。
|
||||
|
||||
- 对开发者:无需重构架构,3 个接口完成从文本生成到决策推理的全场景接入,像搭积木一样设计 AI 工作流;
|
||||
- 对生态:自动适配从中小应用到企业级系统的资源需求,让智能随业务自然生长。
|
||||
|
||||
下方教程提供完整接入方案(含密钥配置),帮助您快速将 FastGPT 与 PPIO API 连接起来。
|
||||
|
||||
## 1. 配置前置条件
|
||||
|
||||
(1) 获取 API 接口地址
|
||||
|
||||
固定为: `https://api.ppinfra.com/v3/openai/chat/completions`。
|
||||
|
||||
(2) 获取 【API 密钥】
|
||||
|
||||
登录派欧云控制台 [API 秘钥管理](https://www.ppinfra.com/settings/key-management) 页面,点击创建按钮。
|
||||
注册账号填写邀请码【VOJL20】得 50 代金券
|
||||
|
||||
|
||||
|
||||
(3) 生成并保存 【API 密钥】
|
||||
{{% alert context="warning" %}}
|
||||
秘钥在服务端是加密存储,请在生成时保存好秘钥;若遗失可以在控制台上删除并创建一个新的秘钥。
|
||||
{{% /alert %}}
|
||||
|
||||
|
||||
|
||||
|
||||
(4) 获取需要使用的模型 ID
|
||||
|
||||
deepseek 系列:
|
||||
|
||||
- DeepSeek R1:deepseek/deepseek-r1/community
|
||||
|
||||
- DeepSeek V3:deepseek/deepseek-v3/community
|
||||
|
||||
其他模型 ID、最大上下文及价格可参考:[模型列表](https://ppinfra.com/model-api/pricing)
|
||||
|
||||
## 2. 部署最新版 FastGPT 到本地环境
|
||||
{{% alert context="warning" %}}
|
||||
请使用 v4.8.22 以上版本,部署参考: https://doc.tryfastgpt.ai/docs/development/intro/
|
||||
{{% /alert %}}
|
||||
|
||||
## 3. 模型配置(下面两种方式二选其一)
|
||||
|
||||
(1)通过 OneAPI 接入模型 PPIO 模型: 参考 OneAPI 使用文档,修改 FastGPT 的环境变量 在 One API 生成令牌后,FastGPT 可以通过修改 baseurl 和 key 去请求到 One API,再由 One API 去请求不同的模型。修改下面两个环境变量: 务必写上 v1。如果在同一个网络内,可改成内网地址。
|
||||
|
||||
OPENAI_BASE_URL= http://OneAPI-IP:OneAPI-PORT/v1
|
||||
|
||||
下面的 key 是由 One API 提供的令牌 CHAT_API_KEY=sk-UyVQcpQWMU7ChTVl74B562C28e3c46Fe8f16E6D8AeF8736e
|
||||
|
||||
- 修改后重启 FastGPT,按下图在模型提供商中选择派欧云
|
||||
|
||||
|
||||
|
||||
- 测试连通性
|
||||
以 deepseek 为例,在模型中选择使用 deepseek/deepseek-r1/community,点击图中②的位置进行连通性测试,出现图中绿色的的成功显示证明连通成功,可以进行后续的配置对话了
|
||||
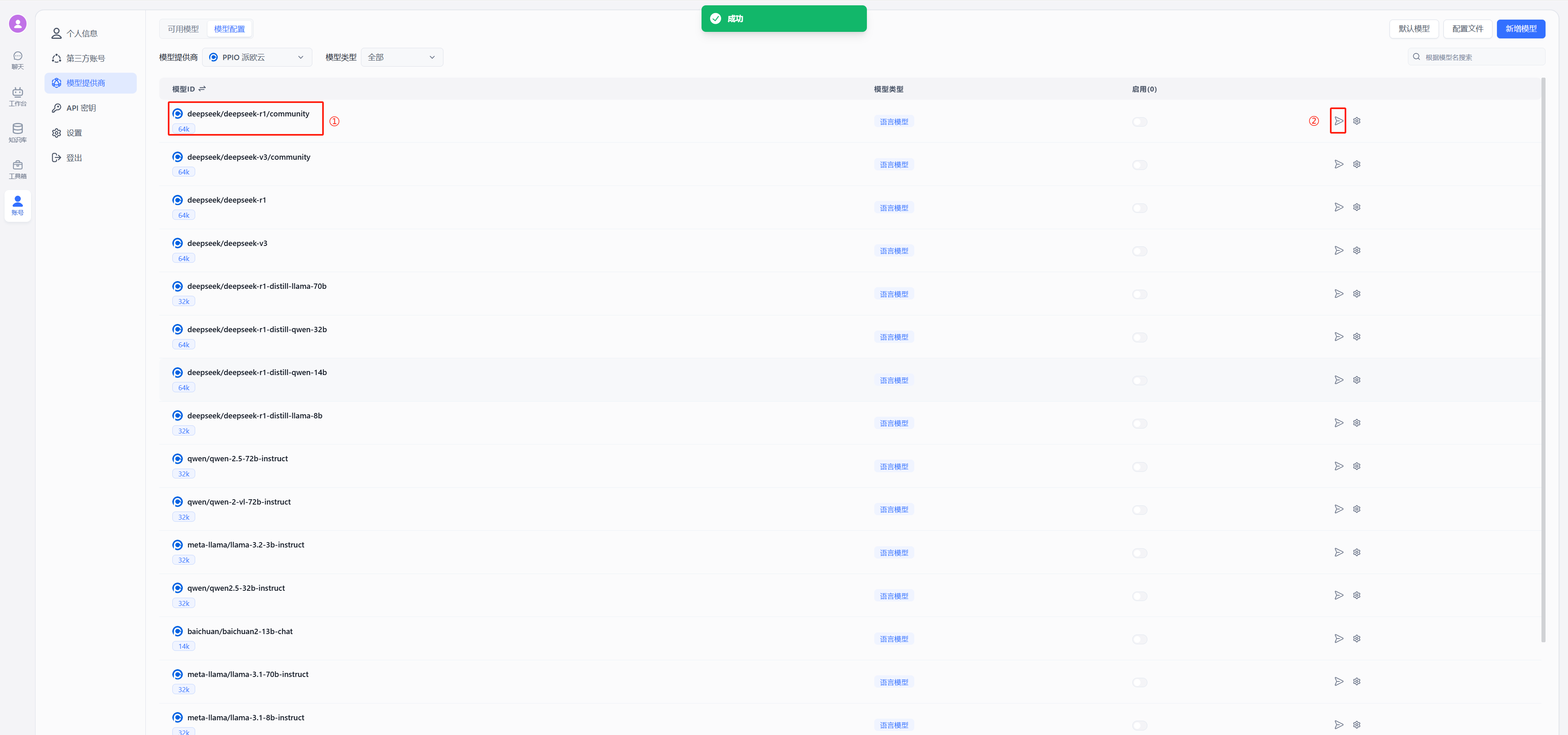
|
||||
|
||||
(2)不使用 OneAPI 接入 PPIO 模型
|
||||
|
||||
按照下图在模型提供商中选择派欧云
|
||||
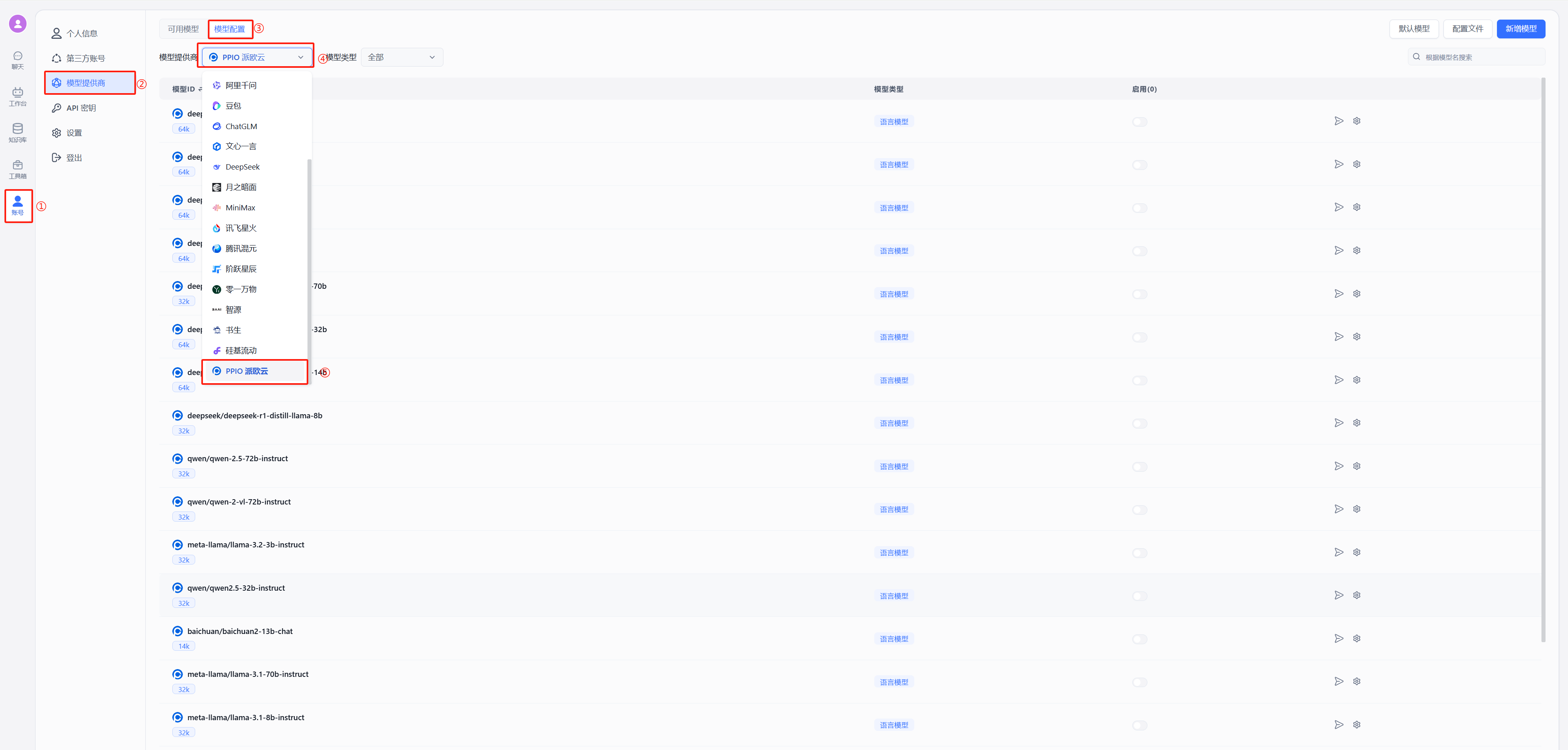
|
||||
|
||||
- 配置模型 自定义请求地址中输入:`https://api.ppinfra.com/v3/openai/chat/completions`
|
||||
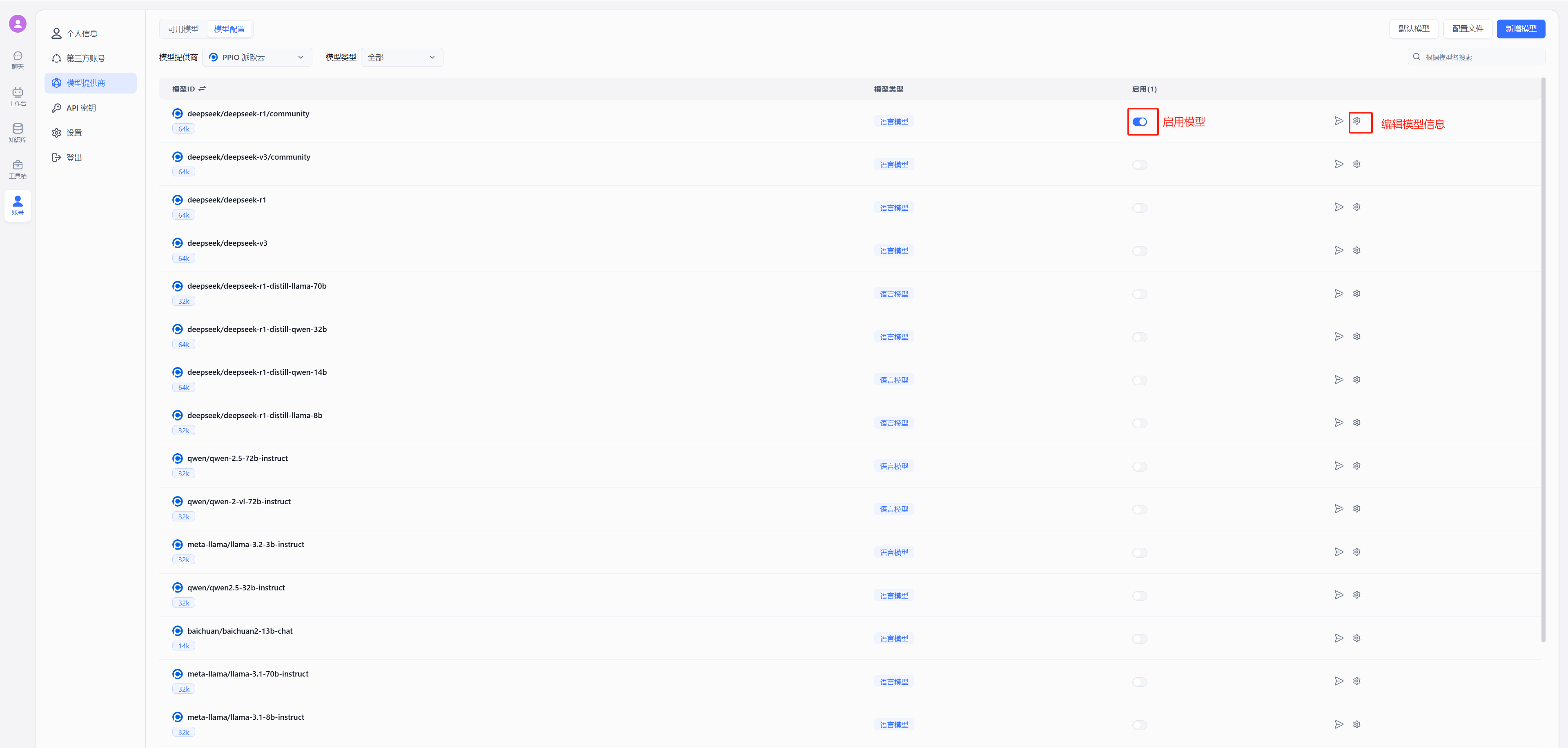
|
||||
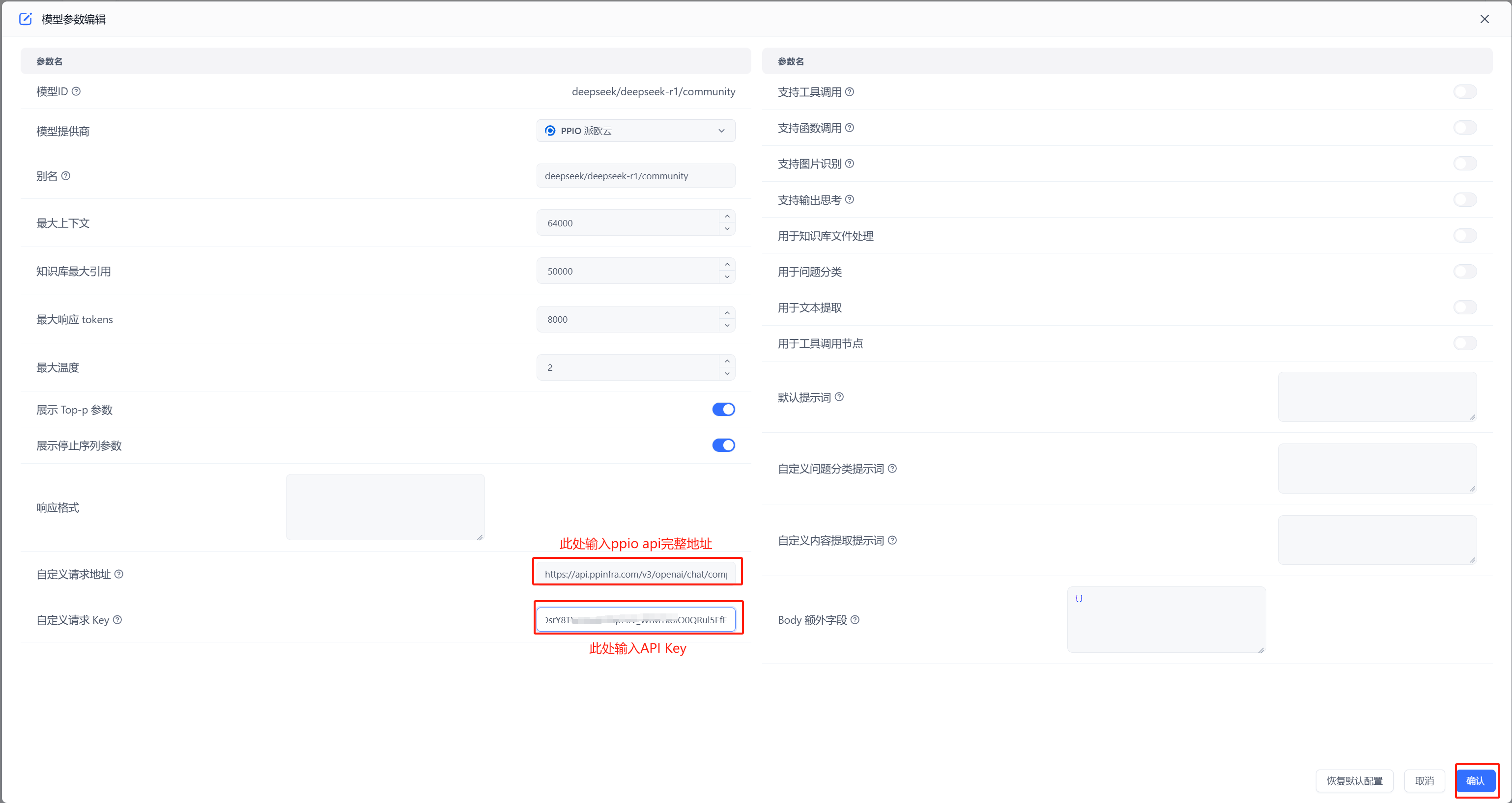
|
||||
|
||||
- 测试连通性
|
||||
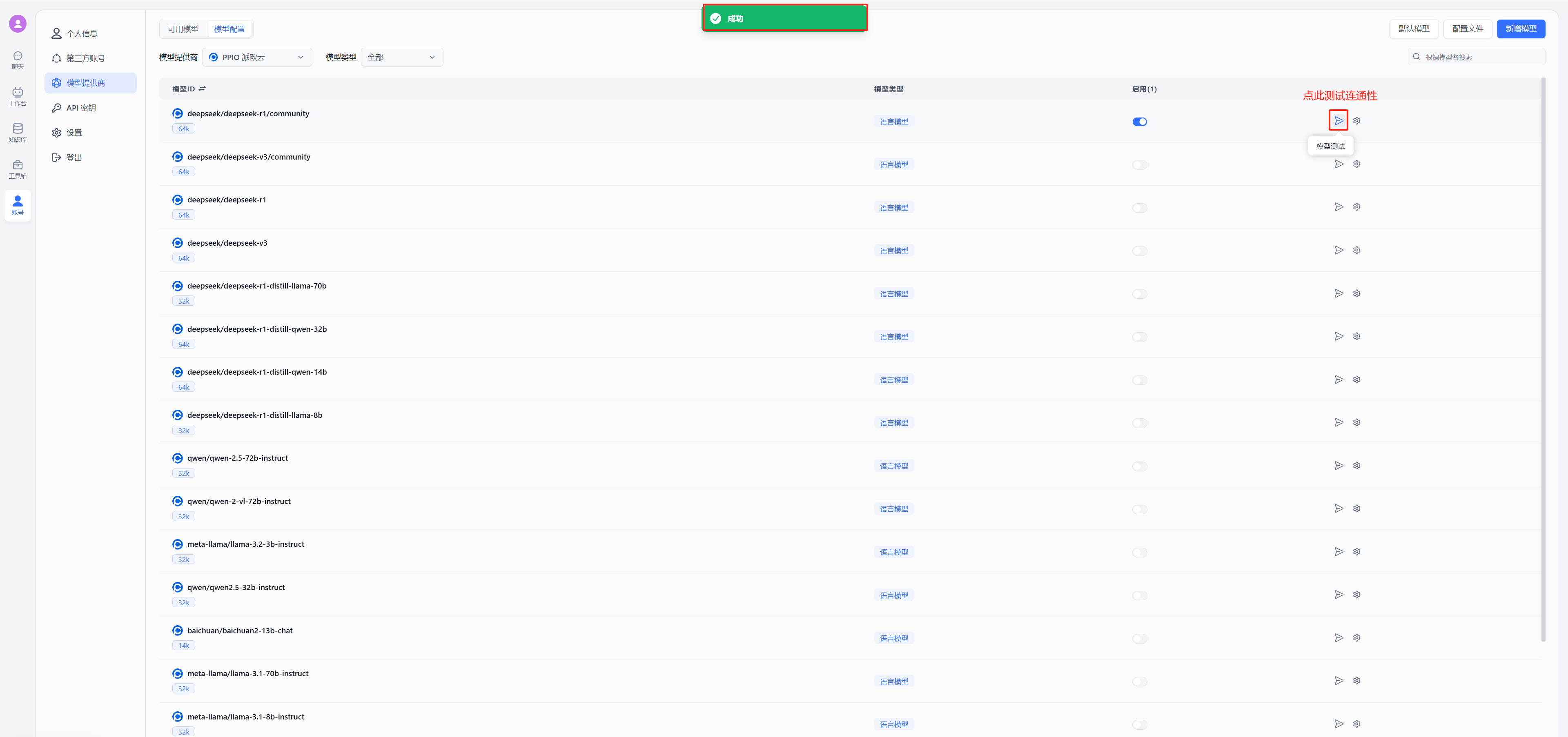
|
||||
|
||||
出现图中绿色的的成功显示证明连通成功,可以进行对话配置
|
||||
|
||||
## 4. 配置对话
|
||||
(1)新建工作台
|
||||
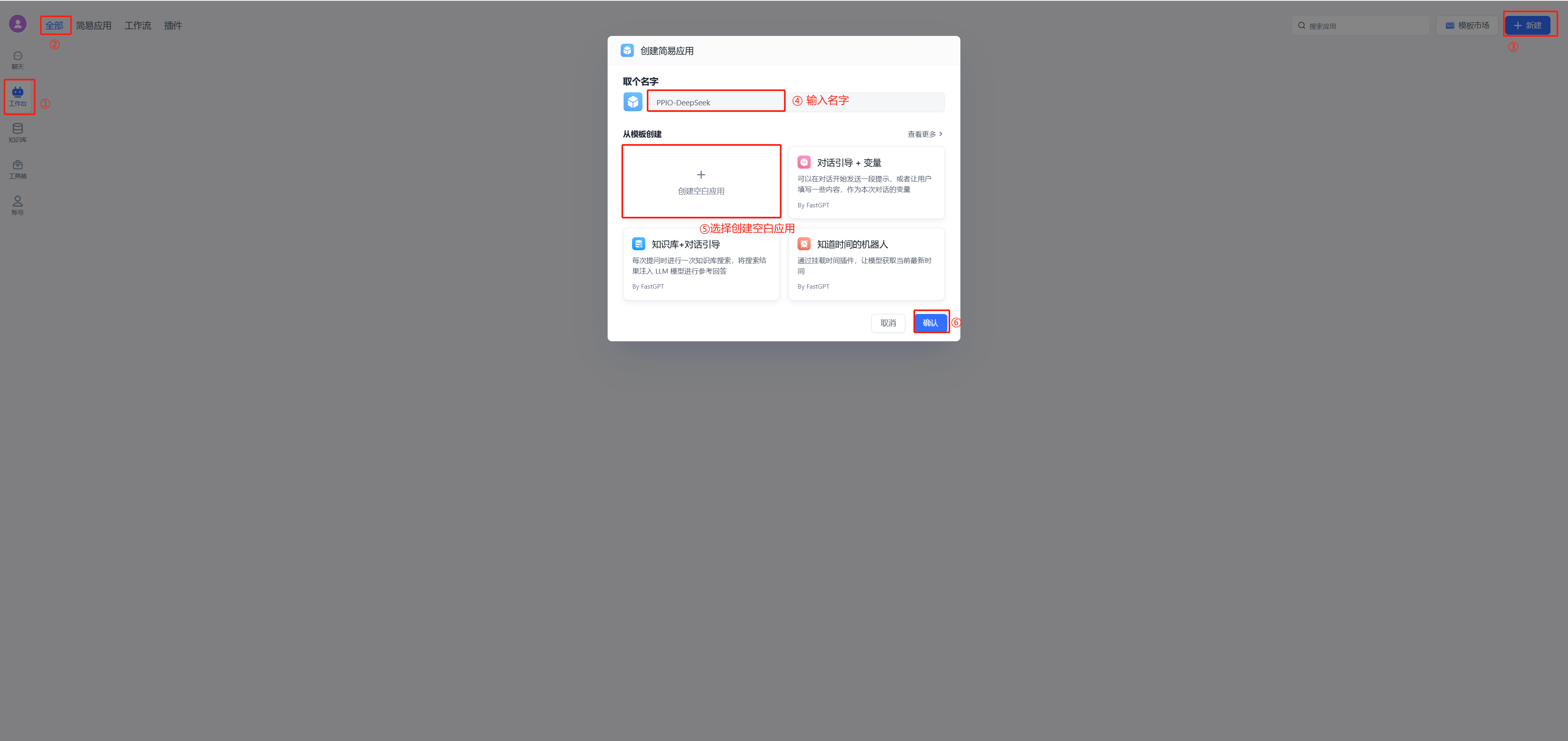
|
||||
(2)开始聊天
|
||||
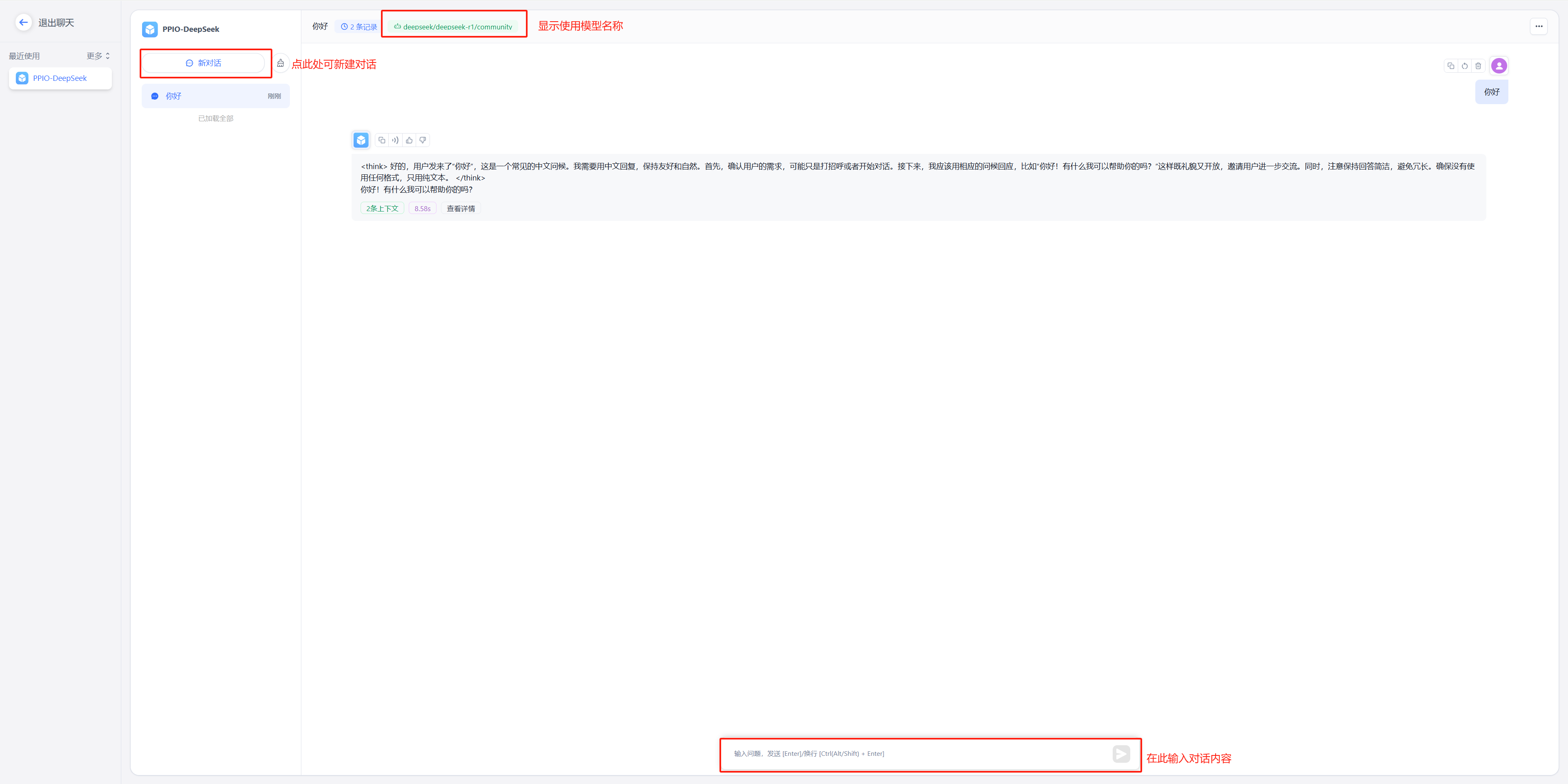
|
||||
|
||||
## PPIO 全新福利重磅来袭 🔥
|
||||
顺利完成教程配置步骤后,您将解锁两大权益:1. 畅享 PPIO 高速通道与 FastGPT 的效能组合;2.立即激活 **「新用户邀请奖励」** ————通过专属邀请码邀好友注册,您与好友可各领 50 元代金券,硬核福利助力 AI 工具效率倍增!
|
||||
|
||||
🎁 新手专享:立即使用邀请码【VOJL20】完成注册,50 元代金券奖励即刻到账!
|
||||
@@ -18,12 +18,14 @@ weight: 852
|
||||
{{% alert icon="🤖 " context="success" %}}
|
||||
* 该接口的 API Key 需使用`应用特定的 key`,否则会报错。
|
||||
|
||||
<!-- * 对话现在有`v1`和`v2`两个接口,可以按需使用,v2 自 4.9.4 版本新增,v1 接口同时不再维护 -->
|
||||
|
||||
* 有些包调用时,`BaseUrl`需要添加`v1`路径,有些不需要,如果出现404情况,可补充`v1`重试。
|
||||
{{% /alert %}}
|
||||
|
||||
## 请求简易应用和工作流
|
||||
|
||||
对话接口兼容`GPT`的接口!如果你的项目使用的是标准的`GPT`官方接口,可以直接通过修改`BaseUrl`和 `Authorization`来访问 FastGpt 应用,不过需要注意下面几个规则:
|
||||
`v1`对话接口兼容`GPT`的接口!如果你的项目使用的是标准的`GPT`官方接口,可以直接通过修改`BaseUrl`和 `Authorization`来访问 FastGpt 应用,不过需要注意下面几个规则:
|
||||
|
||||
{{% alert icon="🤖 " context="success" %}}
|
||||
* 传入的`model`,`temperature`等参数字段均无效,这些字段由编排决定,不会根据 API 参数改变。
|
||||
@@ -65,7 +67,7 @@ curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
|
||||
{{< markdownify >}}
|
||||
|
||||
* 仅`messages`有部分区别,其他参数一致。
|
||||
* 目前不支持上次文件,需上传到自己的对象存储中,获取对应的文件链接。
|
||||
* 目前不支持上传文件,需上传到自己的对象存储中,获取对应的文件链接。
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
|
||||
@@ -116,14 +118,284 @@ curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
|
||||
- variables: 模块变量,一个对象,会替换模块中,输入框内容里的`{{key}}`
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
<!-- #### v2
|
||||
|
||||
v1,v2 接口请求参数一致,仅请求地址不一样。
|
||||
|
||||
{{< tabs tabTotal="3" >}}
|
||||
{{< tab tabName="基础请求示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'http://localhost:3000/api/v2/chat/completions' \
|
||||
--header 'Authorization: fastgpt-xxxxxx' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{
|
||||
"chatId": "my_chatId",
|
||||
"stream": false,
|
||||
"detail": false,
|
||||
"responseChatItemId": "my_responseChatItemId",
|
||||
"variables": {
|
||||
"uid": "asdfadsfasfd2323",
|
||||
"name": "张三"
|
||||
},
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "你是谁"
|
||||
}
|
||||
]
|
||||
}'
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="图片/文件请求示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
* 仅`messages`有部分区别,其他参数一致。
|
||||
* 目前不支持上传文件,需上传到自己的对象存储中,获取对应的文件链接。
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'http://localhost:3000/api/v2/chat/completions' \
|
||||
--header 'Authorization: Bearer fastgpt-xxxxxx' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{
|
||||
"chatId": "abcd",
|
||||
"stream": false,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
{
|
||||
"type": "text",
|
||||
"text": "导演是谁"
|
||||
},
|
||||
{
|
||||
"type": "image_url",
|
||||
"image_url": {
|
||||
"url": "图片链接"
|
||||
}
|
||||
},
|
||||
{
|
||||
"type": "file_url",
|
||||
"name": "文件名",
|
||||
"url": "文档链接,支持 txt md html word pdf ppt csv excel"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}'
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="参数说明" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
{{% alert context="info" %}}
|
||||
- headers.Authorization: Bearer {{apikey}}
|
||||
- chatId: string | undefined 。
|
||||
- 为 `undefined` 时(不传入),不使用 FastGpt 提供的上下文功能,完全通过传入的 messages 构建上下文。
|
||||
- 为`非空字符串`时,意味着使用 chatId 进行对话,自动从 FastGpt 数据库取历史记录,并使用 messages 数组最后一个内容作为用户问题,其余 message 会被忽略。请自行确保 chatId 唯一,长度小于250,通常可以是自己系统的对话框ID。
|
||||
- messages: 结构与 [GPT接口](https://platform.openai.com/docs/api-reference/chat/object) chat模式一致。
|
||||
- responseChatItemId: string | undefined 。如果传入,则会将该值作为本次对话的响应消息的 ID,FastGPT 会自动将该 ID 存入数据库。请确保,在当前`chatId`下,`responseChatItemId`是唯一的。
|
||||
- detail: 是否返回中间值(模块状态,响应的完整结果等),`stream模式`下会通过`event`进行区分,`非stream模式`结果保存在`responseData`中。
|
||||
- variables: 模块变量,一个对象,会替换模块中,输入框内容里的`{{key}}`
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
#### v1
|
||||
|
||||
|
||||
|
||||
### 响应
|
||||
|
||||
#### v2
|
||||
|
||||
v2 接口比起 v1,主要变变化在于:会在每个节点运行结束后及时返回 response,而不是等工作流结束后再统一返回。
|
||||
|
||||
{{< tabs tabTotal="5" >}}
|
||||
{{< tab tabName="detail=false,stream=false 响应" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "",
|
||||
"model": "",
|
||||
"usage": {
|
||||
"prompt_tokens": 1,
|
||||
"completion_tokens": 1,
|
||||
"total_tokens": 1
|
||||
},
|
||||
"choices": [
|
||||
{
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "我是一个人工智能助手,旨在回答问题和提供信息。如果你有任何问题或者需要帮助,随时问我!"
|
||||
},
|
||||
"finish_reason": "stop",
|
||||
"index": 0
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="detail=false,stream=true 响应" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
|
||||
```bash
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"你好"},"index":0,"finish_reason":null}]}
|
||||
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"!"},"index":0,"finish_reason":null}]}
|
||||
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"今天"},"index":0,"finish_reason":null}]}
|
||||
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"过得怎么样?"},"index":0,"finish_reason":null}]}
|
||||
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":null},"index":0,"finish_reason":"stop"}]}
|
||||
|
||||
data: [DONE]
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="detail=true,stream=false 响应" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```json
|
||||
{
|
||||
"responseData": [
|
||||
{
|
||||
"id": "iSol79OFrBH1I9kC",
|
||||
"nodeId": "448745",
|
||||
"moduleName": "common:core.module.template.work_start",
|
||||
"moduleType": "workflowStart",
|
||||
"runningTime": 0
|
||||
},
|
||||
{
|
||||
"id": "t1T94WCy6Su3BK4V",
|
||||
"nodeId": "fjLpE3XPegmoGtbU",
|
||||
"moduleName": "AI 对话",
|
||||
"moduleType": "chatNode",
|
||||
"runningTime": 1.46,
|
||||
"totalPoints": 0,
|
||||
"model": "GPT-4o-mini",
|
||||
"tokens": 64,
|
||||
"inputTokens": 10,
|
||||
"outputTokens": 54,
|
||||
"query": "你是谁",
|
||||
"reasoningText": "",
|
||||
"historyPreview": [
|
||||
{
|
||||
"obj": "Human",
|
||||
"value": "你是谁"
|
||||
},
|
||||
{
|
||||
"obj": "AI",
|
||||
"value": "我是一个人工智能助手,旨在帮助回答问题和提供信息。如果你有任何问题或需要帮助,请告诉我!"
|
||||
}
|
||||
],
|
||||
"contextTotalLen": 2
|
||||
}
|
||||
],
|
||||
"newVariables": {
|
||||
|
||||
},
|
||||
"id": "",
|
||||
"model": "",
|
||||
"usage": {
|
||||
"prompt_tokens": 1,
|
||||
"completion_tokens": 1,
|
||||
"total_tokens": 1
|
||||
},
|
||||
"choices": [
|
||||
{
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "我是一个人工智能助手,旨在帮助回答问题和提供信息。如果你有任何问题或需要帮助,请告诉我!"
|
||||
},
|
||||
"finish_reason": "stop",
|
||||
"index": 0
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
|
||||
{{< tab tabName="detail=true,stream=true 响应" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```bash
|
||||
event: flowNodeResponse
|
||||
data: {"id":"iYv2uA9rCWAtulWo","nodeId":"workflowStartNodeId","moduleName":"流程开始","moduleType":"workflowStart","runningTime":0}
|
||||
|
||||
event: flowNodeStatus
|
||||
data: {"status":"running","name":"AI 对话"}
|
||||
|
||||
event: answer
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"你好"},"index":0,"finish_reason":null}]}
|
||||
|
||||
event: answer
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"!"},"index":0,"finish_reason":null}]}
|
||||
|
||||
event: answer
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"今天"},"index":0,"finish_reason":null}]}
|
||||
|
||||
event: answer
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"过得怎么样?"},"index":0,"finish_reason":null}]}
|
||||
|
||||
event: flowNodeResponse
|
||||
data: {"id":"pVzLBF7M3Ol4n7s6","nodeId":"ixe20AHN3jy74pKf","moduleName":"AI 对话","moduleType":"chatNode","runningTime":1.48,"totalPoints":0.0042,"model":"Qwen-plus","tokens":28,"inputTokens":8,"outputTokens":20,"query":"你好","reasoningText":"","historyPreview":[{"obj":"Human","value":"你好"},{"obj":"AI","value":"你好!今天过得怎么样?"}],"contextTotalLen":2}
|
||||
|
||||
event: answer
|
||||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":null},"index":0,"finish_reason":"stop"}]}
|
||||
|
||||
event: answer
|
||||
data: [DONE]
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="event值" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
event取值:
|
||||
|
||||
- answer: 返回给客户端的文本(最终会算作回答)
|
||||
- fastAnswer: 指定回复返回给客户端的文本(最终会算作回答)
|
||||
- toolCall: 执行工具
|
||||
- toolParams: 工具参数
|
||||
- toolResponse: 工具返回
|
||||
- flowNodeStatus: 运行到的节点状态
|
||||
- flowNodeResponse: 单个节点详细响应
|
||||
- updateVariables: 更新变量
|
||||
- error: 报错
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
#### v1 -->
|
||||
|
||||
{{< tabs tabTotal="5" >}}
|
||||
{{< tab tabName="detail=false,stream=false 响应" >}}
|
||||
{{< markdownify >}}
|
||||
@@ -648,8 +920,6 @@ event取值:
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
|
||||
|
||||
# 对话 CRUD
|
||||
|
||||
{{% alert icon="🤖 " context="success" %}}
|
||||
|
||||
@@ -11,8 +11,6 @@ weight: 853
|
||||
| --------------------- | --------------------- |
|
||||
|  |  |
|
||||
|
||||
|
||||
|
||||
## 创建训练订单
|
||||
|
||||
{{< tabs tabTotal="2" >}}
|
||||
@@ -289,7 +287,7 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?
|
||||
|
||||
## 集合
|
||||
|
||||
### 通用创建参数说明
|
||||
### 通用创建参数说明(必看)
|
||||
|
||||
**入参**
|
||||
|
||||
@@ -300,8 +298,11 @@ curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?
|
||||
| trainingType | 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 | ✅ |
|
||||
| autoIndexes | 是否自动生成索引(仅商业版支持) | |
|
||||
| imageIndex | 是否自动生成图片索引(仅商业版支持) | |
|
||||
| chunkSize | 预估块大小 | |
|
||||
| chunkSplitter | 自定义最高优先分割符号 | |
|
||||
| chunkSettingMode | 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 | |
|
||||
| chunkSplitMode | 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 | |
|
||||
| chunkSize | 分块大小,默认 1500。chunkSettingMode=auto时不生效。 | |
|
||||
| indexSize | 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 | |
|
||||
| chunkSplitter | 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 | |
|
||||
| qaPrompt | qa拆分提示词 | |
|
||||
| tags | 集合标签(字符串数组) | |
|
||||
| createTime | 文件创建时间(Date / String) | |
|
||||
@@ -389,9 +390,8 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
"name":"测试训练",
|
||||
|
||||
"trainingType": "qa",
|
||||
"chunkSize":8000,
|
||||
"chunkSplitter":"",
|
||||
"qaPrompt":"11",
|
||||
"chunkSettingMode": "auto",
|
||||
"qaPrompt":"",
|
||||
|
||||
"metadata":{}
|
||||
}'
|
||||
@@ -409,10 +409,6 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
- parentId: 父级ID,不填则默认为根目录
|
||||
- name: 集合名称(必填)
|
||||
- metadata: 元数据(暂时没啥用)
|
||||
- trainingType: 训练模式(必填)
|
||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
||||
- qaPrompt: qa拆分自定义提示词(可选)
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
@@ -462,8 +458,7 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
"parentId": null,
|
||||
|
||||
"trainingType": "chunk",
|
||||
"chunkSize":512,
|
||||
"chunkSplitter":"",
|
||||
"chunkSettingMode": "auto",
|
||||
"qaPrompt":"",
|
||||
|
||||
"metadata":{
|
||||
@@ -483,10 +478,6 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
- datasetId: 知识库的ID(必填)
|
||||
- parentId: 父级ID,不填则默认为根目录
|
||||
- metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选)
|
||||
- trainingType:训练模式(必填)
|
||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
||||
- qaPrompt: qa拆分自定义提示词(可选)
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
@@ -545,13 +536,7 @@ curl --location --request POST 'http://localhost:3000/api/core/dataset/collectio
|
||||
|
||||
{{% alert icon=" " context="success" %}}
|
||||
- file: 文件
|
||||
- data: 知识库相关信息(json序列化后传入)
|
||||
- datasetId: 知识库的ID(必填)
|
||||
- parentId: 父级ID,不填则默认为根目录
|
||||
- trainingType:训练模式(必填)
|
||||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
||||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
||||
- qaPrompt: qa拆分自定义提示词(可选)
|
||||
- data: 知识库相关信息(json序列化后传入),参数说明见上方“通用创建参数说明”
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
|
||||
@@ -11,7 +11,12 @@ weight: 799
|
||||
|
||||
### 1. 做好数据库备份
|
||||
|
||||
### 2. 更新镜像和 PG 容器
|
||||
### 2. 更新镜像
|
||||
|
||||
- 更新 FastGPT 镜像 tag: v4.9.1-fix2
|
||||
- 更新 FastGPT 商业版镜像 tag: v4.9.1-fix2
|
||||
- Sandbox 镜像,可以不更新
|
||||
- AIProxy 镜像修改为: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3
|
||||
|
||||
### 3. 执行升级脚本
|
||||
|
||||
@@ -25,7 +30,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||
|
||||
**脚本功能**
|
||||
|
||||
重新使用最新的 jieba 分词库进行分词处理。
|
||||
重新使用最新的 jieba 分词库进行分词处理。时间较长,可以从日志里查看进度。
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
@@ -34,7 +39,7 @@ curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||
3. API 知识库支持 PDF 增强解析。
|
||||
4. 邀请团队成员,改为邀请链接模式。
|
||||
5. 支持混合检索权重设置。
|
||||
6. 支持重排模型选择和权重设置,同时调整了知识库搜索权重计算方式,改成 搜索权重 + 重排权重,而不是向量检索权重+全文检索权重+重排权重。
|
||||
6. 支持重排模型选择和权重设置,同时调整了知识库搜索权重计算方式,改成 搜索权重 + 重排权重,而不是向量检索权重+全文检索权重+重排权重。会对检索结果有一定影响,可以通过调整相关权重来进行数据适配。
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
@@ -57,3 +62,4 @@ curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||||
8. 修复 promp 模式工具调用,未判空思考链,导致 UI 错误展示。
|
||||
9. 编辑应用信息导致头像丢失。
|
||||
10. 分享链接标题会被刷新掉。
|
||||
11. 计算 parentPath 时,存在鉴权失败清空。
|
||||
|
||||
75
docSite/content/zh-cn/docs/development/upgrading/492.md
Normal file
@@ -0,0 +1,75 @@
|
||||
---
|
||||
title: 'V4.9.2'
|
||||
description: 'FastGPT V4.9.2 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 798
|
||||
---
|
||||
## 更新指南
|
||||
|
||||
可直接升级v4.9.3,v4.9.2存在一个工作流数据类型转化错误。
|
||||
|
||||
### 1. 做好数据库备份
|
||||
|
||||
### 2. SSO 迁移
|
||||
|
||||
使用了 SSO 或成员同步的商业版用户,并且是对接`钉钉`、`企微`的,需要迁移已有的 SSO 相关配置:
|
||||
|
||||
参考:[SSO & 外部成员同步](/docs/guide/admin/sso)中的配置进行`sso-service`的部署和配置。
|
||||
|
||||
1. 先将原商业版后台中的相关配置项复制备份出来(以企微为例,将 AppId, Secret 等复制出来)再进行镜像升级。
|
||||
2. 参考上述文档,部署 SSO 服务,配置相关的环境变量
|
||||
3. 如果原先使用企微组织架构同步的用户,升级完镜像后,需要在商业版后台切换团队模式为“同步模式”
|
||||
|
||||
### 3. 配置参数变更
|
||||
|
||||
修改`config.json`文件中`systemEnv.pgHNSWEfSearch`参数名,改成`hnswEfSearch`。
|
||||
商业版用户升级镜像后,直接在后台`系统配置-基础配置`中进行变更。
|
||||
|
||||
### 4. 更新镜像
|
||||
|
||||
- 更新 FastGPT 镜像 tag: v4.9.2
|
||||
- 更新 FastGPT 商业版镜像 tag: v4.9.2
|
||||
- Sandbox 镜像,可以不更新
|
||||
- AIProxy 镜像修改为: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.4
|
||||
|
||||
## 重要更新
|
||||
|
||||
- 知识库导入数据 API 变更,增加`chunkSettingMode`,`chunkSplitMode`,`indexSize`可选参数,具体可参考 [知识库导入数据 API](/docs/development/openapi/dataset) 文档。
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
1. 知识库分块优化:支持单独配置分块大小和索引大小,允许进行超大分块,以更大的输入 Tokens 换取完整分块。
|
||||
2. 知识库分块增加自定义分隔符预设值,同时支持自定义换行符分割。
|
||||
3. 外部变量改名:自定义变量。 并且支持在测试时调试,在分享链接中,该变量直接隐藏。
|
||||
4. 集合同步时,支持同步修改标题。
|
||||
5. 团队成员管理重构,抽离主流 IM SSO(企微、飞书、钉钉),并支持通过自定义 SSO 接入 FastGPT。同时完善与外部系统的成员同步。
|
||||
6. 支持 `oceanbase` 向量数据库。填写环境变量`OCEANBASE_URL`即可。
|
||||
7. 基于 mistral-ocr 的 PDF 解析示例。
|
||||
8. 基于 miner-u 的 PDF 解析示例。
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
1. 导出对话日志时,支持导出成员名。
|
||||
2. 邀请链接交互。
|
||||
3. 无 SSL 证书时复制失败,会提示弹窗用于手动复制。
|
||||
4. FastGPT 未内置 ai proxy 渠道时,也能正常展示其名称。
|
||||
5. 升级 nextjs 版本至 14.2.25。
|
||||
6. 工作流节点数组字符串类型,自动适配 string 输入。
|
||||
7. 工作流节点数组类型,自动进行 JSON parse 解析 string 输入。
|
||||
8. AI proxy 日志优化,去除重试失败的日志,仅保留最后一份错误日志。
|
||||
9. 个人信息和通知展示优化。
|
||||
10. 模型测试 loading 动画优化。
|
||||
11. 分块算法小调整:
|
||||
* 跨处理符号之间连续性更强。
|
||||
* 代码块分割时,用 LLM 模型上下文作为分块大小,尽可能保证代码块完整性。
|
||||
* 表格分割时,用 LLM 模型上下文作为分块大小,尽可能保证表格完整性。
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
1. 飞书和语雀知识库无法同步。
|
||||
2. 渠道测试时,如果配置了模型自定义请求地址,会走自定义请求地址,而不是渠道请求地址。
|
||||
3. 语音识别模型测试未启用的模型时,无法正常测试。
|
||||
4. 管理员配置系统插件时,如果插件包含其他系统应用,无法正常鉴权。
|
||||
5. 移除 TTS 自定义请求地址时,必须需要填 requestAuth 字段。
|
||||
29
docSite/content/zh-cn/docs/development/upgrading/493.md
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
title: 'V4.9.3'
|
||||
description: 'FastGPT V4.9.3 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 797
|
||||
---
|
||||
|
||||
## 更新指南
|
||||
|
||||
### 1. 做好数据库备份
|
||||
|
||||
### 2. 更新镜像
|
||||
|
||||
- 更新 FastGPT 镜像 tag: v4.9.3
|
||||
- 更新 FastGPT 商业版镜像 tag: v4.9.3
|
||||
- Sandbox 镜像tag: v4.9.3
|
||||
- AIProxy 镜像tag: v0.1.5
|
||||
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
1. 工作流 debug 模式支持交互节点。
|
||||
2. 代码运行支持 Python3 代码。
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
1. 工作流格式转化异常。
|
||||
66
docSite/content/zh-cn/docs/development/upgrading/494.md
Normal file
@@ -0,0 +1,66 @@
|
||||
---
|
||||
title: 'V4.9.4'
|
||||
description: 'FastGPT V4.9.4 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 796
|
||||
---
|
||||
|
||||
## 升级指南
|
||||
|
||||
### 1. 做好数据备份
|
||||
|
||||
### 2. 安装 Redis
|
||||
|
||||
* docker 部署的用户,参考最新的 `docker-compose.yml` 文件增加 Redis 配置。增加一个 redis 容器,并配置`fastgpt`,`fastgpt-pro`的环境变量,增加 `REDIS_URL` 环境变量。
|
||||
* Sealos 部署的用户,在数据库里新建一个`redis`数据库,并复制`内网地址的 connection` 作为 `redis` 的链接串。然后配置`fastgpt`,`fastgpt-pro`的环境变量,增加 `REDIS_URL` 环境变量。
|
||||
|
||||
| | | |
|
||||
| --- | --- | --- |
|
||||
|  |  |  |
|
||||
|
||||
### 3. 更新镜像 tag
|
||||
|
||||
- 更新 FastGPT 镜像 tag: v4.9.4
|
||||
- 更新 FastGPT 商业版镜像 tag: v4.9.4
|
||||
- Sandbox 无需更新
|
||||
- AIProxy 无需更新
|
||||
|
||||
### 4. 执行升级脚本
|
||||
|
||||
该脚本仅需商业版用户执行。
|
||||
|
||||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://{{host}}/api/admin/initv494' \
|
||||
--header 'rootkey: {{rootkey}}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
**脚本功能**
|
||||
|
||||
1. 更新站点同步定时器
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
1. 集合数据训练状态展示
|
||||
2. SMTP 发送邮件插件
|
||||
3. BullMQ 消息队列。
|
||||
4. 利用 redis 进行部分数据缓存。
|
||||
5. 站点同步支持配置训练参数和增量同步。
|
||||
6. AI 对话/工具调用,增加返回模型 finish_reason 字段,便于追踪模型输出中断原因。
|
||||
7. 移动端语音输入交互调整
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
1. Admin 模板渲染调整。
|
||||
2. 支持环境变量配置对话文件过期时间。
|
||||
3. MongoDB log 库可独立部署。
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
1. 搜索应用/知识库时,无法点击目录进入下一层。
|
||||
2. 重新训练时,参数未成功初始化。
|
||||
3. package/service 部分请求在多 app 中不一致。
|
||||
28
docSite/content/zh-cn/docs/development/upgrading/495.md
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
title: 'V4.9.5(进行中)'
|
||||
description: 'FastGPT V4.9.5 更新说明'
|
||||
icon: 'upgrade'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 795
|
||||
---
|
||||
|
||||
|
||||
## 🚀 新增内容
|
||||
|
||||
1. 团队成员权限细分,可分别控制是否可创建在根目录应用/知识库以及 API Key
|
||||
2. 支持交互节点在嵌套工作流中使用。
|
||||
3. 团队成员操作日志。
|
||||
|
||||
## ⚙️ 优化
|
||||
|
||||
1. 繁体中文翻译。
|
||||
|
||||
|
||||
## 🐛 修复
|
||||
|
||||
1. password 检测规则错误。
|
||||
2. 分享链接无法隐藏知识库检索结果。
|
||||
3. IOS 低版本正则兼容问题。
|
||||
4. 修复问答提取队列错误后,计数器未清零问题,导致问答提取队列失效。
|
||||
5. Debug 模式交互节点下一步可能造成死循环。
|
||||
88
docSite/content/zh-cn/docs/guide/DialogBoxes/quoteList.md
Normal file
@@ -0,0 +1,88 @@
|
||||
---
|
||||
title: '知识库引用分块阅读器'
|
||||
description: 'FastGPT 分块阅读器功能介绍'
|
||||
icon: 'description'
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 480
|
||||
---
|
||||
在企业 AI 应用落地过程中,文档知识引用的精确性和透明度一直是用户关注的焦点。FastGPT 4.9.1 版本带来的知识库分块阅读器,巧妙解决了这一痛点,让 AI 引用不再是"黑盒"。
|
||||
|
||||
# 为什么需要分块阅读器?
|
||||
|
||||
传统的 AI 对话中,当模型引用企业知识库内容时,用户往往只能看到被引用的片段,无法获取完整语境,这给内容验证和深入理解带来了挑战。分块阅读器的出现,让用户可以在对话中直接查看引用内容的完整文档,并精确定位到引用位置,实现了引用的"可解释性"。
|
||||
|
||||
## 传统引用体验的局限
|
||||
|
||||
以往在知识库中上传文稿后,当我们在工作流中输入问题时,传统的引用方式只会展示引用到的分块,无法确认分块在文章中的上下文:
|
||||
|
||||
| 问题 | 引用 |
|
||||
| --- | --- |
|
||||
|  |  |
|
||||
|
||||
## FastGPT 分块阅读器:精准定位,无缝阅读
|
||||
|
||||
而在 FastGPT 全新的分块式阅读器中,同样的知识库内容和问题,呈现方式发生了质的飞跃
|
||||
|
||||

|
||||
|
||||
当 AI 引用知识库内容时,用户只需点击引用链接,即可打开一个浮窗,呈现完整的原文内容,并通过醒目的高亮标记精确显示引用的文本片段。这既保证了回答的可溯源性,又提供了便捷的原文查阅体验。
|
||||
|
||||
# 核心功能
|
||||
|
||||
## 全文展示与定位
|
||||
|
||||
"分块阅读器" 让用户能直观查看AI回答引用的知识来源。
|
||||
|
||||
在对话界面中,当 AI 引用了知识库内容,系统会在回复下方展示出处信息。用户只需点击这些引用链接,即可打开一个优雅的浮窗,呈现完整的原文内容,并通过醒目的高亮标记精确显示 AI 引用的文本片段。
|
||||
|
||||
这一设计既保证了回答的可溯源性,又提供了便捷的原文查阅体验,让用户能轻松验证AI回答的准确性和相关上下文。
|
||||
|
||||

|
||||
|
||||
|
||||
## 便捷引用导航
|
||||
|
||||
分块阅读器右上角设计了简洁实用的导航控制,用户可以通过这对按钮轻松在多个引用间切换浏览。导航区还直观显示当前查看的引用序号及总引用数量(如 "7/10"),帮助用户随时了解浏览进度和引用内容的整体规模。
|
||||
|
||||

|
||||
|
||||
## 引用质量评分
|
||||
|
||||
每条引用内容旁边都配有智能评分标签,直观展示该引用在所有知识片段中的相关性排名。用户只需将鼠标悬停在评分标签上,即可查看完整的评分详情,了解这段引用内容为何被AI选中以及其相关性的具体构成。
|
||||
|
||||

|
||||
|
||||
|
||||
## 文档内容一键导出
|
||||
|
||||
分块阅读器贴心配备了内容导出功能,让有效信息不再流失。只要用户拥有相应知识库的阅读权限,便可通过简单点击将引用涉及的全文直接保存到本地设备。
|
||||
|
||||

|
||||
|
||||
# 进阶特性
|
||||
|
||||
## 灵活的可见度控制
|
||||
|
||||
FastGPT提供灵活的引用可见度设置,让知识共享既开放又安全。以免登录链接为例,管理员可精确控制外部访问者能看到的信息范围。
|
||||
|
||||
当设置为"仅引用内容可见"时,外部用户点击引用链接将只能查看 AI 引用的特定文本片段,而非完整原文档。如图所示,分块阅读器此时智能调整显示模式,仅呈现相关引用内容。
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
|  |  |
|
||||
|
||||
## 即时标注优化
|
||||
|
||||
在浏览过程中,授权用户可以直接对引用内容进行即时标注和修正,系统会智能处理这些更新而不打断当前的对话体验。所有修改过的内容会通过醒目的"已更新"标签清晰标识,既保证了引用的准确性,又维持了对话历史的完整性。
|
||||
|
||||
这一无缝的知识优化流程特别适合团队协作场景,让知识库能在实际使用过程中持续进化,确保AI回答始终基于最新、最准确的信息源。
|
||||
|
||||
## 智能文档性能优化
|
||||
|
||||
面对现实业务中可能包含成千上万分块的超长文档,FastGPT采用了先进的性能优化策略,确保分块阅读器始终保持流畅响应。
|
||||
|
||||
系统根据引用相关性排序和数据库索引进行智能加载管理,实现了"按需渲染"机制——根据索引排序和数据库 id,只有当用户实际需要查看的内容才会被加载到内存中。这意味着无论是快速跳转到特定引用,还是自然滚动浏览文档,都能获得丝滑的用户体验,不会因为文档体积庞大而出现卡顿或延迟。
|
||||
|
||||
这一技术优化使FastGPT能够轻松应对企业级的大规模知识库场景,让即使是包含海量信息的专业文档也能高效展示和查阅。
|
||||
|
||||
581
docSite/content/zh-cn/docs/guide/admin/sso.md
Normal file
@@ -0,0 +1,581 @@
|
||||
---
|
||||
title: 'SSO & 外部成员同步'
|
||||
description: 'FastGPT 外部成员系统接入设计与配置'
|
||||
icon: ''
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 707
|
||||
---
|
||||
|
||||
如果你不需要用到 SSO/成员同步功能,或者是只需要用 Github、google、microsoft、公众号的快速登录,可以跳过本章节。本章适合需要接入自己的成员系统或主流 办公IM 的用户。
|
||||
|
||||
## 介绍
|
||||
|
||||
为了方便地接入**外部成员系统**,FastGPT 提供一套接入外部系统的**标准接口**,以及一个 FastGPT-SSO-Service 镜像作为**适配器**。
|
||||
|
||||
通过这套标注接口,你可以可以实现:
|
||||
|
||||
1. SSO 登录。从外部系统回调后,在 FastGPT 中创建一个用户。
|
||||
2. 成员和组织架构同步(下面都简称成员同步)。
|
||||
|
||||
**原理**
|
||||
|
||||
FastGPT-pro 中,有一套标准的SSO 和成员同步接口,系统会根据这套接口进行 SSO 和成员同步操作。
|
||||
|
||||
FastGPT-SSO-Service 是为了聚合不同来源的 SSO 和成员同步接口,将他们转成 fastgpt-pro 可识别的接口。
|
||||
|
||||

|
||||
|
||||
## 系统配置教程
|
||||
|
||||
### 1. 部署 SSO-service 镜像
|
||||
|
||||
使用 docker-compose 部署:
|
||||
|
||||
```yaml
|
||||
fastgpt-sso:
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||||
container_name: fastgpt-sso
|
||||
restart: always
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
- SSO_PROVIDER=example
|
||||
- AUTH_TOKEN=xxxxx # 鉴权信息,fastgpt-pro 会用到。
|
||||
# 具体对接提供商的环境变量。
|
||||
```
|
||||
|
||||
根据不同的提供商,你需要配置不同的环境变量,下面是内置的通用协议/IM:
|
||||
|
||||
{{< table "table-hover table-striped-columns" >}}
|
||||
| 协议/功能 | SSO | 成员同步支持 |
|
||||
|----------------|----------|--------------|
|
||||
| 飞书 | 是 | 是 |
|
||||
| 企业微信 | 是 | 是 |
|
||||
| 钉钉 | 是 | 否 |
|
||||
| Saml2.0 | 是 | 否 |
|
||||
| Oauth2.0 | 是 | 否 |
|
||||
{{< /table >}}
|
||||
|
||||
### 2. 配置 fastgpt-pro
|
||||
|
||||
#### 1. 配置环境变量
|
||||
|
||||
环境变量中的 `EXTERNAL_USER_SYSTEM_BASE_URL` 为内网地址,例如上述例子中的配置,环境变量应该设置为
|
||||
|
||||
```yaml
|
||||
env:
|
||||
- EXTERNAL_USER_SYSTEM_BASE_URL=http://fastgpt-sso:3000
|
||||
- EXTERNAL_USER_SYSTEM_AUTH_TOKEN=xxxxx
|
||||
```
|
||||
|
||||
#### 2. 在商业版后台配置按钮文字,图标等。
|
||||
|
||||
{{< table "table-hover table-striped-columns" >}}
|
||||
| <div style="text-align:center">企业微信</div> | <div style="text-align:center">钉钉</div> | <div style="text-align:center">飞书</div> |
|
||||
|-----------|-----------------|--------------|
|
||||
|  |  |  |
|
||||
{{< /table >}}
|
||||
|
||||
#### 3. 开启成员同步(可选)
|
||||
|
||||
如果需要同步外部系统的成员,可以选择开启成员同步。团队模式具体可参考:[团队模式说明文档](/docs/guide/admin/teamMode)
|
||||
|
||||

|
||||
|
||||
#### 4. 可选配置
|
||||
|
||||
1. 自动定时成员同步
|
||||
|
||||
设置 fastgpt-pro 环境变量则可开启自动成员同步
|
||||
|
||||
```bash
|
||||
env:
|
||||
- "SYNC_MEMBER_CRON=0 0 * * *" # Cron 表达式,每天 0 点执行
|
||||
```
|
||||
|
||||
## 内置的通用协议/IM 配置示例
|
||||
|
||||
### 飞书
|
||||
|
||||
#### 1. 参数获取
|
||||
|
||||
App ID和App Secret
|
||||
|
||||
进入开发者后台,点击企业自建应用,在凭证与基础信息页面查看应用凭证。
|
||||
|
||||

|
||||
|
||||
#### 2. 权限配置
|
||||
|
||||
进入开发者后台,点击企业自建应用,在开发配置的权限管理页面开通权限。
|
||||
|
||||

|
||||
|
||||
对于开通用户SSO登录而言,开启用户身份权限的以下内容
|
||||
|
||||
1. ***获取通讯录基本信息***
|
||||
2. ***获取用户基本信息***
|
||||
3. ***获取用户邮箱信息***
|
||||
4. ***获取用户 user ID***
|
||||
|
||||
对于开启企业同步相关内容而言,开启身份权限的内容与上面一致,但要注意是开启应用权限
|
||||
|
||||
#### 3. 重定向URL
|
||||
|
||||
进入开发者后台,点击企业自建应用,在开发配置的安全设置中设置重定向URL
|
||||

|
||||
|
||||
#### 4. yml 配置示例
|
||||
|
||||
```bash
|
||||
fastgpt-sso:
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||||
container_name: fastgpt-sso
|
||||
restart: always
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
- SSO_PROVIDER=example
|
||||
- AUTH_TOKEN=xxxxx
|
||||
# 飞书 - feishu -如果是私有化部署,这里的配置前缀可能会有变化
|
||||
- SSO_PROVIDER=feishu
|
||||
# oauth 接口(公开的飞书不用改)
|
||||
- SSO_TARGET_URL=https://accounts.feishu.cn/open-apis/authen/v1/authorize
|
||||
# 获取token 接口(公开的飞书不用改)
|
||||
- FEISHU_TOKEN_URL=https://open.feishu.cn/open-apis/authen/v2/oauth/token
|
||||
# 获取用户信息接口(公开的飞书不用改)
|
||||
- FEISHU_GET_USER_INFO_URL=https://open.feishu.cn/open-apis/authen/v1/user_info
|
||||
# 重定向地址,因为飞书获取用户信息要校验所以需要填
|
||||
- FEISHU_REDIRECT_URI=xxx
|
||||
#飞书APP的应用ID,一般以cli开头
|
||||
- FEISHU_APP_ID=xxx
|
||||
#飞书APP的应用密钥
|
||||
- FEISHU_APP_SECRET=xxx
|
||||
```
|
||||
|
||||
### 钉钉
|
||||
|
||||
#### 1. 参数获取
|
||||
|
||||
CLIENT_ID 与 CLIENT_SECRET
|
||||
|
||||
进入钉钉开放平台,点击应用开发,选择自己的应用进入,记录在凭证与基础信息页面下的Client ID与Client secret。
|
||||

|
||||
|
||||
#### 2. 权限配置
|
||||
|
||||
进入钉钉开放平台,点击应用开发,选择自己的应用进入,在开发配置的权限管理页面操作,需要开通的权限包括:
|
||||
|
||||
1. ***个人手机号信息***
|
||||
2. ***通讯录个人信息读权限***
|
||||
3. ***获取钉钉开放接口用户访问凭证的基础权限***
|
||||
|
||||
#### 3. 重定向URL
|
||||
|
||||
进入钉钉开放平台,点击应用开发,选择自己的应用进入,在开发配置的安全设置页面操作
|
||||
需要填写的内容有两个:
|
||||
|
||||
1. 服务器出口IP (调用钉钉服务端API的服务器IP列表)
|
||||
2. 重定向URL(回调域名)
|
||||
|
||||
#### 4. yml 配置示例
|
||||
|
||||
```bash
|
||||
fastgpt-sso:
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||||
container_name: fastgpt-sso
|
||||
restart: always
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
- SSO_PROVIDER=dingtalk
|
||||
- AUTH_TOKEN=xxxxx
|
||||
#oauth 接口
|
||||
- SSO_TARGET_URL=https://login.dingtalk.com/oauth2/auth
|
||||
#获取token 接口
|
||||
- DINGTALK_TOKEN_URL=https://api.dingtalk.com/v1.0/oauth2/userAccessToken
|
||||
#获取用户信息接口
|
||||
- DINGTALK_GET_USER_INFO_URL=https://oapi.dingtalk.com/v1.0/contact/users/me
|
||||
#钉钉APP的应用ID
|
||||
- DINGTALK_CLIENT_ID=xxx
|
||||
#钉钉APP的应用密钥
|
||||
- DINGTALK_CLIENT_SECRET=xxx
|
||||
```
|
||||
|
||||
### 企业微信
|
||||
|
||||
#### 1. 参数获取
|
||||
|
||||
1. 企业的 CorpID
|
||||
|
||||
a. 使用管理员账号登陆企业微信管理后台 `https://work.weixin.qq.com/wework_admin/loginpage_wx`
|
||||
|
||||
b. 点击 【我的企业】 页面,查看企业的 **企业ID**
|
||||
|
||||

|
||||
|
||||
2. 创建一个供 FastGPT 使用的内部应用:
|
||||
|
||||
a. 获取应用的 AgentID 和 Secret
|
||||
|
||||
b. 保证这个应用的可见范围为全部(也就是根部门)
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
3. 一个域名。并且要求:
|
||||
|
||||
a. 解析到可公网访问的服务器上
|
||||
|
||||
b. 可以在该服务的根目录地址上挂载静态文件(以便进行域名归属认证 ,按照配置处的提示进行操作,只需要挂载一个静态文件,认证后可以删除)
|
||||
|
||||
c. 配置网页授权,JS-SDK以及企业微信授权登陆
|
||||
|
||||
d. 可以在【企业微信授权登陆】页面下方设置“在工作台隐藏应用”
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
4. 获取 “通讯录同步助手” secret
|
||||
|
||||
获取通讯录,组织成员 ID 需要使用 “通讯录同步助手” secret
|
||||
|
||||
【安全与管理】-- 【管理工具】 -- 【通讯录同步】
|
||||
|
||||

|
||||
|
||||
5. 开启接口同步
|
||||
|
||||
6. 获取 Secret
|
||||
|
||||
7. 配置企业可信 IP
|
||||
|
||||

|
||||
|
||||
#### 2. yml 配置示例
|
||||
|
||||
```bash
|
||||
fastgpt-sso:
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||||
container_name: fastgpt-sso
|
||||
restart: always
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
- AUTH_TOKEN=xxxxx
|
||||
- SSO_PROVIDER=wecom
|
||||
# oauth 接口,在企微终端使用
|
||||
- WECOM_TARGET_URL_OAUTH=https://open.weixin.qq.com/connect/oauth2/authorize
|
||||
# sso 接口,扫码
|
||||
- WECOM_TARGET_URL_SSO=https://login.work.weixin.qq.com/wwlogin/sso/login
|
||||
# 获取用户id(只能拿id)
|
||||
- WECOM_GET_USER_ID_URL=https://qyapi.weixin.qq.com/cgi-bin/auth/getuserinfo
|
||||
# 获取用户详细信息(除了名字都有)
|
||||
- WECOM_GET_USER_INFO_URL=https://qyapi.weixin.qq.com/cgi-bin/auth/getuserdetail
|
||||
# 获取用户信息(有名字,没其他信息)
|
||||
- WECOM_GET_USER_NAME_URL=https://qyapi.weixin.qq.com/cgi-bin/user/get
|
||||
# 获取组织 id 列表
|
||||
- WECOM_GET_DEPARTMENT_LIST_URL=https://qyapi.weixin.qq.com/cgi-bin/department/list
|
||||
# 获取用户 id 列表
|
||||
- WECOM_GET_USER_LIST_URL=https://qyapi.weixin.qq.com/cgi-bin/user/list_id
|
||||
# 企微 CorpId
|
||||
- WECOM_CORPID=
|
||||
# 企微 App 的 AgentId 一般是 1000xxx
|
||||
- WECOM_AGENTID=
|
||||
# 企微 App 的 Secret
|
||||
- WECOM_APP_SECRET=
|
||||
# 通讯录同步助手的 Secret
|
||||
- WECOM_SYNC_SECRET=
|
||||
```
|
||||
|
||||
### 标准 OAuth2.0
|
||||
|
||||
#### 参数需求
|
||||
|
||||
我们提供一套标准的 OAuth2.0 接入流程。需要三个地址:
|
||||
|
||||
1. 登陆鉴权地址(登陆后将 code 传入 redirect_uri)
|
||||
- 需要将地址完整写好,除了 redirect_uri 以外(会自动补全)
|
||||
2. 获取 access_token 的地址,请求为 GET 方法,参数 code
|
||||
|
||||
```bash
|
||||
http://example.com/oauth/access_token?code=xxxx
|
||||
```
|
||||
|
||||
3. 获取用户信息的地址
|
||||
|
||||
```bash
|
||||
http://example.com/oauth/user_info
|
||||
|
||||
```
|
||||
|
||||
#### 配置示例
|
||||
|
||||
```bash
|
||||
fastgpt-sso:
|
||||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||||
container_name: fastgpt-sso
|
||||
restart: always
|
||||
networks:
|
||||
- fastgpt
|
||||
environment:
|
||||
# OAuth2.0
|
||||
- AUTH_TOKEN=xxxxx
|
||||
- SSO_PROVIDER=oauth2
|
||||
# OAuth2 重定向地址
|
||||
- OAUTH2_AUTHORIZE_URL=
|
||||
# OAuth2 获取 AccessToken 地址
|
||||
- OAUTH2_TOKEN_URL=
|
||||
# OAuth2 获取用户信息地址
|
||||
- OAUTH2_USER_INFO_URL=
|
||||
# OAuth2 用户名字段映射(必填)
|
||||
- OAUTH2_USERNAME_MAP=
|
||||
# OAuth2 头像字段映射(选填)
|
||||
- OAUTH2_AVATAR_MAP=
|
||||
# OAuth2 成员名字段映射(选填)
|
||||
- OAUTH2_MEMBER_NAME_MAP=
|
||||
# OAuth2 联系方式字段映射(选填)
|
||||
- OAUTH2_CONTACT_MAP=
|
||||
```
|
||||
|
||||
## 标准接口文档
|
||||
|
||||
以下是 FastGPT-pro 中,SSO 和成员同步的标准接口文档,如果需要对接非标准系统,可以参考该章节进行开发。
|
||||
|
||||

|
||||
|
||||
FastGPT 提供如下标准接口支持:
|
||||
|
||||
1. https://example.com/login/oauth/getAuthURL 获取鉴权重定向地址
|
||||
2. https://example.com/login/oauth/getUserInfo?code=xxxxx 消费 code,换取用户信息
|
||||
3. https://example.com/org/list 获取组织列表
|
||||
4. https://example.com/user/list 获取成员列表
|
||||
|
||||
### 获取 SSO 登录重定向地址
|
||||
|
||||
返回一个重定向登录地址,fastgpt 会自动重定向到该地址。redirect_uri 会自动拼接到该地址的 query中。
|
||||
|
||||
{{< tabs tabTotal="2" >}}
|
||||
{{< tab tabName="请求示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```bash
|
||||
curl -X GET "https://redict.example/login/oauth/getAuthURL?redirect_uri=xxx&state=xxxx" \
|
||||
-H "Authorization: Bearer your_token_here" \
|
||||
-H "Content-Type: application/json"
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="响应示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
成功:
|
||||
|
||||
```JSON
|
||||
{
|
||||
"success": true,
|
||||
"message": "",
|
||||
"authURL": "https://example.com/somepath/login/oauth?redirect_uri=https%3A%2F%2Ffastgpt.cn%2Flogin%2Fprovider%0A"
|
||||
}
|
||||
```
|
||||
|
||||
失败:
|
||||
|
||||
```JSON
|
||||
{
|
||||
"success": false,
|
||||
"message": "错误信息",
|
||||
"authURL": ""
|
||||
}
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
|
||||
### SSO 获取用户信息
|
||||
|
||||
该接口接受一个 code 参数作为鉴权,消费 code 返回用户信息。
|
||||
|
||||
{{< tabs tabTotal="2" >}}
|
||||
{{< tab tabName="请求示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```bash
|
||||
curl -X GET "https://oauth.example/login/oauth/getUserInfo?code=xxxxxx" \
|
||||
-H "Authorization: Bearer your_token_here" \
|
||||
-H "Content-Type: application/json"
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="响应示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
成功:
|
||||
```JSON
|
||||
{
|
||||
"success": true,
|
||||
"message": "",
|
||||
"username": "fastgpt-123456789",
|
||||
"avatar": "https://example.webp",
|
||||
"contact": "+861234567890",
|
||||
"memberName": "成员名(非必填)",
|
||||
}
|
||||
```
|
||||
|
||||
失败:
|
||||
```JSON
|
||||
{
|
||||
"success": false,
|
||||
"message": "错误信息",
|
||||
"username": "",
|
||||
"avatar": "",
|
||||
"contact": ""
|
||||
}
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
### 获取组织
|
||||
|
||||
{{< tabs tabTotal="2" >}}
|
||||
{{< tab tabName="请求示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```bash
|
||||
curl -X GET "https://example.com/org/list" \
|
||||
-H "Authorization: Bearer your_token_here" \
|
||||
-H "Content-Type: application/json"
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="响应示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
⚠️注意:只能存在一个根部门。如果你的系统中存在多个根部门,需要先进行处理,加一个虚拟的根部门。返回值类型:
|
||||
|
||||
```ts
|
||||
type OrgListResponseType = {
|
||||
message?: string; // 报错信息
|
||||
success: boolean;
|
||||
orgList: {
|
||||
id: string; // 部门的唯一 id
|
||||
name: string; // 名字
|
||||
parentId: string; // parentId,如果为根部门,传空字符串。
|
||||
}[];
|
||||
}
|
||||
```
|
||||
|
||||
```JSON
|
||||
{
|
||||
"success": true,
|
||||
"message": "",
|
||||
"orgList": [
|
||||
{
|
||||
"id": "od-125151515",
|
||||
"name": "根部门",
|
||||
"parentId": ""
|
||||
},
|
||||
{
|
||||
"id": "od-51516152",
|
||||
"name": "子部门",
|
||||
"parentId": "od-125151515"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
|
||||
### 获取成员
|
||||
|
||||
|
||||
{{< tabs tabTotal="2" >}}
|
||||
{{< tab tabName="请求示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
```bash
|
||||
curl -X GET "https://example.com/user/list" \
|
||||
-H "Authorization: Bearer your_token_here" \
|
||||
-H "Content-Type: application/json"
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
|
||||
{{< tab tabName="响应示例" >}}
|
||||
{{< markdownify >}}
|
||||
|
||||
返回值类型:
|
||||
|
||||
```typescript
|
||||
type UserListResponseListType = {
|
||||
message?: string; // 报错信息
|
||||
success: boolean;
|
||||
userList: {
|
||||
username: string; // 唯一 id username 必须与 SSO 接口返回的用户 username 相同。并且必须携带一个前缀,例如: sync-aaaaa,和 sso 接口返回的前缀一致
|
||||
memberName?: string; // 名字,作为 tmbname
|
||||
avatar?: string;
|
||||
contact?: string; // email or phone number
|
||||
orgs?: string[]; // 人员所在组织的 ID。没有组织传 []
|
||||
}[];
|
||||
}
|
||||
```
|
||||
curl示例
|
||||
|
||||
```JSON
|
||||
{
|
||||
"success": true,
|
||||
"message": "",
|
||||
"userList": [
|
||||
{
|
||||
"username": "fastgpt-123456789",
|
||||
"memberName": "张三",
|
||||
"avatar": "https://example.webp",
|
||||
"contact": "+861234567890",
|
||||
"orgs": ["od-125151515", "od-51516152"]
|
||||
},
|
||||
{
|
||||
"username": "fastgpt-12345678999",
|
||||
"memberName": "李四",
|
||||
"avatar": "",
|
||||
"contact": "",
|
||||
"orgs": ["od-125151515"]
|
||||
}
|
||||
]
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
{{< /markdownify >}}
|
||||
{{< /tab >}}
|
||||
{{< /tabs >}}
|
||||
|
||||
|
||||
|
||||
|
||||
## 如何对接非标准系统
|
||||
|
||||
1. 客户自己开发:按 fastgpt 提供的标准接口进行开发,并将部署后的服务地址填入 fastgpt-pro
|
||||
可以参考该模版库:[fastgpt-sso-template](https://github.com/labring/fastgpt-sso-template) 进行开发
|
||||
2. 由 fastgpt 团队定制开发:
|
||||
a. 提供系统的 SSO 文档、获取成员和组织的文档、以及外网测试地址。
|
||||
b. 在 fastgpt-sso-service 中,增加对应的 provider 和环境变量,并编写代码来对接。
|
||||
@@ -1,44 +0,0 @@
|
||||
---
|
||||
weight: 490
|
||||
title: '钉钉 SSO 配置'
|
||||
description: '钉钉 SSO 登录'
|
||||
icon: 'chat_bubble'
|
||||
draft: false
|
||||
images: []
|
||||
---
|
||||
|
||||
## 1. 注册钉钉应用
|
||||
|
||||
登录 [钉钉开放平台](https://open-dev.dingtalk.com/fe/app?hash=%23%2Fcorp%2Fapp#/corp/app),创建一个应用。
|
||||
|
||||

|
||||
|
||||
## 2. 配置钉钉应用安全设置
|
||||
|
||||
点击进入创建好的应用后,点开`安全设置`,配置出口 IP(服务器 IP),和重定向 URL。重定向 URL 填写逻辑:
|
||||
|
||||
`{{fastgpt 域名}}/login/provider`
|
||||
|
||||

|
||||
|
||||
## 3. 设置钉钉应用权限
|
||||
|
||||
点击进入创建好的应用后,点开`权限设置`,开放两个权限: `个人手机号信息`和`通讯录个人信息读权限`
|
||||
|
||||

|
||||
|
||||
## 4. 发布应用
|
||||
|
||||
点击进入创建好的应用后,点开`版本管理与发布`,随便创建一个新版本即可。
|
||||
|
||||
## 5. 在 FastGPT Admin 配置钉钉应用 id
|
||||
|
||||
名字都是对应上,直接填写即可。
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| |  |
|
||||
|
||||
## 6. 测试
|
||||
|
||||

|
||||
81
docSite/content/zh-cn/docs/guide/admin/teamMode.md
Normal file
@@ -0,0 +1,81 @@
|
||||
---
|
||||
title: '团队模式说明文档'
|
||||
description: 'FastGPT 团队模式说明文档'
|
||||
icon: ''
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 707
|
||||
---
|
||||
|
||||
## 介绍
|
||||
|
||||
目前支持的团队模式:
|
||||
|
||||
1. 多团队模式(默认模式)
|
||||
2. 单团队模式(全局只有一个团队)
|
||||
3. 成员同步模式(所有成员自外部同步)
|
||||
|
||||
<table class="table-hover table-striped-columns" style="text-align: center;">
|
||||
<tr>
|
||||
<th rowspan="2">团队模式</th>
|
||||
<th colspan="2">短信/邮箱 注册</th>
|
||||
<th colspan="2">管理员直接添加</th>
|
||||
<th colspan="2">SSO 注册</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>是否创建默认团队</th>
|
||||
<th>是否加入 Root 团队</th>
|
||||
<th>是否创建默认团队</th>
|
||||
<th>是否加入 Root 团队</th>
|
||||
<th>是否创建默认团队</th>
|
||||
<th>是否加入 Root 团队</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>单团队模式</td>
|
||||
<td>❌</td>
|
||||
<td>✅</td>
|
||||
<td>❌</td>
|
||||
<td>✅</td>
|
||||
<td>❌</td>
|
||||
<td>✅</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>多团队模式</td>
|
||||
<td>✅</td>
|
||||
<td>❌</td>
|
||||
<td>✅</td>
|
||||
<td>❌</td>
|
||||
<td>✅</td>
|
||||
<td>❌</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>同步模式</td>
|
||||
<td>❌</td>
|
||||
<td>❌</td>
|
||||
<td>❌</td>
|
||||
<td>✅</td>
|
||||
<td>❌</td>
|
||||
<td>✅</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
### 多团队模式(默认模式)
|
||||
|
||||
多团队模式下,每个用户创建时默认创建以自己为所有者的默认团队。
|
||||
|
||||
### 单团队模式
|
||||
|
||||
单团队模式是 v4.9 推出的新功能。为了简化企业进行人员和资源的管理,开启单团队模式后,所有新增的用户都不再创建自己的默认团队,而是加入 root 用户所在的团队。
|
||||
|
||||
### 同步模式
|
||||
|
||||
在完成系统配置,开启同步模式的情况下,外部成员系统的成员会自动同步到 FastGPT 中。
|
||||
|
||||
具体的同步方式和规则请参考 [SSO & 外部成员同步](/docs/guide/admin/sso.md)。
|
||||
|
||||
|
||||
## 配置
|
||||
|
||||
在 `fastgpt-pro` 的`系统配置-成员配置`中,可以配置团队模式。
|
||||
|
||||

|
||||
@@ -124,6 +124,7 @@ curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
|
||||
"success": true,
|
||||
"message": "",
|
||||
"data": {
|
||||
"title": "文档标题",
|
||||
"content": "FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!\n",
|
||||
"previewUrl": "xxxx"
|
||||
}
|
||||
@@ -131,10 +132,13 @@ curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
|
||||
```
|
||||
|
||||
{{% alert icon=" " context="success" %}}
|
||||
二选一返回,如果同时返回则 content 优先级更高。
|
||||
|
||||
- title - 文件标题。
|
||||
- content - 文件内容,直接拿来用。
|
||||
- previewUrl - 文件链接,系统会请求该地址获取文件内容。
|
||||
|
||||
`content`和`previewUrl`二选一返回,如果同时返回则 `content` 优先级更高,返回 `previewUrl`时,则会访问该链接进行文档内容读取。
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
{{< /markdownify >}}
|
||||
|
||||
@@ -0,0 +1,66 @@
|
||||
---
|
||||
title: "邀请链接说明文档"
|
||||
description: "如何使用邀请链接来邀请团队成员"
|
||||
icon: "group"
|
||||
draft: false
|
||||
toc: true
|
||||
weight: 451
|
||||
---
|
||||
|
||||
v4.9.1 团队邀请成员将开始使用「邀请链接」的模式,弃用之前输入用户名进行添加的形式。
|
||||
|
||||
在版本升级后,原收到邀请还未加入团队的成员,将自动清除邀请。请使用邀请链接重新邀请成员。
|
||||
|
||||
## 如何使用
|
||||
|
||||
1. **在团队管理页面,管理员可点击「邀请成员」按钮打开邀请成员弹窗**
|
||||
|
||||

|
||||
|
||||
2. **在邀请成员弹窗中,点击「创建邀请链接」按钮,创建邀请链接。**
|
||||
|
||||

|
||||
|
||||
3. **输入对应内容**
|
||||
|
||||

|
||||
|
||||
链接描述:建议将链接描述为使用场景或用途。链接创建后不支持修改噢。
|
||||
|
||||
有效期:30分钟,7天,1年
|
||||
|
||||
有效人数:1人,无限制
|
||||
|
||||
4. **点击复制链接,并将其发送给想要邀请的人。**
|
||||
|
||||

|
||||
|
||||
5. **用户访问链接后,如果未登录/未注册,则先跳转到登录页面进行登录。在登录后将进入团队页面,处理邀请。**
|
||||
|
||||
> 邀请链接形如:fastgpt.cn/account/team?invitelinkid=xxxx
|
||||
|
||||

|
||||
|
||||
点击接受,则用户将加入团队
|
||||
|
||||
点击忽略,则关闭弹窗,用户下次访问该邀请链接则还可以选择加入。
|
||||
|
||||
## 链接失效和自动清理
|
||||
|
||||
### 链接失效原因
|
||||
|
||||
手动停用链接
|
||||
|
||||
邀请链接到达有效期,自动停用
|
||||
|
||||
有效人数为1人的链接,已有1人通过邀请链接加入团队。
|
||||
|
||||
停用的链接无法访问,也无法再次启用。
|
||||
|
||||
### 链接上限
|
||||
|
||||
一个用户最多可以同时存在 10 个**有效的**邀请链接。
|
||||
|
||||
### 链接自动清理
|
||||
|
||||
失效的链接将在 30 天后自动清理。
|
||||
@@ -7,7 +7,7 @@ toc: true
|
||||
weight: -10
|
||||
---
|
||||
|
||||
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
|
||||
FastGPT 是一个AI Agent 构建平台,提供开箱即用的数据处理、模型调用等能力,同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的应用场景!
|
||||
|
||||
{{% alert icon="🤖 " context="success" %}}
|
||||
FastGPT 在线使用:[https://tryfastgpt.ai](https://tryfastgpt.ai)
|
||||
|
||||
40
env.d.ts
vendored
Normal file
@@ -0,0 +1,40 @@
|
||||
declare global {
|
||||
namespace NodeJS {
|
||||
interface ProcessEnv {
|
||||
LOG_DEPTH: string;
|
||||
DEFAULT_ROOT_PSW: string;
|
||||
DB_MAX_LINK: string;
|
||||
TOKEN_KEY: string;
|
||||
FILE_TOKEN_KEY: string;
|
||||
ROOT_KEY: string;
|
||||
OPENAI_BASE_URL: string;
|
||||
CHAT_API_KEY: string;
|
||||
AIPROXY_API_ENDPOINT: string;
|
||||
AIPROXY_API_TOKEN: string;
|
||||
MULTIPLE_DATA_TO_BASE64: string;
|
||||
MONGODB_URI: string;
|
||||
MONGODB_LOG_URI?: string;
|
||||
PG_URL: string;
|
||||
OCEANBASE_URL: string;
|
||||
MILVUS_ADDRESS: string;
|
||||
MILVUS_TOKEN: string;
|
||||
SANDBOX_URL: string;
|
||||
PRO_URL: string;
|
||||
FE_DOMAIN: string;
|
||||
FILE_DOMAIN: string;
|
||||
NEXT_PUBLIC_BASE_URL: string;
|
||||
LOG_LEVEL: string;
|
||||
STORE_LOG_LEVEL: string;
|
||||
USE_IP_LIMIT: string;
|
||||
WORKFLOW_MAX_RUN_TIMES: string;
|
||||
WORKFLOW_MAX_LOOP_TIMES: string;
|
||||
CHECK_INTERNAL_IP: string;
|
||||
CHAT_LOG_URL: string;
|
||||
CHAT_LOG_INTERVAL: string;
|
||||
CHAT_LOG_SOURCE_ID_PREFIX: string;
|
||||
ALLOWED_ORIGINS: string;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
export {};
|
||||
12
package.json
@@ -12,27 +12,29 @@
|
||||
"previewIcon": "node ./scripts/icon/index.js",
|
||||
"api:gen": "tsc ./scripts/openapi/index.ts && node ./scripts/openapi/index.js && npx @redocly/cli build-docs ./scripts/openapi/openapi.json -o ./projects/app/public/openapi/index.html",
|
||||
"create:i18n": "node ./scripts/i18n/index.js",
|
||||
"test": "vitest run --exclude 'test/cases/spec'",
|
||||
"test:all": "vitest run",
|
||||
"test": "vitest run",
|
||||
"test:workflow": "vitest run workflow"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@chakra-ui/cli": "^2.4.1",
|
||||
"@vitest/coverage-v8": "^3.0.2",
|
||||
"@vitest/coverage-v8": "^3.0.9",
|
||||
"husky": "^8.0.3",
|
||||
"i18next": "23.16.8",
|
||||
"lint-staged": "^13.3.0",
|
||||
"next-i18next": "15.4.2",
|
||||
"prettier": "3.2.4",
|
||||
"react-i18next": "14.1.2",
|
||||
"vitest": "^3.0.2",
|
||||
"vitest-mongodb": "^1.0.1",
|
||||
"vitest": "^3.0.9",
|
||||
"mongodb-memory-server": "^10.1.4",
|
||||
"zhlint": "^0.7.4"
|
||||
},
|
||||
"lint-staged": {
|
||||
"./**/**/*.{ts,tsx,scss}": "npm run format-code",
|
||||
"./docSite/**/**/*.md": "npm run format-doc"
|
||||
},
|
||||
"resolutions": {
|
||||
"mdast-util-gfm-autolink-literal": "2.0.0"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=18.16.0",
|
||||
"pnpm": ">=9.0.0"
|
||||
|
||||
@@ -1,3 +1,8 @@
|
||||
export type GetPathProps = {
|
||||
sourceId?: ParentIdType;
|
||||
type: 'current' | 'parent';
|
||||
};
|
||||
|
||||
export type ParentTreePathItemType = {
|
||||
parentId: string;
|
||||
parentName: string;
|
||||
|
||||
@@ -1,16 +1,17 @@
|
||||
import { defaultMaxChunkSize } from '../../core/dataset/training/utils';
|
||||
import { getErrText } from '../error/utils';
|
||||
import { replaceRegChars } from './tools';
|
||||
|
||||
export const CUSTOM_SPLIT_SIGN = '-----CUSTOM_SPLIT_SIGN-----';
|
||||
|
||||
type SplitProps = {
|
||||
text: string;
|
||||
chunkLen: number;
|
||||
chunkSize: number;
|
||||
maxSize?: number;
|
||||
overlapRatio?: number;
|
||||
customReg?: string[];
|
||||
};
|
||||
export type TextSplitProps = Omit<SplitProps, 'text' | 'chunkLen'> & {
|
||||
chunkLen?: number;
|
||||
export type TextSplitProps = Omit<SplitProps, 'text' | 'chunkSize'> & {
|
||||
chunkSize?: number;
|
||||
};
|
||||
|
||||
type SplitResponse = {
|
||||
@@ -56,7 +57,7 @@ const strIsMdTable = (str: string) => {
|
||||
return true;
|
||||
};
|
||||
const markdownTableSplit = (props: SplitProps): SplitResponse => {
|
||||
let { text = '', chunkLen } = props;
|
||||
let { text = '', chunkSize } = props;
|
||||
const splitText2Lines = text.split('\n');
|
||||
const header = splitText2Lines[0];
|
||||
const headerSize = header.split('|').length - 2;
|
||||
@@ -72,7 +73,7 @@ ${mdSplitString}
|
||||
`;
|
||||
|
||||
for (let i = 2; i < splitText2Lines.length; i++) {
|
||||
if (chunk.length + splitText2Lines[i].length > chunkLen * 1.2) {
|
||||
if (chunk.length + splitText2Lines[i].length > chunkSize * 1.2) {
|
||||
chunks.push(chunk);
|
||||
chunk = `${header}
|
||||
${mdSplitString}
|
||||
@@ -99,11 +100,17 @@ ${mdSplitString}
|
||||
5. 标点分割:重叠
|
||||
*/
|
||||
const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
let { text = '', chunkLen, overlapRatio = 0.15, customReg = [] } = props;
|
||||
let {
|
||||
text = '',
|
||||
chunkSize,
|
||||
maxSize = defaultMaxChunkSize,
|
||||
overlapRatio = 0.15,
|
||||
customReg = []
|
||||
} = props;
|
||||
|
||||
const splitMarker = 'SPLIT_HERE_SPLIT_HERE';
|
||||
const codeBlockMarker = 'CODE_BLOCK_LINE_MARKER';
|
||||
const overlapLen = Math.round(chunkLen * overlapRatio);
|
||||
const overlapLen = Math.round(chunkSize * overlapRatio);
|
||||
|
||||
// replace code block all \n to codeBlockMarker
|
||||
text = text.replace(/(```[\s\S]*?```|~~~[\s\S]*?~~~)/g, function (match) {
|
||||
@@ -115,34 +122,38 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
// The larger maxLen is, the next sentence is less likely to trigger splitting
|
||||
const markdownIndex = 4;
|
||||
const forbidOverlapIndex = 8;
|
||||
const stepReges: { reg: RegExp; maxLen: number }[] = [
|
||||
...customReg.map((text) => ({
|
||||
reg: new RegExp(`(${replaceRegChars(text)})`, 'g'),
|
||||
maxLen: chunkLen * 1.4
|
||||
})),
|
||||
{ reg: /^(#\s[^\n]+\n)/gm, maxLen: chunkLen * 1.2 },
|
||||
{ reg: /^(##\s[^\n]+\n)/gm, maxLen: chunkLen * 1.4 },
|
||||
{ reg: /^(###\s[^\n]+\n)/gm, maxLen: chunkLen * 1.6 },
|
||||
{ reg: /^(####\s[^\n]+\n)/gm, maxLen: chunkLen * 1.8 },
|
||||
{ reg: /^(#####\s[^\n]+\n)/gm, maxLen: chunkLen * 1.8 },
|
||||
|
||||
{ reg: /([\n]([`~]))/g, maxLen: chunkLen * 4 }, // code block
|
||||
{ reg: /([\n](?=\s*[0-9]+\.))/g, maxLen: chunkLen * 2 }, // 增大块,尽可能保证它是一个完整的段落。 (?![\*\-|>`0-9]): markdown special char
|
||||
{ reg: /(\n{2,})/g, maxLen: chunkLen * 1.6 },
|
||||
{ reg: /([\n])/g, maxLen: chunkLen * 1.2 },
|
||||
const stepReges: { reg: RegExp | string; maxLen: number }[] = [
|
||||
...customReg.map((text) => ({
|
||||
reg: text.replaceAll('\\n', '\n'),
|
||||
maxLen: chunkSize
|
||||
})),
|
||||
{ reg: /^(#\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(##\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(###\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(####\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
{ reg: /^(#####\s[^\n]+\n)/gm, maxLen: chunkSize },
|
||||
|
||||
{ reg: /([\n](```[\s\S]*?```|~~~[\s\S]*?~~~))/g, maxLen: maxSize }, // code block
|
||||
{
|
||||
reg: /(\n\|(?:(?:[^\n|]+\|){1,})\n\|(?:[:\-\s]+\|){1,}\n(?:\|(?:[^\n|]+\|)*\n)*)/g,
|
||||
maxLen: maxSize
|
||||
}, // Table 尽可能保证完整性
|
||||
{ reg: /(\n{2,})/g, maxLen: chunkSize },
|
||||
{ reg: /([\n])/g, maxLen: chunkSize },
|
||||
// ------ There's no overlap on the top
|
||||
{ reg: /([。]|([a-zA-Z])\.\s)/g, maxLen: chunkLen * 1.2 },
|
||||
{ reg: /([!]|!\s)/g, maxLen: chunkLen * 1.2 },
|
||||
{ reg: /([?]|\?\s)/g, maxLen: chunkLen * 1.4 },
|
||||
{ reg: /([;]|;\s)/g, maxLen: chunkLen * 1.6 },
|
||||
{ reg: /([,]|,\s)/g, maxLen: chunkLen * 2 }
|
||||
{ reg: /([。]|([a-zA-Z])\.\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([!]|!\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([?]|\?\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([;]|;\s)/g, maxLen: chunkSize },
|
||||
{ reg: /([,]|,\s)/g, maxLen: chunkSize }
|
||||
];
|
||||
|
||||
const customRegLen = customReg.length;
|
||||
const checkIsCustomStep = (step: number) => step < customRegLen;
|
||||
const checkIsMarkdownSplit = (step: number) =>
|
||||
step >= customRegLen && step <= markdownIndex + customRegLen;
|
||||
+customReg.length;
|
||||
|
||||
const checkForbidOverlap = (step: number) => step <= forbidOverlapIndex + customRegLen;
|
||||
|
||||
// if use markdown title split, Separate record title
|
||||
@@ -151,7 +162,8 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
return [
|
||||
{
|
||||
text,
|
||||
title: ''
|
||||
title: '',
|
||||
chunkMaxSize: chunkSize
|
||||
}
|
||||
];
|
||||
}
|
||||
@@ -159,27 +171,46 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
const isCustomStep = checkIsCustomStep(step);
|
||||
const isMarkdownSplit = checkIsMarkdownSplit(step);
|
||||
|
||||
const { reg } = stepReges[step];
|
||||
const { reg, maxLen } = stepReges[step];
|
||||
|
||||
const splitTexts = text
|
||||
.replace(
|
||||
const replaceText = (() => {
|
||||
if (typeof reg === 'string') {
|
||||
let tmpText = text;
|
||||
reg.split('|').forEach((itemReg) => {
|
||||
tmpText = tmpText.replaceAll(
|
||||
itemReg,
|
||||
(() => {
|
||||
if (isCustomStep) return splitMarker;
|
||||
if (isMarkdownSplit) return `${splitMarker}$1`;
|
||||
return `$1${splitMarker}`;
|
||||
})()
|
||||
);
|
||||
});
|
||||
return tmpText;
|
||||
}
|
||||
|
||||
return text.replace(
|
||||
reg,
|
||||
(() => {
|
||||
if (isCustomStep) return splitMarker;
|
||||
if (isMarkdownSplit) return `${splitMarker}$1`;
|
||||
return `$1${splitMarker}`;
|
||||
})()
|
||||
)
|
||||
.split(`${splitMarker}`)
|
||||
.filter((part) => part.trim());
|
||||
);
|
||||
})();
|
||||
|
||||
const splitTexts = replaceText.split(splitMarker).filter((part) => part.trim());
|
||||
|
||||
return splitTexts
|
||||
.map((text) => {
|
||||
const matchTitle = isMarkdownSplit ? text.match(reg)?.[0] || '' : '';
|
||||
// 如果一个分块没有匹配到,则使用默认块大小,否则使用最大块大小
|
||||
const chunkMaxSize = text.match(reg) === null ? chunkSize : maxLen;
|
||||
|
||||
return {
|
||||
text: isMarkdownSplit ? text.replace(matchTitle, '') : text,
|
||||
title: matchTitle
|
||||
title: matchTitle,
|
||||
chunkMaxSize
|
||||
};
|
||||
})
|
||||
.filter((item) => !!item.title || !!item.text?.trim());
|
||||
@@ -188,7 +219,7 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
/* Gets the overlap at the end of a text as the beginning of the next block */
|
||||
const getOneTextOverlapText = ({ text, step }: { text: string; step: number }): string => {
|
||||
const forbidOverlap = checkForbidOverlap(step);
|
||||
const maxOverlapLen = chunkLen * 0.4;
|
||||
const maxOverlapLen = chunkSize * 0.4;
|
||||
|
||||
// step >= stepReges.length: Do not overlap incomplete sentences
|
||||
if (forbidOverlap || overlapLen === 0 || step >= stepReges.length) return '';
|
||||
@@ -229,15 +260,15 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
const isCustomStep = checkIsCustomStep(step);
|
||||
const forbidConcat = isCustomStep; // forbid=true时候,lastText肯定为空
|
||||
|
||||
// oversize
|
||||
// Over step
|
||||
if (step >= stepReges.length) {
|
||||
if (text.length < chunkLen * 3) {
|
||||
if (text.length < maxSize) {
|
||||
return [text];
|
||||
}
|
||||
// use slice-chunkLen to split text
|
||||
// use slice-chunkSize to split text
|
||||
const chunks: string[] = [];
|
||||
for (let i = 0; i < text.length; i += chunkLen - overlapLen) {
|
||||
chunks.push(text.slice(i, i + chunkLen));
|
||||
for (let i = 0; i < text.length; i += chunkSize - overlapLen) {
|
||||
chunks.push(text.slice(i, i + chunkSize));
|
||||
}
|
||||
return chunks;
|
||||
}
|
||||
@@ -245,19 +276,18 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
// split text by special char
|
||||
const splitTexts = getSplitTexts({ text, step });
|
||||
|
||||
const maxLen = splitTexts.length > 1 ? stepReges[step].maxLen : chunkLen;
|
||||
const minChunkLen = chunkLen * 0.7;
|
||||
|
||||
const chunks: string[] = [];
|
||||
for (let i = 0; i < splitTexts.length; i++) {
|
||||
const item = splitTexts[i];
|
||||
|
||||
const maxLen = item.chunkMaxSize; // 当前块最大长度
|
||||
|
||||
const lastTextLen = lastText.length;
|
||||
const currentText = item.text;
|
||||
const newText = lastText + currentText;
|
||||
const newTextLen = newText.length;
|
||||
|
||||
// Markdown 模式下,会强制向下拆分最小块,并再最后一个标题时候,给小块都补充上所有标题(包含父级标题)
|
||||
// Markdown 模式下,会强制向下拆分最小块,并再最后一个标题深度,给小块都补充上所有标题(包含父级标题)
|
||||
if (isMarkdownStep) {
|
||||
// split new Text, split chunks must will greater 1 (small lastText)
|
||||
const innerChunks = splitTextRecursively({
|
||||
@@ -267,11 +297,13 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
parentTitle: parentTitle + item.title
|
||||
});
|
||||
|
||||
// 只有标题,没有内容。
|
||||
if (innerChunks.length === 0) {
|
||||
chunks.push(`${parentTitle}${item.title}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
// 在合并最深级标题时,需要补充标题
|
||||
chunks.push(
|
||||
...innerChunks.map(
|
||||
(chunk) =>
|
||||
@@ -282,9 +314,18 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
continue;
|
||||
}
|
||||
|
||||
// newText is too large(now, The lastText must be smaller than chunkLen)
|
||||
// newText is too large(now, The lastText must be smaller than chunkSize)
|
||||
if (newTextLen > maxLen) {
|
||||
// lastText greater minChunkLen, direct push it to chunks, not add to next chunk. (large lastText)
|
||||
const minChunkLen = maxLen * 0.8; // 当前块最小长度
|
||||
const maxChunkLen = maxLen * 1.2; // 当前块最大长度
|
||||
|
||||
// 新文本没有非常大,直接认为它是一个新的块
|
||||
if (newTextLen < maxChunkLen) {
|
||||
chunks.push(newText);
|
||||
lastText = getOneTextOverlapText({ text: newText, step }); // next chunk will start with overlayText
|
||||
continue;
|
||||
}
|
||||
// 上一个文本块已经挺大的,单独做一个块
|
||||
if (lastTextLen > minChunkLen) {
|
||||
chunks.push(lastText);
|
||||
|
||||
@@ -294,13 +335,13 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
continue;
|
||||
}
|
||||
|
||||
// 说明是新的文本块比较大,需要进一步拆分
|
||||
// 说明是当前文本比较大,需要进一步拆分
|
||||
|
||||
// split new Text, split chunks must will greater 1 (small lastText)
|
||||
// 把新的文本块进行一个拆分,并追加到 latestText 中
|
||||
const innerChunks = splitTextRecursively({
|
||||
text: newText,
|
||||
text: currentText,
|
||||
step: step + 1,
|
||||
lastText: '',
|
||||
lastText,
|
||||
parentTitle: parentTitle + item.title
|
||||
});
|
||||
const lastChunk = innerChunks[innerChunks.length - 1];
|
||||
@@ -328,16 +369,16 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
|
||||
// Not overlap
|
||||
if (forbidConcat) {
|
||||
chunks.push(item.text);
|
||||
chunks.push(currentText);
|
||||
continue;
|
||||
}
|
||||
|
||||
lastText += item.text;
|
||||
lastText = newText;
|
||||
}
|
||||
|
||||
/* If the last chunk is independent, it needs to be push chunks. */
|
||||
if (lastText && chunks[chunks.length - 1] && !chunks[chunks.length - 1].endsWith(lastText)) {
|
||||
if (lastText.length < chunkLen * 0.4) {
|
||||
if (lastText.length < chunkSize * 0.4) {
|
||||
chunks[chunks.length - 1] = chunks[chunks.length - 1] + lastText;
|
||||
} else {
|
||||
chunks.push(lastText);
|
||||
@@ -371,9 +412,9 @@ const commonSplit = (props: SplitProps): SplitResponse => {
|
||||
|
||||
/**
|
||||
* text split into chunks
|
||||
* chunkLen - one chunk len. max: 3500
|
||||
* chunkSize - one chunk len. max: 3500
|
||||
* overlapLen - The size of the before and after Text
|
||||
* chunkLen > overlapLen
|
||||
* chunkSize > overlapLen
|
||||
* markdown
|
||||
*/
|
||||
export const splitText2Chunks = (props: SplitProps): SplitResponse => {
|
||||
|
||||
@@ -56,7 +56,7 @@ export const replaceSensitiveText = (text: string) => {
|
||||
};
|
||||
|
||||
/* Make sure the first letter is definitely lowercase */
|
||||
export const getNanoid = (size = 12) => {
|
||||
export const getNanoid = (size = 16) => {
|
||||
const firstChar = customAlphabet('abcdefghijklmnopqrstuvwxyz', 1)();
|
||||
|
||||
if (size === 1) return firstChar;
|
||||
|
||||
22
packages/global/common/system/types/index.d.ts
vendored
@@ -84,11 +84,6 @@ export type FastGPTFeConfigsType = {
|
||||
github?: string;
|
||||
google?: string;
|
||||
wechat?: string;
|
||||
dingtalk?: string;
|
||||
wecom?: {
|
||||
corpid?: string;
|
||||
agentid?: string;
|
||||
};
|
||||
microsoft?: {
|
||||
clientId?: string;
|
||||
tenantId?: string;
|
||||
@@ -117,17 +112,18 @@ export type SystemEnvType = {
|
||||
vectorMaxProcess: number;
|
||||
qaMaxProcess: number;
|
||||
vlmMaxProcess: number;
|
||||
pgHNSWEfSearch: number;
|
||||
hnswEfSearch: number;
|
||||
tokenWorkers: number; // token count max worker
|
||||
|
||||
oneapiUrl?: string;
|
||||
chatApiKey?: string;
|
||||
|
||||
customPdfParse?: {
|
||||
url?: string;
|
||||
key?: string;
|
||||
|
||||
doc2xKey?: string;
|
||||
price?: number; // n points/1 page
|
||||
};
|
||||
customPdfParse?: customPdfParseType;
|
||||
};
|
||||
|
||||
export type customPdfParseType = {
|
||||
url?: string;
|
||||
key?: string;
|
||||
doc2xKey?: string;
|
||||
price?: number;
|
||||
};
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
import { i18nT } from '../../../web/i18n/utils';
|
||||
|
||||
export enum ChatCompletionRequestMessageRoleEnum {
|
||||
'System' = 'system',
|
||||
'User' = 'user',
|
||||
@@ -28,3 +30,13 @@ export enum EmbeddingTypeEnm {
|
||||
query = 'query',
|
||||
db = 'db'
|
||||
}
|
||||
|
||||
export const completionFinishReasonMap = {
|
||||
close: i18nT('chat:completion_finish_close'),
|
||||
stop: i18nT('chat:completion_finish_stop'),
|
||||
length: i18nT('chat:completion_finish_length'),
|
||||
tool_calls: i18nT('chat:completion_finish_tool_calls'),
|
||||
content_filter: i18nT('chat:completion_finish_content_filter'),
|
||||
function_call: i18nT('chat:completion_finish_function_call'),
|
||||
null: i18nT('chat:completion_finish_null')
|
||||
};
|
||||
|
||||
@@ -1,54 +1,70 @@
|
||||
import { PromptTemplateItem } from '../type.d';
|
||||
import { i18nT } from '../../../../web/i18n/utils';
|
||||
import { getPromptByVersion } from './utils';
|
||||
|
||||
export const Prompt_QuoteTemplateList: PromptTemplateItem[] = [
|
||||
{
|
||||
title: i18nT('app:template.standard_template'),
|
||||
desc: i18nT('app:template.standard_template_des'),
|
||||
value: `{
|
||||
value: {
|
||||
['4.9.2']: `{
|
||||
"sourceName": "{{source}}",
|
||||
"updateTime": "{{updateTime}}",
|
||||
"content": "{{q}}\n{{a}}"
|
||||
}
|
||||
`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.qa_template'),
|
||||
desc: i18nT('app:template.qa_template_des'),
|
||||
value: `<Question>
|
||||
value: {
|
||||
['4.9.2']: `<Question>
|
||||
{{q}}
|
||||
</Question>
|
||||
<Answer>
|
||||
{{a}}
|
||||
</Answer>`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.standard_strict'),
|
||||
desc: i18nT('app:template.standard_strict_des'),
|
||||
value: `{
|
||||
value: {
|
||||
['4.9.2']: `{
|
||||
"sourceName": "{{source}}",
|
||||
"updateTime": "{{updateTime}}",
|
||||
"content": "{{q}}\n{{a}}"
|
||||
}
|
||||
`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.hard_strict'),
|
||||
desc: i18nT('app:template.hard_strict_des'),
|
||||
value: `<Question>
|
||||
value: {
|
||||
['4.9.2']: `<Question>
|
||||
{{q}}
|
||||
</Question>
|
||||
<Answer>
|
||||
{{a}}
|
||||
</Answer>`
|
||||
}
|
||||
}
|
||||
];
|
||||
|
||||
export const getQuoteTemplate = (version?: string) => {
|
||||
const defaultTemplate = Prompt_QuoteTemplateList[0].value;
|
||||
|
||||
return getPromptByVersion(version, defaultTemplate);
|
||||
};
|
||||
|
||||
export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
{
|
||||
title: i18nT('app:template.standard_template'),
|
||||
desc: '',
|
||||
value: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: {
|
||||
['4.9.2']: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -62,11 +78,13 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 使用与问题相同的语言回答。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.qa_template'),
|
||||
desc: '',
|
||||
value: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: {
|
||||
['4.9.2']: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -79,11 +97,13 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.standard_strict'),
|
||||
desc: '',
|
||||
value: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -101,11 +121,13 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 使用与问题相同的语言回答。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.hard_strict'),
|
||||
desc: '',
|
||||
value: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -126,6 +148,7 @@ export const Prompt_userQuotePromptList: PromptTemplateItem[] = [
|
||||
- 使用与问题相同的语言回答。
|
||||
|
||||
问题:"""{{question}}"""`
|
||||
}
|
||||
}
|
||||
];
|
||||
|
||||
@@ -133,7 +156,8 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
{
|
||||
title: i18nT('app:template.standard_template'),
|
||||
desc: '',
|
||||
value: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: {
|
||||
['4.9.2']: `使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -145,11 +169,13 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 保持答案与 <Reference></Reference> 中描述的一致。
|
||||
- 使用 Markdown 语法优化回答格式。
|
||||
- 使用与问题相同的语言回答。`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.qa_template'),
|
||||
desc: '',
|
||||
value: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: {
|
||||
['4.9.2']: `使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -160,11 +186,13 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 回答的内容应尽可能与 <答案></答案> 中的内容一致。
|
||||
- 如果没有相关的问答对,你需要澄清。
|
||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.standard_strict'),
|
||||
desc: '',
|
||||
value: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <Reference></Reference> 标记中的内容作为本次对话的参考:
|
||||
|
||||
<Reference>
|
||||
{{quote}}
|
||||
@@ -180,11 +208,13 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 保持答案与 <Reference></Reference> 中描述的一致。
|
||||
- 使用 Markdown 语法优化回答格式。
|
||||
- 使用与问题相同的语言回答。`
|
||||
}
|
||||
},
|
||||
{
|
||||
title: i18nT('app:template.hard_strict'),
|
||||
desc: '',
|
||||
value: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
value: {
|
||||
['4.9.2']: `忘记你已有的知识,仅使用 <QA></QA> 标记中的问答对进行回答。
|
||||
|
||||
<QA>
|
||||
{{quote}}
|
||||
@@ -203,12 +233,28 @@ export const Prompt_systemQuotePromptList: PromptTemplateItem[] = [
|
||||
- 避免提及你是从 QA 获取的知识,只需要回复答案。
|
||||
- 使用 Markdown 语法优化回答格式。
|
||||
- 使用与问题相同的语言回答。`
|
||||
}
|
||||
}
|
||||
];
|
||||
|
||||
export const getQuotePrompt = (version?: string, role: 'user' | 'system' = 'user') => {
|
||||
const quotePromptTemplates =
|
||||
role === 'user' ? Prompt_userQuotePromptList : Prompt_systemQuotePromptList;
|
||||
|
||||
const defaultTemplate = quotePromptTemplates[0].value;
|
||||
|
||||
return getPromptByVersion(version, defaultTemplate);
|
||||
};
|
||||
|
||||
// Document quote prompt
|
||||
export const Prompt_DocumentQuote = `将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
|
||||
<FilesContent>
|
||||
{{quote}}
|
||||
</FilesContent>
|
||||
`;
|
||||
export const getDocumentQuotePrompt = (version: string) => {
|
||||
const promptMap = {
|
||||
['4.9.2']: `将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
|
||||
<FilesContent>
|
||||
{{quote}}
|
||||
</FilesContent>
|
||||
`
|
||||
};
|
||||
|
||||
return getPromptByVersion(version, promptMap);
|
||||
};
|
||||
|
||||